Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/en_adst_11_computer-programming_elab.pdf---
AP Physics
This course can help prepare students who wish to continue their social sciences education after high school, as well as students who wish to perform exceptionally well on the SAT exam. The level of aptitude in this subject will assist students wishing to excel on the SAT and in college courses.
AP Physics is a course designed to provide a systematic introduction to the main principles of Physics. It will help students gain a conceptual understanding of different subject matter as well as develop problem solving skills using Algebra and Trigonometry. Most colleges treat Physics as a full year course, so the course load might be more extensive than other AP classes. Students in other majors may use an AP Physics course to bypass taking other science classes while enrolled in college. Before taking an AP Physics class, students should have a firm grasp of mathematical terms and functions. It is recommended that students take at least one Algebra class and have some experience dealing with trigonometry.
AP Physics includes two, separate examinations that are offered as part of the College Board's Advanced Placement Program.
AP Physics B is a science course that is separated into five different sections of study: Newtonian Mechanics, Electricity and Magnetism, Fluid Mechanics and Thermal Physics, Waves and Optics, and Atomic and Nuclear Physics.
AP Physics C focuses on Newtonian Mechanics, Electricity and Magnetism. Use of calculus in problem solving and in derivations is expected.
According to the College Board’s website, AP Physics focuses primarily on four areas of study with their AP Physics coursework. These four areas are:
- Physics knowledge: Students will acquire basic knowledge of the discipline of physics, including phenomena, theories and techniques, concepts, and general principles.
- Physics Problem Solving: Students will gain the ability to ask physical questions and to obtain solutions to physical questions as well through the use of qualitative and quantitative reasoning and by experimental investigation.
- Student Attributes: Fostering of important student attributes, including appreciation of the physical world and the discipline of physics, curiosity, creativity, and reasoned skepticism.
- Connections: Students will begin understanding connections between physics and other disciplines and to societal issues as well.
Students will also:
- Work heavily with math (arithmetic, algebra, geometry, and trigonometry) in connection to the laws of physics, solving problems through the use of equations and the scientific process.
- Read, understand, and explain the sequence of steps in the analysis of a particular physical phenomena or problem, interpreting results and conclusions and discussing particular cases of interest.
- Students will work on being able to design experiments; observe and measure real phenomena; organize, display, and critically analyze data; draw inferences from observed data; communicate results, including suggested ways to improve experiments and proposed questions for further study.
- Students will become more comfortable using study notes as well as other study techniques in conjunction with the use of various textbooks such as Physics: Principles with Application and College Physics.
Students considering taking AP Economics or any other AP course should recognize that taking an advanced college course will require more time and effort than the average high school class. Students that are willing to put in the proper amount of effort into their classes, however, will see a definite payoff in their GPA, exam scores, and preparedness for college. Not only do Advanced Placement courses look excellent on high school transcripts, they will also help student to develop strong study skills and time management habits.
Students that wish to take an AP course should visit with their counselor for more information about what course will suit them and what certain courses require. Students might also want to consider taking a look at certain courses’ syllabi to make sure that they will be able to devote the proper amount of time to the course’s workload. The sooner a student chooses to make the most of their education, the sooner they will see the rewards!
You will find a variety of different Physics resources here including Physics notes and outlines. We will be adding vocabulary, formulas, practice quizzes, free reponse questions, and other physics study guides to the site shortly.
Subject:
Subject X2:
Premium Content
-
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/li_gong_zu_.pdf---
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/ap-phys1_momentum-multiple-choice_2016-11-16.docx---
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/collegephysics-ismch10.docx---
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/collegephysics-ismch09.docx---
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/collegephysics-ismch04.docx---
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/collegephysics-ismch06.docx---
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/collegephysics-ismch08.docx---
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/collegephysics-ismch05.docx---
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/collegephysics-ismch07.docx---
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/collegephysics-ismch02_1.docx---
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/collegephysics-ismch01_1.docx---
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/collegephysics-ismch03.docx---
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/kinematics_cer_-_54009044.docx---
-
Text automatically extracted from attachment below. Please download attachment to view properly formatted document.---Extracted text from uploads/physics/univgrav_ws.pdf---
Subject:
Subject X2:
Physics Notes
Here you will find AP Physics notes that cover both the AP Physics B and AP Physics C exam. The AP Physics Outlines are split up by category with subtopics underneath. These AP Phsyics outlines will help you prepare for the AP Physics exam.
Subject:
Subject X2:
DC Circuits
Subject:
Subject X2:
Capacitors, Batteries, and Current
Capacitors: devices for storing charge
A capacitor is a device for storing charge. It is usually made up of two plates separated by a thin insulating material known as the dielectric. One plate of the capacitor is positively charged, while the other has negative charge.
The charge stored in a capacitor is proportional to the potential difference between the two plates. For a capacitor with charge Q on the positive plate and -Q on the negative plate, the charge is proportional to the potential:
If C is the capacitance, Q = CV
The capacitance is a measure of the amount of charge a capacitor can store; this is determined by the capacitor geometry and by the kind of dielectric between the plates. For a parallel plate capacitor made up of two plates of area A and separated by a distance d, with no dielectric material, the capacitance is given by :
![]()
Note that capacitance has units of farads (F). A 1 F capacitor is
exceptionally large; typical capacitors have capacitances in the pF -
microfarad range.
Dielectrics, insulating materials placed between the plates of
a capacitor, cause the electric field inside the capacitor to be
reduced for the same amount of charge on the plates. This is because
the molecules of the dielectric material get polarized in the field,
and they align themselves in a way that sets up another field inside
the dielectric opposite to the field from the capacitor plates. The
dielectric constant is the ratio of the electric field without the
dielectric to the field with the dielectric:
![]()

Note that for a set of parallel plates, the electric field between
the plates is related to the potential difference by the equation:
for a parallel-plate capacitor: E = V / d
For a given potential difference (i.e., for a given voltage),
the higher the dielectric constant, the more charge can be stored in
the capacitor. For a parallel-plate capacitor with a dielectric between
the plates, the capacitance is:
![]()
Energy stored in a capacitor
The energy stored in a capacitor is the same as the work needed to build up the charge on the plates. As the charge increases, the harder it is to add more. Potential energy is the charge multiplied by the potential, and as the charge builds up the potential does too. If the potential difference between the two plates is V at the end of the process, and 0 at the start, the average potential is V / 2. Multiplying this average potential by the charge gives the potential energy : PE = 1/2 Q V.
Substituting in for Q, Q = CV, gives:
The energy stored in a capacitor is: U = 1/2 C V2
Capacitors have a variety of uses because there are many applications that involve storing charge. A good example is computer memory, but capacitors are found in all sorts of electrical circuits, and are often used to minimize voltage fluctuations. Another application is a flash bulb for a camera, which requires a lot of charge to be transferred in a short time. Batteries are good at providing a small amount of charge for a long time, so charge is transferred slowly from a battery to a capacitor. The capacitor is discharged quickly through a flash bulb, lighting the bulb brightly for a short time.
If the distance between the plates of a capacitor is changed, the capacitance is changed. For a charged capacitor, a change in capacitance correspond to a change in voltage, which is easily measured. This is exploited in applications ranging from certain microphones to the the keys in some computer keyboards.
Playing with a capacitor
To help understand how a capacitor works, we can experiment using a power supply, a capacitor, and a piece of dielectric material. The power supply provides the voltage, or potential difference, that causes charge to build up on the capacitor plates.
With the power supply connected to the capacitor, a constant difference in potential is maintained between the two plates. This results in a certain amount of charge moving on to the plates from the power supply, and there is a particular electric field between the plates. When some dielectric material is inserted between the plates, the field can not change because the potential difference is constant, and E = V / d. To ensure that the field does not change, charge flows from the power supply to the plates of the capacitor. Removing the dielectric causes the charge to flow back to the power supply, keeping the field constant. To summarize, when the voltage is fixed but the capacitance changes, the amount of charge on the plates changes.
On the other hand, if the power supply is connected to the capacitor briefly and then removed, it will be the charge that stays constant. If a dielectric material is inserted between the plates in this case, the field between the plates will be reduced, as will the potential difference. Removing the dielectric increases the field, and therefore increases the voltage.
Electric fields and potentials in the human body
The body is full of electrical impulses, and we can measure these signals using electrodes placed on the skin. The rhythmic contractions of the heart, for example, are caused by carefully timed electrical impulses. These can be measured with an electrocardiogram (ECG or EKG). If the heart is malfunctioning, this will usually produce a change in the electrical activity of the heart, with particular changes corresponding to particular problems. Similar analysis can be done on the brain using an electroencephalogram (EEG).
Batteries and EMF
Capacitors are very good at storing charge for short time periods, and they can be charged and recharged very quickly. There are many applications, however, where it's more convenient to have a slow-but-steady flow of charge; for these applications batteries are used.
A battery is another device for storing charge (or, put another way, for storing electrical energy). A battery consists of two electrodes, the anode (negative) and cathode (positive. Usually these are two dissimilar metals such as copper and zinc. These are immersed in a solution (sometimes an acid solution). A chemical reaction results in a potential difference between the two terminals.
When the battery is connected to a circuit, electrons produced by the chemical reaction at the anode flow through the circuit to the cathode. At the cathode, the electrons are consumed in another chemical reaction. The circuit is completed by positive ions (H+, in many cases) flowing through the solution in the battery from the anode to the cathode.
The voltage of a battery is also known as the emf, the electromotive force. This emf can be thought of as the pressure that causes charges to flow through a circuit the battery is part of. This flow of charge is very similar to the flow of other things, such as heat or water.
A flow of charge is known as a current. Batteries put out direct current, as opposed to alternating current, which is what comes out of a wall socket. With direct current, the charge flows only in one direction. With alternating current, the charges slosh back and forth, continually reversing direction.
Current and Drift velocity
An electric current, which is a flow of charge, occurs when there is a potential difference. For a current to flow also requires a complete circuit, which means the flowing charge has to be able to get back to where it starts. Current (I) is measured in amperes (A), and is the amount of charge flowing per second.
current : I = q / t, with units of A = C / s
When current flows through wires in a circuit, the moving charges are electrons. For historical reasons, however, when analyzing circuits the direction of the current is taken to be the direction of the flow of positive charge, opposite to the direction the electrons go. We can blame Benjamin Franklin for this. It amounts to the same thing, because the flow of positive charge in one direction is equivalent to the flow of negative charge in the opposite direction.
When a battery or power supply sets up a difference in potential between two parts of a wire, an electric field is created and the electrons respond to that field. In a current-carrying conductor, however, the electrons do not all flow in the same direction. In fact, even when there is no potential difference (and therefore no field), the electrons are moving around randomly. This random motion continues when there is a field, but the field superimposes onto this random motion a small net velocity, the drift velocity. Because electrons are negative charges, the direction of the drift velocity is opposite to the electric field.
In a typical case, the drift velocity of electrons is about 1 mm / s. The electric field,on the other hand, propagates much faster than this, more like 108 m / s.
Subject:
Subject X2:
Kirchoff's Laws and Multi-loop Circuits
Multi-loop Circuits and Kirchoff's Rules
Before talking about what a multi-loop circuit is, it is helpful to define two terms, junction and branch.
A junction is a point where at least three circuit paths meet.
A branch is a path connecting two junctions.
In the circuit below, there are two junctions, labeled a and b. There are three branches: these are the three paths from a to b.

Multi-loop circuits
In a circuit involving one battery and a number of resistors in series and/or parallel, the resistors can generally be reduced to a single equivalent resistor. With more than one battery, the situation is trickier. If all the batteries are part of one branch they can be combined into a single equivalent battery. Generally, the batteries will be part of different branches, and another method has to be used to analyze the circuit to find the current in each branch. Circuits like this are known as multi-loop circuits.
Finding the current in all branches of a multi-loop circuit (or the emf of a battery or the value of a resistor) is done by following guidelines known as Kirchoff's rules. These guidelines also apply to very simple circuits.
Kirchoff's first rule : the junction rule. The sum of the currents coming in to a junction is equal to the sum leaving the junction. (Basically this is conservation of charge)
Kirchoff's second rule : the loop rule. The sum of all the potential differences around a complete loop is equal to zero. (Conservation of energy)
There are two different methods for analyzing circuits. The standard method in physics, which is the one followed by the textbook, is the branch current method. There is another method, the loop current method, but we won't worry about that one.
The branch current method
To analyze a circuit using the branch-current method involves three steps:
1. Label the current and the current direction in each branch. Sometimes it's hard to tell which is the correct direction for the current in a particular loop. That does NOT matter. Simply pick a direction. If you guess wrong, you¹ll get a negative value. The value is correct, and the negative sign means that the current direction is opposite to the way you guessed. You should use the negative sign in your calculations, however.
2. Use Kirchoff's first rule to write down current equations for each junction that gives you a different equation. For a circuit with two inner loops and two junctions, one current equation is enough because both junctions give you the same equation.
3. Use Kirchoff's second rule to write down loop equations for as many loops as it takes to include each branch at least once. To write down a loop equation, you choose a starting point, and then walk around the loop in one direction until you get back to the starting point. As you cross batteries and resistors, write down each voltage change. Add these voltage gains and losses up and set them equal to zero.
When you cross a battery from the - side to the + side, that's a positive change. Going the other way gives you a drop in potential, so that's a negative change.
When you cross a resistor in the same direction as the current, that's also a drop in potential so it's a negative change in potential. Crossing a resistor in the opposite direction as the current gives you a positive change in potential.
An example
Running through an example should help clarify how Kirchoff's rules are used. Consider the circuit below:

Step 1 of the branch current method has already been done. The
currents have been labeled in each branch of the circuit, and the
directions are shown with arrows. Again, you don't have to be sure of
these directions at this point. Simply choose directions, and if any of
the currents come out to have negative signs, all it means is that the
direction of that current is opposite to the way you've shown on your
diagram.
Applying step 2 of the branch current method means looking at
the junctions, and writing down a current equation. At junction a, the
total current coming in to the junction equals the total current
flowing away. This gives:
at junction a : I1 = I2 + I3
If we applied the junction rule at junction b, we'd get the same
equation. So, applying the junction rule at one of the junctions is all
we need to do. In some cases you will need to get equations from more
than one junction, but you'll never need to get an equation for every
junction.
There are three unknowns, the three currents, so we need to
have three equations. One came from the junction rule; the other two
come from going to step 3 and applying the loop rule. There are three
loops to use in this circuit: the inside loop on the left, the inside
loop on the right, and the loop that goes all the way around the
outside. We just need to write down loop equations until each branch
has been used at least once, though, so using any two of the three
loops in this case is sufficient.
When applying the loop equation, the first step is to choose a
starting point on one loop. Then walk around the loop, in either
direction, and write down the change in potential when you go through a
battery or resistor. When the potential increases, the change is
positive; when the potential decreases, the change is negative. When
you get back to your starting point, add up all the potential changes
and set this sum equal to zero, because the net change should be zero
when you get back to where you started.
When you pass through a battery from minus to plus, that's a
positive change in potential, equal to the emf of the battery. If you
go through from plus to minus, the change in potential is equal to
minus the emf of the battery.
Current flows from high to low potential through a resistor. If
you pass through a resistor in the same direction as the current, the
potential, given by IR, will decrease, so it will have a minus sign. If
you go through a resistor opposite to the direction of the current,
you're going from lower to higher potential, and the IR change in
potential has a plus sign.
Keeping all this in mind, let's write down the loop equation
for the inside loop on the left side. Picking a starting point as the
bottom left corner, and moving clockwise around the loop gives:

Make sure you match the current to the resistor; there is one
current for each branch, and a loop has at least two branches in it.
The inner loop on the right side can be used to get the second
loop equation. Starting in the bottom right corner and going
counter-clockwise gives:
![]()
Plugging in the values for the resistances and battery emf's gives, for the three equations:

The simplest way to solve this is to look at which variable shows up
in both loop equations (equations 2 and 3), solve for that variable in
equation 1, and substitute it in in equations 2 and 3.
Rearranging equation 1 gives:
![]()
Substituting this into equation 2 gives:
![]()
Making the same substitution into equation 3 gives:
![]()
This set of two equations in two unknowns can be reduced to one
equation in one unknown by multiplying equation 4 by 5 (the number 5,
not equation 5!) and adding the result to equation 5.

Substituting this into equation 5 gives:
I2 = ( -4 + 1.5 ) / 5 = -0.5 A
The negative sign means that the current is 0.5 A in the
direction opposite to that shown on the diagram. Solving for the
current in the middle branch from equation 1 gives:
I3 = 1.5 - (-0.5) = 2.0 A
An excellent way to check your answer is to go back and label
the voltage at each point in the circuit. If everything is consistent,
your answer is fine. To label the voltage, the simplest thing to do is
choose one point to be zero volts. It's just the difference in
potential between points that matters, so you can define one point to
be whatever potential you think is convenient, and use that as your
reference point. My habit is to set the negative side of one of the
batteries to zero volts, and measure everything else with respect to
that.

In this example circuit, when the potential at all the points is labeled, everything is consistent. What this means is that when you go from junction b to junction a by any route, and figure out what the potential at a is, you get the same answer for each route. If you got different answers, that would be a big hint that you did something wrong in solving for the currents. Note also that you have to account for any of the currents coming out to be negative, and going the opposite way from what you had originally drawn.
One final note: you can use this method of circuit analysis to solve for more things than just the current. If one or more of the currents was known (maybe the circuit has an ammeter or two, measuring the current magnitude and direction in one or two branches) then an unknown battery emf or an unknown resistance could be found instead.
Meters
It is often useful to measure the voltage or current in a circuit. A voltmeter is a device used to measure voltage, while a meter measuring current is an ammeter. Meters are either analog or digital devices. Analog meters show the output on a scale with a needle, while digital devices produce a digital readout. Analog voltmeters and ammeters are both based on a device called a galvanometer. Because this is a magnetic device, we'll come back to that in the next chapter. Digital voltmeters and ammeters generally rely on measuring the voltage across a known resistor, and converting that voltage to a digital value for display.
Voltmeters

Resistors in parallel have the same voltage across them, so if you want to measure the voltage across a circuit element like a resistor, you place the voltmeter in parallel with the resistor. The voltmeter is shown in the circuit diagram as a V in a circle, and it acts as another resistor. To prevent the voltmeter from changing the current in the circuit (and therefore the voltage across the resistor), the voltmeter must have a resistance much larger than the resistor's. With a large voltmeter resistance, hardly any of the current in the circuit makes a detour through the meter.
Ammeters

Remember that resistors in series have the same current flowing through them. An ammeter, then, must be placed in series with a resistor to measure the current through the resistor. On a circuit diagram, an ammeter is shown as an A in a circle. Again, the ammeter acts as a resistor, so to minimize its impact on the circuit it must have a small resistance relative to the resistance of the resitor whose current is being measured.
RC Circuits
Resistors are relatively simple circuit elements. When a resistor or a set of resistors is connected to a voltage source, the current is constant. If a capacitor is added to the circuit, the situation changes. In a simple series circuit, with a battery, resistor, and capacitor in series, the current will follow an exponential decay. The time it takes to decay is determined by the resistance (R) and capacitance (C) in the circuit.

A capacitor is a device for storing charge. In some sense, a
capacitor acts like a temporary battery. When a capacitor is connected
through a resistor to a battery, charge from the battery is stored in
the capacitor. This causes a potential difference to build up across
the capacitor, which opposes the potential difference of the battery.
As this potential difference builds, the current in the circuit
decreases.
If the capacitor is connected to a battery with a voltage of
Vo, the voltage across the capacitor varies with time according to the
equation:
![]()
The current in the circuit varies with time according to the equation:
![]()
Graphs of voltage and current as a function of time while the capacitor charges are shown below.

The product of the resistance and capacitance, RC, in the circuit is
known as the time constant. This is a measure of how fast the capacitor
will charge or discharge.
After charging a capacitor with a battery, the battery can be
removed and the capacitor can be used to supply current to the circuit.
In this case, the current obeys the same equation as above, decaying
away exponentially, and the voltage across the capacitor will vary as:
![]()
Graphs of the voltage and current while the capacitor discharges are
shown here. The current is shown negative because it is opposite in
direction to the current when the capacitor charges.

Currents in nerve cells
In the human body, signals are sent back and forth between muscles and the brain, as well as from our sensory receptors (eyes, ears, touch sensors, etc.) to the brain, along nerve cells. These nerve impulses are electrical signals that are transmitted along the body, or axon, of a nerve cell.
The axon is simply a long tube built to carry electrical signals. A potential difference of about 70 mV exists across the cell membrane when the cell is in its resting state; this is due to a small imbalance in the concentration of ions inside and outside the cell. The ions primarily responsible for the propagation of a nerve impulse are potassium (K+) and sodium +.
The potential inside the cell is at -70 mV with respect to the outside. Consider one point on the axon. If the potential inside the axon at that point is raised by a small amount, nothing much happens. If the potential inside is raised to about -55 mV, however, the permeability of the cell membrane changes. This causes sodium ions to enter the cell, raising the potential inside to about +50 mV. At this point the membrane becomes impermeable to sodium again, and potassium ions flow out of the cell, restoring the axon at that point to its rest state.
That brief rise to +50 mV at point A on the axon, however, causes the potential to rise at point B, leading to an ion transfer there, causing the potential there to shoot up to +50 mV, thereby affecting the potential at point C, etc. This is how nerve impulses are transmitted along the nerve cell.
Subject:
Subject X2:
Resistance and Ohm's Law; Series and Parallel
Current and resistance
7-12-99
Electrical resistance
Voltage can be thought of as the pressure pushing charges along a conductor, while the electrical resistance of a conductor is a measure of how difficult it is to push the charges along. Using the flow analogy, electrical resistance is similar to friction. For water flowing through a pipe, a long narrow pipe provides more resistance to the flow than does a short fat pipe. The same applies for flowing currents: long thin wires provide more resistance than do short thick wires.
The resistance (R) of a material depends on its length, cross-sectional area, and the resistivity (the Greek letter rho), a number that depends on the material:
The resistivity and conductivity are inversely related. Good
conductors have low resistivity, while poor conductors (insulators)
have resistivities that can be 20 orders of magnitude larger.
Resistance also depends on temperature, usually increasing as
the temperature increases. For reasonably small changes in temperature,
the change in resistivity, and therefore the change in resistance, is
proportional to the temperature change. This is reflected in the
equations:
At low temperatures some materials, known as superconductors, have no resistance at all. Resistance in wires produces a loss of energy (usually in the form of heat), so materials with no resistance produce no energy loss when currents pass through them.
Ohm's Law
In many materials, the voltage and resistance are connected by Ohm's Law:
Ohm's Law : V = IR
The connection between voltage and resistance can be more complicated in some materials.These materials are called non-ohmic. We'll focus mainly on ohmic materials for now, those obeying Ohm's Law.
Example
A copper wire has a length of 160 m and a diameter of 1.00 mm. If the wire is connected to a 1.5-volt battery, how much current flows through the wire?
The current can be found from Ohm's Law, V = IR. The V is the battery voltage, so if R can be determined then the current can be calculated. The first step, then, is to find the resistance of the wire:
L is the length, 1.60 m. The resistivity can be found from the table on page 535 in the textbook.
The area is the cross-sectional area of the wire. This can be calculated using:
The resistance of the wire is then:
The current can now be found from Ohm's Law:
I = V / R = 1.5 / 3.5 = 0.428 A
Electric power
Power is the rate at which work is done. It has units of Watts. 1 W = 1 J/s
Electric power is given by the equations:
The power supplied to a circuit by a battery is calculated using P = VI.
Batteries and power supplies supply power to a circuit, and this power is used up by motors as well as by anything that has resistance. The power dissipated in a resistor goes into heating the resistor; this is know as Joule heating. In many cases, Joule heating is wasted energy. In some cases, however, Joule heating is exploited as a source of heat, such as in a toaster or an electric heater.
The electric company bills not for power but for energy, using units of kilowatt-hours.
1 kW-h = 3.6 x 106 J
One kW-h typically costs about 10 cents, which is really quite cheap. It does add up, though. The following equation gives the total cost of operating something electrical:
Cost = (Power rating in kW) x (number of hours it's running) x (cost per kW-h)
An example...if a 100 W light bulb is on for two hours each day, and energy costs $0.10 per kW-h, how much does it cost to run the bulb for a month?
Cost = 0.1 kW x 60 hours x $0.1/kW-h = $0.6, or 60 cents.
Try this at home - figure out the monthly cost of using a particular appliance you use every day. Possibilities include hair dryers, microwaves, TV's, etc. The power rating of an appliance like a TV is usually written on the back, and if it doesn't give the power it should give the current. Anything you plug into a wall socket runs at 120 V, so if you know that and the current you can figure out how much power it uses.
The cost for power that comes from a wall socket is relatively cheap. On the other hand, the cost of battery power is much higher. $100 per kW-h, a thousand times more than what it costs for AC power from the wall socket, is a typical value.
Although power is cheap, it is not limitless. Electricity use continues to increase, so it is important to use energy more efficiently to offset consumption. Appliances that use energy most efficiently sometimes cost more but in the long run, when the energy savings are accounted for, they can end up being the cheaper alternative.
Direct current (DC) vs. alternating current (AC)
A battery produces direct current; the battery voltage (or emf) is constant, which generally results in a constant current flowing one way around a circuit. If the circuit has capacitors, which store charge, the current may not be constant, but it will still flow in one direction. The current that comes from a wall socket, on the other hand, is alternating current. With alternating current, the current continually changes direction. This is because the voltage (emf) is following a sine wave oscillation. For a wall socket in North America, the voltage changes from positive to negative and back again 60 times each second.
If you look at the voltage at its peak, it hits about +170 V, decreases through 0 to -170 V, and then rises back through 0 to +170 V again. (You might think this value of 170 V should really be 110 - 120 volts. That's actually a kind of average of the voltage, but the peak really is about 170 V.) This oscillating voltage produces an oscillating electric field; the electrons respond to this oscillating field and oscillate back and forth, producing an oscillating current in the circuit.
The graph above shows voltage as a function of time, but it could just as well show current as a function of time: the current also oscillates at the same frequency.
Root mean square
This average value we use for the voltage from a wall socket is known as the root mean square, or rms, average. Because the voltage varies sinusoidally, with as much positive as negative, doing a straight average would get you zero for the average voltage. The rms value, however, is obtained in this way:
* first, square everything (this makes everything positive)
* second, average
* third, take the square root of the average
Here's an example, using the four numbers -1, 1, 3, and 5. The average of these numbers is 8 / 4 = 2. To find the rms average, you square everything to get 1, 1, 9, and 25. Now you average those values, obtaining 36 / 4 = 9. Finally, take the square root to get 3. The average is 2, but the rms average is 3.
Doing this for a sine wave gets you an rms average that is the peak value of the sine wave divided by the square root of two. This is the same as multiplying by 0.707, so the relationship between rms values and peak values for voltage and current is:
Vrms = 0.707 Vo and Irms = 0.707 Io
In North America, the rms voltage is about 120 volts. If you need to know about the average power used, it is the rms values that go into the calculation.
Series circuits
A series circuit is a circuit in which resistors are arranged in a chain, so the current has only one path to take. The current is the same through each resistor. The total resistance of the circuit is found by simply adding up the resistance values of the individual resistors:
equivalent resistance of resistors in series : R = R1 + R2 + R3 + ...
A series circuit is shown in the diagram above. The current flows
through each resistor in turn. If the values of the three resistors are:
With a 10 V battery, by V = I R the total current in the circuit is:
I = V / R = 10 / 20 = 0.5 A. The current through each resistor would be 0.5 A.
Parallel circuits
A parallel circuit is a circuit in which the resistors are arranged with their heads connected together, and their tails connected together. The current in a parallel circuit breaks up, with some flowing along each parallel branch and re-combining when the branches meet again. The voltage across each resistor in parallel is the same.
The total resistance of a set of resistors in parallel is found by adding up the reciprocals of the resistance values, and then taking the reciprocal of the total:
equivalent resistance of resistors in parallel: 1 / R = 1 / R1 + 1 / R2 + 1 / R3 +...
A parallel circuit is shown in the diagram above. In this case the
current supplied by the battery splits up, and the amount going through
each resistor depends on the resistance. If the values of the three
resistors are:
With a 10 V battery, by V = I R the total current in the circuit is: I = V / R = 10 / 2 = 5 A.
The individual currents can also be found using I = V / R. The voltage across each resistor is 10 V, so:
I1 = 10 / 8 = 1.25 A
I2 = 10 / 8 = 1.25 A
I3=10 / 4 = 2.5 A
Note that the currents add together to 5A, the total current.
A parallel resistor short-cut
If the resistors in parallel are identical, it can be very easy to work out the equivalent resistance. In this case the equivalent resistance of N identical resistors is the resistance of one resistor divided by N, the number of resistors. So, two 40-ohm resistors in parallel are equivalent to one 20-ohm resistor; five 50-ohm resistors in parallel are equivalent to one 10-ohm resistor, etc.
When calculating the equivalent resistance of a set of parallel resistors, people often forget to flip the 1/R upside down, putting 1/5 of an ohm instead of 5 ohms, for instance. Here's a way to check your answer. If you have two or more resistors in parallel, look for the one with the smallest resistance. The equivalent resistance will always be between the smallest resistance divided by the number of resistors, and the smallest resistance. Here's an example.
You have three resistors in parallel, with values 6 ohms, 9 ohms, and 18 ohms. The smallest resistance is 6 ohms, so the equivalent resistance must be between 2 ohms and 6 ohms (2 = 6 /3, where 3 is the number of resistors).
Doing the calculation gives 1/6 + 1/12 + 1/18 = 6/18. Flipping this upside down gives 18/6 = 3 ohms, which is certainly between 2 and 6.
Circuits with series and parallel components
Many circuits have a combination of series and parallel resistors. Generally, the total resistance in a circuit like this is found by reducing the different series and parallel combinations step-by-step to end up with a single equivalent resistance for the circuit. This allows the current to be determined easily. The current flowing through each resistor can then be found by undoing the reduction process.
General rules for doing the reduction process include:
1. Two (or more) resistors with their heads directly connected together and their tails directly connected together are in parallel, and they can be reduced to one resistor using the equivalent resistance equation for resistors in parallel.
2. Two resistors connected together so that the tail of one is connected to the head of the next, with no other path for the current to take along the line connecting them, are in series and can be reduced to one equivalent resistor.
Finally, remember that for resistors in series, the current is the same for each resistor, and for resistors in parallel, the voltage is the same for each one.
Subject:
Subject X2:
Electric Charge, Force, Field, and Potential
Subject:
Subject X2:
Electric Energy and Potential
7-8-99
Potential energy
In discussing gravitational potential energy in PY105, we usually
associated it with a single object. An object near the surface of the
Earth has a potential energy because of its gravitational interaction
with the Earth; potential energy is really not associated with a single
object, it comes from an interaction between objects.
Similarly, there is an electric potential energy associated with
interacting charges. For each pair of interacting charges, the
potential energy is given by:
electric potential energy: PE = k q Q / r
Energy is a scalar, not a vector. To find the total electric potential
energy associated with a set of charges, simply add up the energy
(which may be positive or negative) associated with each pair of
charges.
An object near the surface of the Earth experiences a nearly uniform
gravitational field with a magnitude of g; its gravitational potential
energy is mgh. A charge in a uniform electric field E has an electric
potential energy which is given by qEd, where d is the distance moved
along (or opposite to) the direction of the field. If the charge moves
in the same direction as the force it experiences, it is losing
potential energy; if it moves opposite to the direction of the force,
it is gaining potential energy.
The relationship between work, kinetic energy, and potential energy, which was discussed in PY105, still applies:
An example
Two positively-charged balls are tied together by a string. One ball
has a mass of 30 g and a charge of 1 ; the other has a mass of 40 g and
a charge of 2 . The distance between them is 5 cm. The ball with the smaller charge
has a mass of 30 g; the other ball has a mass of 40 g. Initially they
are at rest, but when the string is cut they move apart. When they are
a long way away from each other, how fast are they going?
Let's start by looking at energy. No external forces act on this
system of two charges, so the energy must be conserved. To start with
all the energy is potential energy; this will be converted into kinetic
energy.
Energy at the start : KE = 0
PE = k q Q / r = (8.99 x 109) (1 x 10-6) (2 x 10-6) / 0.05 = 0.3596 J
When the balls are very far apart, the r in the equation for
potential energy will be large, making the potential energy negligibly
small.
Energy is conserved, so the kinetic energy at the end is equal to the potential energy at the start:
The masses are known, but the two velocities are not. To solve for the
velocities, we need another relationship between them. Because no
external forces act on the system, momentum will also be conserved.
Before the string is cut, the momentum is zero, so the momentum has to
be zero all the way along. The momentum of one ball must be equal and
opposite to the momentum of the other, so:
Plugging this into the energy equation gives:
Electric potential
Electric potential is more commonly known as voltage. The potential at a point a distance r from a charge Q is given by:
V = k Q / r
Potential plays the same role for charge that pressure does for fluids.
If there is a pressure difference between two ends of a pipe filled
with fluid, the fluid will flow from the high pressure end towards the
lower pressure end. Charges respond to differences in potential in a
similar way.
Electric potential is a measure of the potential energy per unit
charge. If you know the potential at a point, and you then place a
charge at that point, the potential energy associated with that charge
in that potential is simply the charge multiplied by the potential.
Electric potential, like potential energy, is a scalar, not a vector.
connection between potential and potential energy: V = PE / q
Equipotential lines are connected lines of the same potential. These
often appear on field line diagrams. Equipotential lines are always
perpendicular to field lines, and therefore perpendicular to the force
experienced by a charge in the field. If a charge moves along an
equipotential line, no work is done; if a charge moves between
equipotential lines, work is done.
Field lines and equipotential lines for a point charge, and for a constant field between two charged plates, are shown below:
An example : Ionization energy of the electron in a hydrogen atom
In the Bohr model of a hydrogen atom, the electron, if it is in the
ground state, orbits the proton at a distance of r = 5.29 x 10-11 m.
Note that the Bohr model, the idea of electrons as tiny balls orbiting
the nucleus, is not a very good model of the atom. A better picture is
one in which the electron is spread out around the nucleus in a cloud
of varying density; however, the Bohr model does give the right answer
for the ionization energy, the energy required to remove the electron
from the atom.
The total energy is the sum of the electron's kinetic energy and the
potential energy coming from the electron-proton interaction.
The kinetic energy is given by KE = 1/2 mv2.
This can be found by analyzing the force on the electron. This force is
the Coulomb force; because the electron travels in a circular orbit,
the acceleration will be the centripetal acceleration:
Note that the negative sign coming from the charge on the electron
has been incorporated into the direction of the force in the equation
above.
This gives m v2 = k e2 / r, so the kinetic energy is KE = 1/2 k e2 / r.
The potential energy, on the other hand, is PE = - k e2
/ r. Note that the potential energy is twice as big as the kinetic
energy, but negative. This relationship between the kinetic and
potential energies is valid not just for electrons orbiting protons,
but also in gravitational situations, such as a satellite orbiting the
Earth.
The total energy is:
KE + PE = -1/2 ke2 / r = - 1/2 (8.99 x 109)(1.60 x 10-19) / 5.29 x 10-11
This works out to -2.18 x 10-18 J. This is usually stated in energy units of electron volts (eV). An eV is 1.60 x 10-19
J, so dividing by this gives an energy of -13.6 eV. To remove the
electron from the atom, 13.6 eV must be put in; 13.6 eV is thus the
ionization energy of a ground-state electron in hydrogen.
Subject:
Subject X2:
Electric charge and Coulomb's law
7-6-99
Charge
* there are two kinds of charge, positive and negative
* like charges repel, unlike charges attract
* positive charge comes from having more protons than electrons; negative charge comes from having more electrons than protons
* charge is quantized, meaning that charge comes in integer multiples of the elementary charge e
* charge is conserved
Probably everyone is familiar with the first three concepts, but what does it mean for charge to be quantized? Charge comes in multiples of an indivisible unit of charge, represented by the letter e. In other words, charge comes in multiples of the charge on the electron or the proton. These things have the same size charge, but the sign is different. A proton has a charge of +e, while an electron has a charge of -e.
Electrons and protons are not the only things that carry charge. Other particles (positrons, for example) also carry charge in multiples of the electronic charge. Those are not going to be discussed, for the most part, in this course, however.
Putting "charge is quantized" in terms of an equation, we say:
q = n e
q is the symbol used to represent charge, while n is a positive or negative integer, and e is the electronic charge, 1.60 x 10-19 Coulombs.
The Law of Conservation of Charge
The Law of conservation of charge states that the net charge of an isolated system remains constant.
If a system starts out with an equal number of positive and negative charges, there¹s nothing we can do to create an excess of one kind of charge in that system unless we bring in charge from outside the system (or remove some charge from the system). Likewise, if something starts out with a certain net charge, say +100 e, it will always have +100 e unless it is allowed to interact with something external to it.
Charge can be created and destroyed, but only in positive-negative pairs.
Table of elementary particle masses and charges:
Electrostatic charging
Forces between two electrically-charged objects can be extremely large. Most things are electrically neutral; they have equal amounts of positive and negative charge. If this wasn¹t the case, the world we live in would be a much stranger place. We also have a lot of control over how things get charged. This is because we can choose the appropriate material to use in a given situation.
Metals are good conductors of electric charge, while plastics, wood, and rubber are not. They¹re called insulators. Charge does not flow nearly as easily through insulators as it does through conductors, which is why wires you plug into a wall socket are covered with a protective rubber coating. Charge flows along the wire, but not through the coating to you.
Materials are divided into three categories, depending on how easily they will allow charge (i.e., electrons) to flow along them. These are:
* conductors - metals, for example
* semi-conductors - silicon is a good example
* insulators - rubber, wood, plastic for example
Most materials are either conductors or insulators. The difference between them is that in conductors, the outermost electrons in the atoms are so loosely bound to their atoms that they¹re free to travel around. In insulators, on the other hand, the electrons are much more tightly bound to the atoms, and are not free to flow. Semi-conductors are a very useful intermediate class, not as conductive as metals but considerably more conductive than insulators. By adding certain impurities to semi-conductors in the appropriate concentrations the conductivity can be well-controlled.
There are three ways that objects can be given a net charge. These are:
1. Charging by friction - this is useful for charging insulators. If you rub one material with another (say, a plastic ruler with a piece of paper towel), electrons have a tendency to be transferred from one material to the other. For example, rubbing glass with silk or saran wrap generally leaves the glass with a positive charge; rubbing PVC rod with fur generally gives the rod a negative charge.
2. Charging by conduction - useful for charging metals and other conductors. If a charged object touches a conductor, some charge will be transferred between the object and the conductor, charging the conductor with the same sign as the charge on the object.
3. Charging by induction - also useful for charging metals and other conductors. Again, a charged object is used, but this time it is only brought close to the conductor, and does not touch it. If the conductor is connected to ground (ground is basically anything neutral that can give up electrons to, or take electrons from, an object), electrons will either flow on to it or away from it. When the ground connection is removed , the conductor will have a charge opposite in sign to that of the charged object.
An example of induction using a negatively charged object and an initially-uncharged conductor (for example, a metal ball on a plastic handle).
(1) bring the negatively-charged object close to, but not touching, the conductor. Electrons on the conductor will be repelled from the area nearest the charged object.
(2) connect the conductor to ground. The electrons on the conductor want to get as far away from the negatively-charged object as possible, so some of them flow to ground.
(3) remove the ground connection. This leaves the conductor with a deficit of electrons.
(4) remove the charged object. The conductor is now positively charged.
A practical application involving the transfer of charge is in how laser printers and photocopiers work.
Why is static electricity more apparent in winter?
You notice static electricity much more in winter (with clothes in a dryer, or taking a sweater off, or getting a shock when you touch something after walking on carpet) than in summer because the air is much drier in winter than summer. Dry air is a relatively good electrical insulator, so if something is charged the charge tends to stay. In more humid conditions, such as you find on a typical summer day, water molecules, which are polarized, can quickly remove charge from a charged object.
Try this at home
See if you can charge something at home using friction. I got good results by rubbing a Bic pen with a piece of paper towel. To test the charge, you can use a narrow stream of water from a faucet; if the object attracts the stream when it's brought close, you know it's charged. All you need to do is to find something to rub - try anything made out of hard plastic or rubber. You also need to find something to rub the object with - potential candidates are things like paper towel, wool, silk, and saran wrap or other plastic.
Coulomb's law
The force exerted by one charge q on another charge Q is given by Coulomb's law:
r is the distance between the charges.
Remember that force is a vector, so when more than one charge exerts a force on another charge, the net force on that charge is the vector sum of the individual forces. Remember, too, that charges of the same sign exert repulsive forces on one another, while charges of opposite sign attract.
An example
Four charges are arranged in a square with sides of length 2.5 cm. The two charges in the top right and bottom left corners are +3.0 x 10-6 C. The charges in the other two corners are -3.0 x 10-6 C. What is the net force exerted on the charge in the top right corner by the other three charges?
To solve any problem like this, the simplest thing to do is to draw
a good diagram showing the forces acting on the charge. You should also
let your diagram handle your signs for you. Force is a vector, and any
time you have a minus sign associated with a vector all it does is tell
you about the direction of the vector. If you have the arrows giving
you the direction on your diagram, you can just drop any signs that
come out of the equation for Coulomb's law.
Consider the forces exerted on the charge in the top right by the other three:
You have to be very careful to add these forces as vectors to get the
net force. In this problem we can take advantage of the symmetry, and
combine the forces from charges 2 and 4 into a force along the diagonal
(opposite to the force from charge 3) of magnitude 183.1 N. When this
is combined with the 64.7 N force in the opposite direction, the result
is a net force of 118 N pointing along the diagonal of the square.
The symmetry here makes things a little easier. If it wasn't so symmetric, all you'd have to do is split the vectors up in to x and y components, add them to find the x and y components of the net force, and then calculate the magnitude and direction of the net force from the components. Example 16-4 in the textbook shows this process.
The parallel between gravity and electrostatics
An electric field describes how an electric charge affects the region around it. It's a powerful concept, because it allows you to determine ahead of time how a charge will be affected if it is brought into the region. Many people have trouble with the concept of a field, though, because it's something that's hard to get a real feel for. The fact is, though, that you're already familiar with a field. We've talked about gravity, and we've even used a gravitational field; we just didn't call it a field.
When talking about gravity, we got into the (probably bad) habit of calling g "the acceleration due to gravity". It's more accurate to call g the gravitational field produced by the Earth at the surface of the Earth. If you understand gravity you can understand electric forces and fields because the equations that govern both have the same form.
The gravitational force between two masses (m and M) separated by a distance r is given by Newton's law of universal gravitation:
A similar equation applies to the force between two charges (q and Q) separated by a distance r:
The force equations are similar, so the behavior of interacting masses is similar to that of interacting charges, and similar analysis methods can be used. The main difference is that gravitational forces are always attractive, while electrostatic forces can be attractive or repulsive. The charge (q or Q) plays the same role in the electrostatic case that the mass (m or M) plays in the case of the gravity.
A good example of a question involving two interacting masses is a projectile motion problem, where there is one mass m, the projectile, interacting with a much larger mass M, the Earth. If we throw the projectile (at some random launch angle) off a 40-meter-high cliff, the force on the projectile is given by:
F = mg
This is the same equation as the more complicated equation above, with G, M, and the radius of the Earth, squared, incorporated into g, the gravitational field.
So, you've seen a field before, in the form of g. Electric fields operate in a similar way. An equivalent electrostatics problem is to launch a charge q (again, at some random angle) into a uniform electric field E, as we did for m in the Earth's gravitational field g. The force on the charge is given by F = qE, the same way the force on the mass m is given by F = mg.
We can extend the parallel between gravity and electrostatics to energy, but we'll deal with that later. The bottom line is that if you can do projectile motion questions using gravity, you should be able to do them using electrostatics. In some cases, you¹ll need to apply both; in other cases one force will be so much larger than the other that you can ignore one (generally if you can ignore one, it'll be the gravitational force).
Subject:
Subject X2:
The Electric Field
7-7-99
Electric field
To help visualize how a charge, or a collection of charges, influences the region around it, the concept of an electric field is used. The electric field E is analogous to g, which we called the acceleration due to gravity but which is really the gravitational field. Everything we learned about gravity, and how masses respond to gravitational forces, can help us understand how electric charges respond to electric forces.
The electric field a distance r away from a point charge Q is given by:
Electric field from a point charge : E = k Q / r2
The electric field from a positive charge points away from the charge; the electric field from a negative charge points toward the charge. Like the electric force, the electric field E is a vector. If the electric field at a particular point is known, the force a charge q experiences when it is placed at that point is given by :
F = qE
If q is positive, the force is in the same direction as the field; if q is negative, the force is in the opposite direction as the field.
Learning from gravity
Right now you are experiencing a uniform gravitational field: it has a magnitude of 9.8 m/s2 and points straight down. If you threw a mass through the air, you know it would follow a parabolic path because of gravity. You could determine when and where the object would land by doing a projectile motion analysis, separating everything into x and y components. The horizontal acceleration is zero, and the vertical acceleration is g. We know this because a free-body diagram shows only mg, acting vertically, and applying Newton's second law tells us that mg = ma, so a = g.
You can do the same thing with charges in a uniform electric field. If you throw a charge into a uniform electric field (same magnitude and direction everywhere), it would also follow a parabolic path. We're going to neglect gravity; the parabola comes from the constant force experienced by the charge in the electric field. Again, you could determine when and where the charge would land by doing a projectile motion analysis. The acceleration is again zero in one direction and constant in the other. The value of the acceleration can be found by drawing a free-body diagram (one force, F = qE) and applying Newton's second law. This says:
qE = ma, so the acceleration is a = qE / m.
Is it valid to neglect gravity? What matters is the size of qE / m relative to g. As long as qE / m is much larger than g, gravity can be ignored. Gravity is very easy to account for, of course : simply add mg to the free-body diagram and go from there.
The one big difference between gravity and electricity is that m, the mass, is always positive, while q, the charge, can be positive, zero, or negative.
What does an electric field look like?
An electric field can be visualized on paper by drawing lines of force, which give an indication of both the size and the strength of the field. Lines of force are also called field lines. Field lines start on positive charges and end on negative charges, and the direction of the field line at a point tells you what direction the force experienced by a charge will be if the charge is placed at that point. If the charge is positive, it will experience a force in the same direction as the field; if it is negative the force will be opposite to the field.
The fields from isolated, individual charges look like this:
When there is more than one charge in a region, the electric field lines will not be straight lines; they will curve in response to the different charges. In every case, though, the field is highest where the field lines are close together, and decreases as the lines get further apart.
An example
Two charges are placed on the x axis. The first, with a charge of +Q, is at the origin. The second, with a charge of -2Q, is at x = 1.00 m. Where on the x axis is the electric field equal to zero?
This question involves an important concept that we haven't
discussed yet: the field from a collection of charges is simply the
vector sum of the fields from the individual charges. To find the
places where the field is zero, simply add the field from the first
charge to that of the second charge and see where they cancel each
other out.
In any problem like this it's helpful to come up with a rough
estimate of where the point, or points, where the field is zero is/are.
There is no such point between the two charges, because between them
the field from the +Q charge points to the right and so does the field
from the -2Q charge. To the right of the -2Q charge, the field from the
+Q charge points right and the one from the -2Q charge points left. The
field from the -2Q charge is always larger, though, because the charge
is bigger and closer, so the fields can't cancel. To the left of the +Q
charge, though, the fields can cancel. Let's say the point where they
cancel is a distance x to the left of the +Q charge.
Cross-multiplying and expanding the bracket gives:
Solving for x using the quadratic equation gives: x = 2.41 m or x = -0.414 m
The answer to go with is x = 2.41 m. This corresponds to 2.41 m to the left of the +Q charge. The other point is between the charges. It corresponds to the point where the fields from the two charges have the same magnitude, but they both point in the same direction there so they don't cancel out.
The field around a charged conductor
A conductor is in electrostatic equilibrium when the charge distribution (the way the charge is distributed over the conductor) is fixed. Basically, when you charge a conductor the charge spreads itself out. At equilibrium, the charge and electric field follow these guidelines:
* the excess charge lies only at the surface of the conductor
* the electric field is zero within the solid part of the conductor
* the electric field at the surface of the conductor is perpendicular to the surface
* charge accumulates, and the field is strongest, on pointy parts of the conductor
Let's see if we can explain these things. Consider a negatively-charged conductor; in other words, a conductor with an excess of electrons. The excess electrons repel each other, so they want to get as far away from each other as possible. To do this they move to the surface of the conductor. They also distribute themselves so the electric field inside the conductor is zero. If the field wasn't zero, any electrons that are free to move would. There are plenty of free electrons inside the conductor (they're the ones that are canceling out the positive charge from all the protons) and they don't move, so the field must be zero.
A similar argument explains why the field at the surface of the conductor is perpendicular to the surface. If it wasn't, there would be a component of the field along the surface. A charge experiencing that field would move along the surface in response to that field, which is inconsistent with the conductor being in equilibrium.
Why does charge pile up at the pointy ends of a conductor? Consider two conductors, one in the shape of a circle and one in the shape of a line. Charges are distributed uniformly along both conductors. With the circular shape, each charge has no net force on it, because there is the same amount of charge on either side of it and it is uniformly distributed. The circular conductor is in equilibrium, as far as its charge distribution is concerned.
With the line, on the other hand, a uniform distribution does not
correspond to equilbrium. If you look at the second charge from the
left on the line, for example, there is just one charge to its left and
several on the right. This charge would experience a force to the left,
pushing it down towards the end. For charge distributed along a line,
the equilibrium distribution would look more like this:
The charge accumulates at the pointy ends because that balances the forces on each charge.
Electric flux
A clever way to calculate the electric field from a charged conductor is to use Gauss' Law, which is explained in Appendix D in the textbook. Gauss' Law can be tricky to apply, though, so we won't get into that. What we will do is to look at some implications of Gauss' Law. It's also a good time to introduce the concept of flux. This is important for deriving electric fields with Gauss' Law, which you will NOT be responsible for; where it'll really help us out is when we get to magnetism, when we do magnetic flux.
Electric flux is a measure of the number of electric field lines passing through an area. To calculate the flux through a particular surface, multiply the surface area by the component of the electric field perpendicular to the surface. If the electric field is parallel to the surface, no field lines pass through the surface and the flux will be zero. The maximum flux occurs when the field is perpendicular to the surface.
Permittivity
Even though we won't use this for anything, we should at least write down Gauss' law:
Gauss' Law - the sum of the electric flux through a surface is equal to the charge enclosed by a surface divided by a constant , the permittivity of free space.
What is the permittivity of free space? It's a constant related to the
constant k that appears in Coulomb's law. The relationship between the
two is this:
Implications of Gauss' Law
Gauss' Law is a powerful method of calculating electric fields. If you have a solid conducting sphere (e.g., a metal ball) that has a net charge Q on it, you know all the excess charge lies on the outside of the sphere. Gauss' law tells us that the electric field inside the sphere is zero, and the electric field outside the sphere is the same as the field from a point charge with a net charge of Q. That's a pretty neat result.
The result for the sphere applies whether it's solid or hollow. Let's
look at the hollow sphere, and make it more interesting by adding a
point charge at the center.
What does the electric field look like around this charge inside the hollow sphere? How is the negative charge distributed on the hollow sphere? To find the answers, keep these things in mind:
* The electric field must be zero inside the solid part of the sphere
* Outside the solid part of the sphere, you can find the net electric field by adding, as vectors, the electric field from the point charge alone and from the sphere alone
We know that the electric field from the point charge is given by kq / r2. Because the charge is positive, the field points away from the charge.
If we took the point charge out of the sphere, the field from the negative charge on the sphere would be zero inside the sphere, and given by kQ / r2 outside the sphere.
The net electric field with the point charge and the charged sphere, then, is the sum of the fields from the point charge alone and from the sphere alone (except inside the solid part of the sphere, where the field must be zero). This is shown in the picture:
How is the charge distributed on the sphere? The electrons must
distribute themselves so the field is zero in the solid part. This
means there must be -5 microcoulombs of charge on the inner surface, to
stop all the field lines from the +5 microcoulomb point charge. There
must then be +2 microcoulombs of charge on the outer surface of the
sphere, to give a net charge of -5+2 = -3 microcoulombs.
Subject:
Subject X2:
Electromagnetic Induction and AC Circuits
Subject:
Subject X2:
AC Circuits
7-23-99
Alternating current
Direct current (DC) circuits involve current flowing in one direction.
In alternating current (AC) circuits, instead of a constant voltage
supplied by a battery, the voltage oscillates in a sine wave pattern,
varying with time as:
In a household circuit, the frequency is 60 Hz. The angular frequency is related to the frequency, f, by:
Vo represents the maximum voltage, which in a household circuit in
North America is about 170 volts. We talk of a household voltage of 120
volts, though; this number is a kind of average value of the voltage.
The particular averaging method used is something called root mean
square (square the voltage to make everything positive, find the
average, take the square root), or rms. Voltages and currents for AC
circuits are generally expressed as rms values. For a sine wave, the
relationship between the peak and the rms average is:
rms value = 0.707 peak value
Resistance in an AC circuit
The relationship V = IR applies for resistors in an AC circuit, so
In AC circuits we'll talk a lot about the phase of the current relative
to the voltage. In a circuit which only involves resistors, the current
and voltage are in phase with each other, which means that the peak
voltage is reached at the same instant as peak current. In circuits
which have capacitors and inductors (coils) the phase relationships
will be quite different.
Capacitance in an AC circuit
Consider now a circuit which has only a capacitor and an AC power
source (such as a wall outlet). A capacitor is a device for storing
charging. It turns out that there is a 90° phase difference between the
current and voltage, with the current reaching its peak 90° (1/4 cycle)
before the voltage reaches its peak. Put another way, the current leads
the voltage by 90° in a purely capacitive circuit.
To understand why this is, we should review some of the relevant equations, including:
relationship between voltage and charge for a capacitor: CV = Q
The AC power supply produces an oscillating voltage. We should
follow the circuit through one cycle of the voltage to figure out what
happens to the current.
Step 1 - At point a (see diagram) the voltage is zero and the
capacitor is uncharged. Initially, the voltage increases quickly. The
voltage across the capacitor matches the power supply voltage, so the
current is large to build up charge on the capacitor plates. The closer
the voltage gets to its peak, the slower it changes, meaning less
current has to flow. When the voltage reaches a peak at point b, the
capacitor is fully charged and the current is momentarily zero.
Step 2 - After reaching a peak, the voltage starts dropping.
The capacitor must discharge now, so the current reverses direction.
When the voltage passes through zero at point c, it's changing quite
rapidly; to match this voltage the current must be large and negative.
Step 3 - Between points c and d, the voltage is negative.
Charge builds up again on the capacitor plates, but the polarity is
opposite to what it was in step one. Again the current is negative, and
as the voltage reaches its negative peak at point d the current drops
to zero.
Step 4 - After point d, the voltage heads toward zero and the
capacitor must discharge. When the voltage reaches zero it's gone
through a full cycle so it's back to point a again to repeat the cycle.
The larger the capacitance of the capacitor, the more charge
has to flow to build up a particular voltage on the plates, and the
higher the current will be. The higher the frequency of the voltage,
the shorter the time available to change the voltage, so the larger the
current has to be. The current, then, increases as the capacitance
increases and as the frequency increases.
Usually this is thought of in terms of the effective
resistance of the capacitor, which is known as the capacitive
reactance, measured in ohms. There is an inverse relationship between
current and resistance, so the capacitive reactance is inversely
proportional to the capacitance and the frequency:
A capacitor in an AC circuit exhibits a kind of resistance
called capacitive reactance, measured in ohms. This depends on the
frequency of the AC voltage, and is given by:
We can use this like a resistance (because, really, it is a resistance)
in an equation of the form V = IR to get the voltage across the
capacitor:
Note that V and I are generally the rms values of the voltage and current.
Inductance in an AC circuit
An inductor is simply a coil of wire (often wrapped around a piece
of ferromagnet). If we now look at a circuit composed only of an
inductor and an AC power source, we will again find that there is a 90°
phase difference between the voltage and the current in the inductor.
This time, however, the current lags the voltage by 90°, so it reaches
its peak 1/4 cycle after the voltage peaks.
The reason for this has to do with the law of induction:
Applying Kirchoff's loop rule to the circuit above gives:
As the voltage from the power source increases from zero, the
voltage on the inductor matches it. With the capacitor, the voltage
came from the charge stored on the capacitor plates (or, equivalently,
from the electric field between the plates). With the inductor, the
voltage comes from changing the flux through the coil, or,
equivalently, changing the current through the coil, which changes the
magnetic field in the coil.
To produce a large positive voltage, a large increase in
current is required. When the voltage passes through zero, the current
should stop changing just for an instant. When the voltage is large and
negative, the current should be decreasing quickly. These conditions
can all be satisfied by having the current vary like a negative cosine
wave, when the voltage follows a sine wave.
How does the current through the inductor depend on the
frequency and the inductance? If the frequency is raised, there is less
time to change the voltage. If the time interval is reduced, the change
in current is also reduced, so the current is lower. The current is
also reduced if the inductance is increased.
As with the capacitor, this is usually put in terms of the
effective resistance of the inductor. This effective resistance is
known as the inductive reactance. This is given by:
where L is the inductance of the coil (this depends on the geometry
of the coil and whether its got a ferromagnetic core). The unit of
inductance is the henry.
As with capacitive reactance, the voltage across the inductor is given by:
Where does the energy go?
One of the main differences between resistors, capacitors, and
inductors in AC circuits is in what happens with the electrical energy.
With resistors, power is simply dissipated as heat. In a capacitor, no
energy is lost because the capacitor alternately stores charge and then
gives it back again. In this case, energy is stored in the electric
field between the capacitor plates. The amount of energy stored in a
capacitor is given by:
In other words, there is energy associated with an electric field. In
general, the energy density (energy per unit volume) in an electric
field with no dielectric is:
With a dielectric, the energy density is multiplied by the dielectric constant.
There is also no energy lost in an inductor, because energy is
alternately stored in the magnetic field and then given back to the
circuit. The energy stored in an inductor is:
Again, there is energy associated with the magnetic field. The energy density in a magnetic field is:
RLC Circuits
Consider what happens when resistors, capacitors, and inductors are
combined in one circuit. If all three components are present, the
circuit is known as an RLC circuit (or LRC). If only two components are
present, it's either an RC circuit, an RL circuit, or an LC circuit.
The overall resistance to the flow of current in an RLC circuit
is known as the impedance, symbolized by Z. The impedance is found by
combining the resistance, the capacitive reactance, and the inductive
reactance. Unlike a simple series circuit with resistors, however,
where the resistances are directly added, in an RLC circuit the
resistance and reactances are added as vectors.
This is because of the phase relationships. In a circuit with
just a resistor, voltage and current are in phase. With only a
capacitor, current is 90° ahead of the voltage, and with just an
inductor the reverse is true, the voltage leads the current by 90°.
When all three components are combined into one circuit, there has to
be some compromise.
To figure out the overall effective resistance, as well as to
determine the phase between the voltage and current, the impedance is
calculated like this. The resistance R is drawn along the +x-axis of an
x-y coordinate system. The inductive reactance is at 90° to this, and
is drawn along the +y-axis. The capacitive reactance is also at 90° to
the resistance, and is 180° different from the inductive reactance, so
it's drawn along the -y-axis. The impedance, Z, is the sum of these
vectors, and is given by:
The current and voltage in an RLC circuit are related by V = IZ. The
phase relationship between the current and voltage can be found from
the vector diagram: its the angle between the impedance, Z, and the
resistance, R. The angle can be found from:
If the angle is positive, the voltage leads the current by that angle. If the angle is negative, the voltage lags the currents.
The power dissipated in an RLC circuit is given by:
Note that all of this power is lost in the resistor; the capacitor and
inductor alternately store energy in electric and magnetic fields and
then give that energy back to the circuit.
Subject:
Subject X2:
Faraday's Law
Induced EMF
7-21-99
Linking electricity and magnetism
So far we've dealt with electricity and magnetism as separate topics.
From now on we'll investigate the inter-connection between the two,
starting with the concept of induced EMF. This involves generating a
voltage by changing the magnetic field that passes through a coil of
wire.
We'll come back and investigate this quantitatively, but for now we can
just play with magnets, magnetic fields, and coils of wire. You'll be
doing some more playing like this in one of the labs. There are also
some coils and magnets available in the undergraduate resource room -
please feel free to use them.
First, connect a coil of wire to a galvanometer, which is just a very
sensitive device we can use to measure current in the coil. There is no
battery or power supply, so no current should flow. Now bring a magnet
close to the coil. You should notice two things:
1. If the magnet is held stationary near, or even inside, the coil, no current will flow through the coil.
2. If the magnet is moved, the galvanometer needle will deflect,
showing that current is flowing through the coil. When the magnet is
moved one way (say, into the coil), the needle deflects one way; when
the magnet is moved the other way (say, out of the coil), the needle
deflects the other way. Not only can a moving magnet cause a current to
flow in the coil, the direction of the current depends on how the
magnet is moved.
How can this be explained? It seems like a constant magnetic field does
nothing to the coil, while a changing field causes a current to flow.
To confirm this, the magnet can be replaced with a second coil, and a
current can be set up in this coil by connecting it to a battery. The
second coil acts just like a bar magnet. When this coil is placed next
to the first one, which is still connected to the galvanometer, nothing
happens when a steady current passes through the second coil. When the
current in the second coil is switched on or off, or changed in any
way, however, the galvanometer responds, indicating that a current is
flowing in the first coil.
You also notice one more thing. If you squeeze the first coil, changing
its area, while it's sitting near a stationary magnet, the galvanometer
needle moves, indicating that current is flowing through the coil.
What you can conclude from all these observations is that a changing
magnetic field will produce a voltage in a coil, causing a current to
flow. To be completely accurate, if the magnetic flux through a coil is
changed, a voltage will be produced. This voltage is known as the
induced emf.
The magnetic flux is a measure of the number of magnetic field lines
passing through an area. If a loop of wire with an area A is in a
magnetic field B, the magnetic flux is given by:
If the flux changes, an emf will be induced. There are therefore three ways an emf can be induced in a loop:
1. Change the magnetic field
2. Change the area of the loop
3. Change the angle between the field and the loop
Faraday's law of induction
We'll move from the qualitative investigation of induced emf to the
quantitative picture. As we have learned, an emf can be induced in a
coil if the magnetic flux through the coil is changed. It also makes a
difference how fast the change is; a quick change induces more emf than
a gradual change. This is summarized in Faraday's law of induction. The
induced emf in a coil of N loops produced by a change in flux in a
certain time interval is given by:
Recalling that the flux through a loop of area A is given by
Faraday's law can be written:
The negative sign in Faraday's law comes from the fact that the emf
induced in the coil acts to oppose any change in the magnetic flux.
This is summarized in Lenz's law.
Lenz's law: The induced emf generates a current that sets up a magnetic field which acts to oppose the change in magnetic flux.
Another way of stating Lenz's law is to say that coils and loops like
to maintain the status quo (i.e., they don't like change). If a coil
has zero magnetic flux, when a magnet is brought close then, while the
flux is changing, the coil will set up its own magnetic field that
points opposite to the field from the magnet. On the other hand, a coil
with a particular flux from an external magnetic field will set up its
own magnetic field in an attempt to maintain the flux at a constant
level if the external field (and therefore flux) is changed.
An example
Consider a flat square coil with N = 5 loops. The coil is 20 cm on
each side, and has a magnetic field of 0.3 T passing through it. The
plane of the coil is perpendicular to the magnetic field: the field
points out of the page.
(a) If nothing is changed, what is the induced emf?
There is only an induced emf when the magnetic flux changes, and
while the change is taking place. If nothing changes, the induced emf
is zero.
(b) The magnetic field is increased uniformly from 0.3 T to 0.8
T in 1.0 seconds. While the change is taking place, what is the induced
emf in the coil?
Probably the most straight-forward way to approach this is to calculate the initial and final magnetic flux through the coil.
The induced emf is then:
(c) While the magnetic field is changing, the emf induced in the
coil causes a current to flow. Does the current flow clockwise or
counter-clockwise around the coil?
To answer this, apply Lenz's law, as well as the right-hand
rule. While the magnetic field is being changed, the magnetic flux is
being increased out of the page. According to Lenz's law, the emf
induced in the loop by this changing flux produces a current that sets
up a field opposing the change. The field set up by the current in the
coil, then, points into the page, opposite to the direction of the
increase in flux. To produce a field into the page, the current must
flow clockwise around the loop. This can be found from the right hand
rule.
One way to apply the rule is this. Point the thumb on your right hand
in the direction of the required field, into the page in this case. If
you curl your fingers, they curl in the direction the current flows
around the loop - clockwise.
Motional emf
Let's say you have a metal rod, and decide to connect that to your
galvanometer. If the rod is stationary in a magnetic field, nothing
happens. If you move the rod through the field, however, an emf is
induced between the ends of the rod causing current to flow. This is
because when you move the metal rod through the field, you are moving
all the electrons in the rod. These moving charges are deflected by the
field toward one end of the rod, creating a potential difference. This
is known as motional emf. Motional emf can even be measured on
airplanes. As the plane flies through the Earth's magnetic field, an
emf is induced between the wingtips.
Motional emf is largest when the direction of motion of the piece of
metal is perpendicular to the rod and perpendicular to the magnetic
field. When this is true, the motional emf is proportional to the speed
of the rod, the length (L) of the rod, and the magnetic field:
If the metal rod is part of a complete circuit, the induced emf will
cause a current to flow. Because it's in a magnetic field, the rod
experiences a force because of the interaction between the field and
the current. This force always acts to oppose the motion of the rod.
When we looked at DC motors, we saw how the force exerted on a
current flowing around a coil in a magnetic field can produce rotation,
transforming electrical energy to mechanical energy. Motional emf is a
good example of how mechanical energy, energy associated with motion,
can be transformed to electrical energy.
Subject:
Subject X2:
Generators, Inductance, and Transformers
Applications of electromagnetic induction
7-22-99
Electromagnetic induction is an incredibly useful phenomenon with a wide variety of applications. Induction is used in power generation and power transmission, and it's worth taking a look at how that's done. There are other effects with some interesting applications to consider, too, such as eddy currents.
Eddy currents
An eddy current is a swirling current set up in a conductor in response to a changing magnetic field. By Lenz¹s law, the current swirls in such a way as to create a magnetic field opposing the change; to do this in a conductor, electrons swirl in a plane perpendicular to the magnetic field.
Because of the tendency of eddy currents to oppose, eddy currents cause energy to be lost. More accurately, eddy currents transform more useful forms of energy, such as kinetic energy, into heat, which is generally much less useful. In many applications the loss of useful energy is not particularly desirable, but there are some practical applications. One is in the brakes of some trains. During braking, the metal wheels are exposed to a magnetic field from an electromagnet, generating eddy currents in the wheels. The magnetic interaction between the applied field and the eddy currents acts to slow the wheels down. The faster the wheels are spinning, the stronger the effect, meaning that as the train slows the braking force is reduced, producing a smooth stopping motion.
An electric generator
A electric motor is a device for transforming electrical energy into mechanical energy; an electric generator does the reverse, using mechanical energy to generate electricity. At the heart of both motors and generators is a wire coil in a magnetic field. In fact, the same device can be used as a motor or a generator.
When the device is used as a motor, a current is passed through the coil. The interaction of the magnetic field with the current causes the coil to spin. To use the device as a generator, the coil can be spun, inducing a current in the coil.
An AC (alternating current) generator utilizes Faraday's law of induction, spinning a coil at a constant rate in a magnetic field to induce an oscillating emf. The coil area and the magnetic field are kept constant, so, by Faraday's law, the induced emf is given by:
If the loop spins at a constant rate, . Using calculus, and taking the derivative of the cosine to get a sine (as well as bringing out a factor of ), it's easy to show that the emf can be expressed as:
The combination represents the maximum value of the generated voltage (i.e., emf) and can be shortened to . This reduces the expression for the emf to:
In other words, a coil of wire spun in a magnetic field at a constant rate will produce AC electricity. In North America, AC electricity from a wall socket has a frequency of 60 Hz.
A coil turning in a magnetic field can also be used to generate DC power. A DC generator uses the same kind of split-ring commutator used in a DC motor. Unlike the AC generator, the polarity of the voltage generated by a DC generator is always the same. In a very simple DC generator with a single rotating loop, the voltage level would constantly fluctuate. The voltage from many loops (out of synch with each other) is usually added together to obtain a relatively steady voltage.
Rather than using a spinning coil in a constant magnetic field, another way to utilize electromagnetic induction is to keep the coil stationary and to spin permanent magnets (providing the magnetic field and flux) around the coil. A good example of this is the way power is generated, such as at a hydro-electric power plant. The energy of falling water is used to spin permanent magnets around a fixed loop, producing AC power.
Back EMF in electric motors
You may have noticed that when something like a refrigerator or an air conditioner first turns on in your house, the lights dim momentarily. This is because of the large current required to get the motor inside these machines up to operating speed. When the motors are turning, much less current is necessary to keep them turning.
One way to analyze this is to realize that a spinning motor also acts like a generator. A motor has coils turning inside magnetic fields, and a coil turning inside a magnetic field induces an emf. This emf, known as the back emf, acts against the applied voltage that's causing the motor to spin in the first place, and reduces the current flowing through the coils. At operating speed, enough current flows to overcome any losses due to friction and to provide the necessary energy required for the motor to do work. This is generally much less current than is required to get the motor spinning in the first place.
If the applied voltage is V, then the initial current flowing through a motor with coils of resistance R is I = V / R. When the motor is spinning and generating a back emf, the current is reduced:
Mutual inductance
Faraday's law tells us that a changing magnetic flux will induce an emf in a coil. The induced emf for a coil with N loops is:
Picture two coils next to each other, end to end. If the first coil has
a current going through it,a magnetic field will be produced, and a
magnetic flux will pass through the second coil. Changing the current
in the first coil changes the flux through the second, inducing an emf
in the second coil. This is known as mutual inductance, inducing an emf
in one coil by changing the current through another. The induced emf is
proportional to the change in flux,which is proportional to the change
in current in the first coil. The induced emf can thus be written as:
The constant M is the mutual inductance, which depends on various factors, including the area and number of turns in coil 2, the distance between the two coils (the further apart, the less flux passes through coil 2), the relative orientation of the two coils, the number of turns / unit length in the first coil (because that's what the magnetic field produced by the first coil depends on), and whether the two coils have cores made from ferromagentic material. In other words, M is rather complicated. What's far more important in the equation above is that the emf induced in the second coil is proportional to the change in current in the first.
This effect can be put to practical use. One way to use it is in a transformer, which we'll discuss below. Another is to use it in an ammeter. Conventional ammeters are incorporated directly into circuits, but ammeters don't have to be placed in the current path for alternating current. If a loop connected to a meter is placed around a wire with an AC current in it, an emf will be induced in the loop because of the changing field from the wire, and that will produce a current in the loop, and meter, proportional to the current in the wire.
Self inductance
Coils can also induce emf's in themselves. If a changing current is passed through a coil, a changing magnetic field will be produced, inducing an emf in the coil. Again, this emf is given by:
As with mutual inductance, the induced emf is proportional to the change in current. The induced emf can be written as:
The constant L is known as the inductance of the coil. It depends on
the coil geometry, as well as on whether the coil has a core of
ferromagnetic material.
We've already discussed resistors and capacitors as circuit
elements. Inductors, which are simply wire coils, often with
ferromagnetic cores, are another kind of circuit element. One of the
main differences between these is what happens to electrical energy in
them. Resistors dissipate electrical energy in the form of heat;
capacitors store the energy in an electric field between the capacitor
plates; and inductors store the energy in the magnetic field in the
coil. The energy stored in an inductor is:
In general, the energy density (energy per unit volume) in a magnetic field is:
Transformers
Electricity is often generated a long way from where it is used, and is transmitted long distances through power lines. Although the resistance of a short length of power line is relatively low, over a long distance the resistance can become substantial. A power line of resistance R causes a power loss of I2R ; this is wasted as heat. By reducing the current, therefore, the I2R losses can be minimized.
At the generating station, the power generated is given by P = VI. To reduce the current while keeping the power constant, the voltage can be increased. Using AC power, and Faraday's law of induction, there is a very simple way to increase voltage and decrease current (or vice versa), and that is to use a transformer. A transformer is made up of two coils, each with a different number of loops, linked by an iron core so the magnetic flux from one passes through the other. When the flux generated by one coil changes (as it does continually if the coil is connected to an AC power source), the flux passing through the other will change, inducing a voltage in the second coil. With AC power, the voltage induced in the second coil will also be AC.
In a standard transformer, the two coils are usually wrapped around the same iron core, ensuring that the magnetic flux is the same through both coils. The coil that provides the flux (i.e., the coil connected to the AC power source) is known as the primary coil, while the coil in which voltage is induced is known as the secondary coil. If the primary coil sets up a changing flux, the voltage in the secondary coil depends on the number of turns in the secondary:
Similarly, the relationship for the primary coil is:
Combining these gives the relationship between the primary and secondary voltage:
Energy (or, equivalently, power) has to be conserved, so:
If a transformer takes a high primary voltage and converts it to a low secondary voltage, the current in the secondary will be higher than that in the primary to compensate (and vice versa). A transformer in which the voltage is higher in the primary than the secondary (i.e., more turns in the primary than the secondary) is known as a step-down transformer. A transformer in which the secondary has more turns (and, therefore, higher voltage) is known as a step-up transformer.
Power companies use step-up transformers to boost the voltage to hundreds of kV before it is transmitted down a power line, reducing the current and minimizing the power lost in transmission lines. Step-down transformers are used at the other end, to decrease the voltage to the 120 or 240 V used in household circuits.
Transformers require a varying flux to work. They are therefore perfect for AC power, but do not work at all for DC power, which would keep the flux constant. The ease with which voltage and current can be tranformed in an AC circuit is a large part of the reason AC power, rather than DC, is distributed by the power companies.
Although transformers dramatically reduce the energy lost to I2R heating in power line, they don't give something for nothing. Transformers will also dissipate some energy, in the form of:
1. flux leakage - not all the magnetic flux from the primary passes through the secondary
2. self-induction - the opposition of the coils to a changing flux in them
3. heating losses in the coils of the transformer
4. eddy currents
In the iron core of a transformer, electrons would swirl in cross-sectional planes. This current would heat up the transformer, wasting power as heat. To minimize power losses due to eddy currents, the iron core is usually made up of thin laminated slices, rather than one solid piece. Current is then confined within each laminated piece, significantly reducing the swirling tendency as well as the losses by heating.
Subject:
Subject X2:
Energy and Momentum
Subject:
Subject X2:
Applying energy concepts
10-15-99
Section 6.9
With energy, we've got another tool in our physics toolbox to use to attack problems. Let's try some more examples to see how these energy concepts are applied.
Air resistance
Air resistance can be a tricky thing to account for. Generally, the force applied by air to a moving object is proportional to the square of the speed of the object. We know how to handle constant forces, but a force that depends on speed is a different story. If we apply energy to the problem, however, we can make some headway.
Take, for instance, a simple coffee filter. It's very light, and has a relatively large surface area. If you let a coffee filter fall, it falls at roughly constant speed; this is because the force of gravity is balanced by the force of air resistance. Note that the constant speed is known as the terminal velocity - the same kind of thing applies to skydivers. Let's say we drop a coffee filter (from rest) from a height of 1.5 m. If there was no air resistance, the filter would take about 0.55 seconds to hit the ground, and be traveling at a final speed of 5.4 m/s.
The actual time for a coffee filter to fall 1.5 m is more like 1.5 seconds (try timing it yourself). Doing some estimating, making the assumption that the speed is constant over this time interval gives a speed of 1.0 m/s. How much work is done by air resistance? Approximately what is the force of air resistance on the filter?
Applying conservation of energy makes it easy to determine the work done. This is as long as the mass is known - weighing a stack of filters on a balance, I found that one filter weighs approximately 1 gram. This gives the coffee filter an initial potential energy, relative to the floor, of 0.001 x 1.5 x 9.8 which is approximately 0.015 J. When it hits the ground the kinetic energy is 0.0005 J. Clearly, energy has been lost - in fact, almost all the energy has been lost! The work done by friction equals the change in energy, so it's almost -0.015 J. It's negative because it opposes the motion: the displacement is down and the force is up.
The work is the force times the displacement. The average force in this case is therefore about 0.01 N. This is the same answer you get if you set the gravitational force equal to the force of air resistance, so that's a good sign that we're doing things correctly.
n example, using the PE of a spring
A 0.123 kg block sits on a plane inclined at 20°. The block is pushed back against a spring (k = 23.4 N / m), compressing the spring by 0.345 m. When the block is let go, it is accelerated up the incline by the spring. The coefficient of kinetic friction between the block and the incline is 0.220.
How far up the incline does the block go?
Attack this problem using work and energy. The initial energy (stored in the spring) is equal to the final energy (gravitational PE) plus whatever gets lost to friction. Writing this as an equation gives:
Energy before = energy after + energy lost to friction
A free-body diagram tells us that:
Substituting this in to transforms the energy equation to:
Solving this for d, the distance the block travels up the slope, gives:
Plugging in all the numbers gives:
Subject:
Subject X2:
Collisions in Two Dimensions
A 2-D collision
Because momentum is a vector, whenever we analyze a collision in two or three dimensions the momentum has to be split up into components. Consider the following example to see how this works. A 1000 kg car traveling at 30 m/s, 30° south of east, collides with a 3000 kg truck heading northeast at 20 m/s. The collision is completely inelastic, so the two vehicles stick together after the collision. How fast, and in what direction, are the car and truck traveling after the collision?
To solve this problem, simply set up two conservation of momentum equations, one for the y-direction (positive y being north) and another for the x-direction (positive x being east). Setting up a vector diagram for the momentum is a good idea, too, like this:

To set up the two momentum conservation equations, simply write down
the equation for the momentum before the collision in the y-direction
and set it equal to the momentum after the collision in the
y-direction, and then do the same thing in the x-direction.
![]()
The y equation can be rearranged to solve for the y component of the final velocity:
![]()
Similarly, in the x-direction:
![]()
It would be easy to figure out the final velocity using the Pythagorean
theorem, but let's find the angle first instead, by dividing the y equation by the x equation:
![]()
Now let's go back to get the final velocity from the Pythagorean theorem :
![]()
This gives a final velocity of 18.4 m/s at an angle of 21.8° north of east.
We could figure out how much energy is lost during the collision if we wanted to; because energy is a scalar rather than a vector, this is done the same way in 2-D (and 3-D) as it is in 1-D.
Subject:
Subject X2:
Conservation of energy
10-13-99
Sections 6.5 - 6.8
The conservation of mechanical energy
Mechanical energy is the sum of the potential and kinetic energies in a system. The principle of the conservation of mechanical energy states that the total mechanical energy in a system (i.e., the sum of the potential plus kinetic energies) remains constant as long as the only forces acting are conservative forces. We could use a circular definition and say that a conservative force as a force which doesn't change the total mechanical energy, which is true, but might shed much light on what it means.
A good way to think of conservative forces is to consider what happens on a round trip. If the kinetic energy is the same after a round trip, the force is a conservative force, or at least is acting as a conservative force. Consider gravity; you throw a ball straight up, and it leaves your hand with a certain amount of kinetic energy. At the top of its path, it has no kinetic energy, but it has a potential energy equal to the kinetic energy it had when it left your hand. When you catch it again it will have the same kinetic energy as it had when it left your hand. All along the path, the sum of the kinetic and potential energy is a constant, and the kinetic energy at the end, when the ball is back at its starting point, is the same as the kinetic energy at the start, so gravity is a conservative force.
Kinetic friction, on the other hand, is a non-conservative force, because it acts to reduce the mechanical energy in a system. Note that non-conservative forces do not always reduce the mechanical energy; a non-conservative force changes the mechanical energy, so a force that increases the total mechanical energy, like the force provided by a motor or engine, is also a non-conservative force.
An example
Consider a person on a sled sliding down a 100 m long hill on a 30° incline. The mass is 20 kg, and the person has a velocity of 2 m/s down the hill when they're at the top. How fast is the person traveling at the bottom of the hill? All we have to worry about is the kinetic energy and the gravitational potential energy; when we add these up at the top and bottom they should be the same, because mechanical energy is being conserved.
At the top: PE = mgh = (20) (9.8) (100sin30°) = 9800 J
KE = 1/2 mv2 = 1/2 (20) (2)2 = 40 J
Total mechanical energy at the top = 9800 + 40 = 9840 J
At the bottom: PE = 0 KE = 1/2 mv2
Total mechanical energy at the bottom = 1/2 mv2
If we conserve mechanical energy, then the mechanical energy at the top must equal what we have at the bottom. This gives:
1/2 mv2 = 9840, so v = 31.3 m/s.
Modifying the example
Now let's worry about friction in this problem. Let's say, because of friction, the velocity at the bottom of the hill is 10 m/s. How much work is done by friction, and what is the coefficient of friction?
The sled has less mechanical energy at the bottom of the slope than at the top because some energy is lost to friction (the energy is transformed into heat, in other words). Now, the energy at the top plus the work done by friction equals the energy at the bottom.
Energy at the top = 9840 J
Energy at the bottom = 1/2 mv2 = 1000 J
Therefore, 9840 + work done by friction = 1000, so friction has done -8840 J worth of work on the sled. The negative sign makes sense because the frictional force is directed opposite to the way the sled is moving.
How large is the frictional force? The work in this case is the negative of the force multiplied by the distance traveled down the slope, which is 100 m. The frictional force must be 88.4 N.
To calculate the coefficient of friction, a free-body diagram is required.
In the y-direction, there is no acceleration, so:
The coefficient of kinetic friction is the frictional force divided by the normal force, so it's equal to 88.4 / 169.7 = 0.52.
Subject:
Subject X2:
Momentum
Momentum
There are two kinds of momentum, linear and angular. A spinning object has angular momentum; an object traveling with a velocity has linear momentum. For now, and throughout chapter 7, we'll deal with linear momentum, and just refer to it as momentum, without the linear.
There are 4 really important things to know about momentum. The first is how momentum is defined, as the product of mass times velocity:
momentum : p = mv
The second note is built into this equation; momentum is a vector, and the momentum has the same direction as the velocity.
The third point is the relationship between momentum and force. We've talked a lot about forces in the last few weeks, and there is a strong connection between force and momentum. In fact, Newton's second law was first written (by Newton himself, of course) in terms of momentum, rather than acceleration. A force acting for a certain time (this is known as an impulse) produces a change in momentum.
![]()
Again, this is a vector equation, so the change in momentum is in the same direction as the force.
The fourth really important point about momentum is that momentum is conserved; the total momentum of an isolated system is constant. Note that "isolated" means that no external force acts on the system, which is a set of interacting objects. If a system does have a net force acting, then the momentum changes according to the impulse equation.
Momentum conservation applies to a single object, but it's a lot more interesting to look at a situation with at least two interacting objects. If two objects (a car and a truck, for example) collide, momentum will always be conserved. There are three different kinds of collisions, however, elastic, inelastic, and completely inelastic. Just to restate, momentum is conserved in all three kinds of collisions. What distinguishes the collisions is what happens to the kinetic energy.
Types of collisions: (momentum is conserved in each case)
* elastic - kinetic energy is conserved
* inelastic - kinetic energy is not conserved
* completely inelastic - kinetic energy is not conserved, and the colliding objects stick together after the collision.
The total energy is always conserved, but the kinetic energy does not have to be; kinetic energy is often transformed to heat or sound during a collision.
1-D collision example
A car of mass 1000 kg travels east at 30 m/s, and collides with a 3000 kg truck traveling west at 20 m/s.
(a) If the collision is completely inelastic, how fast are the car and truck going, and in what direction, after the collision? What percentage of the kinetic energy is lost in the collision?
(b) What happens if the collision is elastic?
(a) Car crashes are often completely inelastic, with much of the kinetic energy going into deforming the cars. Momentum is always conserved, though, so, using c for car and t for truck, (and f for final) the conservation of momentum equation is:
![]()
If we take east as the positive direction, then the truck's velocity goes into the equation with a negative sign, so: vf = [ (1000) (30) + (3000) (-20) ] / (1000 + 3000) = -7.5 m/s, which is 7.5 m/s west
The change in kinetic energy can be found by adding up the kinetic energy before and after the collision:
![]()
KE lost = 1050000 - 112500 = 937500 J
Percentage of KE lost = 100% x 937500 / 1050000 = 89.3%
So, a great deal of the kinetic energy is lost in the collision.
(b) What would happen if the car and truck were both made out of rubber and the collision was elastic, with no loss of kinetic energy. In this case the calculations are a lot more complicated, because we have to combine the energy conservation equation with the momentum conservation equation:
![]()
In this case, after some nice algebraic manipulation (which is worth trying on your own), the final velocities of the car and truck work out to:
![]()
Note that if you were driving the car, you would experience a much greater force in the case of an elastic collision than in a completely inelastic collision, in which much of the energy is absorbed by the deformation of the car. Let's say you have a mass of 50 kg, and that the collision lasts for 0.1 seconds. In the case of the completely inelastic collision, your momentum would change from 50 kg x 30 m/s east = 1500 kg m/s east to 50 kg x 7.5 m/s west = -375 kg m/s east, which is a net change of 1875 kg m/s. This change in momentum is produced by an average force acting for the 0.1 s of the collision, so the force works out to 18750 N.
In the elastic collision, your momentum would change from 1500 kg m/s east to 50 kg x 45 m/s west = -2250 kg m/s east, for a net change of 3750 kg m/s, exactly twice that in the completely inelastic case. The force you would experience would therefore also be doubled.
Back to impulse
Before doing an example of a collision in 2 dimensions, let's look at a short example of how the impulse equation is applied. Recall that impulse is a force acting for a particular time, producing a change in momentum:
![]()
Consider a hose spraying water directly at a wall. If 3 kg of water emerge from the hose every second, and the speed of the water is 10 m/s, how much force is exerted on the wall by the water?
The first step in coming to an answer is making an assumption, that the water does not bounce back from the wall, but is simply stopped by the wall. In this case, the change in momentum for one second's worth of water is -30 kg m/s. To produce this change in momentum, the wall must exert a force on the water of -30 N, which is 30 N in the direction opposite to the direction the water travels from the hose. The water exerts an equal and opposite force on the wall, 30 N in the direction the hose points.
Note that is the water bounced off the wall and came back with a momentum of 30 kg m/s towards the hose, that would represent a net change in momentum of 60 kg m/s towards the hose, because momentum is a vector. In that case the force exerted by the water on the wall would be twice as high, 60 N.
Subject:
Subject X2:
Power
10-18-99
Section 6.10
Power
Being able to do work is not just what's important; how fast you can do work is also an important factor. Power is the measure of how fast work is done. Computers have more calculating power than we do; a sports car generally has a more powerful engine than an economy car. Power is the rate at which work is done and the rate at which energy is used. The unit for power is the watt (W).
An interesting calculation is the average power output of a human being. This can be determined from the amount of energy we consume in a day in the way of food. Most of us take in something like 2500 "calories" in a day, although what we call calories is really a kilocalorie; assuming we use up all this energy in a day (a reasonable assumption considering we'll have to eat tomorrow, too) we can use this as our energy output per day.
First, take the 2.5 x 106 cal and convert to Joules, using the conversion factor 4.18 J / cal. This gives roughly 1 x 107 J. Figuring out our average power output, we simply divide the energy by the number of seconds in a day, 86400, which gives a bit more than 100 W. In other words, on the average, we're just a little brighter than your average light bulb.
alculating power from speed
Power is work over time, and work is force multiplied by distance. Power can be written as:
Power : P = F s / t (F is the force in the direction of s, the displacement)
Displacement over time is velocity, so power can also be written in this form:
Power : P = F v (F is the force in the direction of the velocity)
Here's an example of when you might use this. Let's say you're riding your bicycle on a level road at a constant speed of 10 m/s. You're riding into a headwind, and you're burning up energy at the rate of 500 J/s. If you assume that 80% of this energy is going to overcome air resistance, how much force is the air exerting on you?
The power used to overcome air resistance is 80% of 500 W, which is 400 W. Assuming there aren't any other forces acting against you, then dividing this by your speed should give you the force the air exerts on you. This works out to 40 N.
xample - A car climbing a hill
A car with a mass of 900 kg climbs a 20° incline at a steady speed of 60 km/hr. If the total resistance forces acting on the car add to 500 N, what is the power output of the car in watts? In horsepower?
Note that the gravitational force is the only force which needs to be split into components. mg sin20° acts down the slope; mg cos20° acts into the slope. Fr represents the resistance forces.
A good place to start here is with the free-body diagram. The power output by the car's engine goes into the force directed up the slope. This force is actually static friction exerted on the drive wheels by the road - the road exerts this force because the engine causes the drive wheels to rotate.
The velocity is constant, so the forces must balance. Applying Newton's second law in the x-direction gives:
F - Fr - mg sin20° = 0
The force up the slope is then F =Fr + mg sin20° = 500 + 3017 = 3517 N
Converting the car's speed to m/s gives 16.67 m/s. The power output can then be found from
P = Fv = (3517) (16.67) = 58620 W.
This can be converted to horsepower, using the conversion 746 W = 1 hp. This gives a power output of 78.6 hp.
Most cars have engines with power outputs of about 100 hp, so this is a reasonable value (and there's nothing in the question to say that this has to be the maximum power output of the car).
Subject:
Subject X2:
Work and energy
10-8-99
Sections 6.1 - 6.4
Energy gives us one more tool to use to analyze physical situations. When forces and accelerations are used, you usually freeze the action at a particular instant in time, draw a free-body diagram, set up force equations, figure out accelerations, etc. With energy the approach is usually a little different. Often you can look at the starting conditions (initial speed and height, for instance) and the final conditions (final speed and height), and not have to worry about what happens in between. The initial and final information can often tell you all you need to know.
Work and energy
Whenever a force is applied to an object, causing the object to move, work is done by the force. If a force is applied but the object doesn't move, no work is done; if a force is applied and the object moves a distance d in a direction other than the direction of the force, less work is done than if the object moves a distance d in the direction of the applied force.
The physics definition of "work" is:
The unit of work is the unit of energy, the joule (J). 1 J = 1 N m.
Work can be either positive or negative: if the force has a component in the same direction as the displacement of the object, the force is doing positive work. If the force has a component in the direction opposite to the displacement, the force does negative work.
If you pick a book off the floor and put it on a table, for example, you're doing positive work on the book, because you supplied an upward force and the book went up. If you pick the book up and place it gently back on the floor again, though, you're doing negative work, because the book is going down but you're exerting an upward force, acting against gravity. If you move the book at constant speed horizontally, you don't do any work on it, despite the fact that you have to exert an upward force to counter-act gravity.
Kinetic energy
An object has kinetic energy if it has mass and if it is moving. It is energy associated with a moving object, in other words. For an object traveling at a speed v and with a mass m, the kinetic energy is given by:
The work-energy principle
There is a strong connection between work and energy, in a sense that when there is a net force doing work on an object, the object's kinetic energy will change by an amount equal to the work done:
Note that the work in this equation is the work done by the net force, rather than the work done by an individual force.
Gravitational potential energy
Let's say you're dropping a ball from a certain height, and you'd like to know how fast it's traveling the instant it hits the ground. You could apply the projectile motion equations, or you could think of the situation in terms of energy (actually, one of the projectile motion equations is really an energy equation in disguise).
If you drop an object it falls down, picking up speed along the way. This means there must be a net force on the object, doing work. This force is the force of gravity, with a magnitude equal to mg, the weight of the object. The work done by the force of gravity is the force multiplied by the distance, so if the object drops a distance h, gravity does work on the object equal to the force multiplied by the height lost, which is:
work done by gravity = W = mgh (h = height lost by the object)
An alternate way of looking at this is to call this the gravitational potential energy. An object with potential energy has the potential to do work. In the case of gravitational potential energy, the object has the potential to do work because of where it is, at a certain height above the ground, or at least above something.
Spring potential energy
Energy can also be stored in a stretched or compressed spring. An ideal spring is one in which the amount the spring stretches or compresses is proportional to the applied force. This linear relationship between the force and the displacement is known as Hooke's law. For a spring this can be written:
F = kx, where k is known as the spring constant.
k is a measure of how difficult it is to stretch a spring. The larger k is, the stiffer the spring is and the harder the spring is to stretch.
If an object applies a force to a spring, the spring applies an equal and opposite force to the object. Therefore:
force applied by a spring : F = - kx
where x is the amount the spring is stretched. This is a restoring force, because when the spring is stretched, the force exerted by by the spring is opposite to the direction it is stretched. This accounts for the oscillating motion of a mass on a spring. If a mass hanging down from a spring is pulled down and let go, the spring exerts an upward force on the mass, moving it back to the equilibrium position, and then beyond. This compresses the spring, so the spring exerts a downward force on the mass, stopping it, and then moving it back to the equilibrium and beyond, at which point the cycle repeats. This kind of motion is known as simple harmonic motion, which we'll come back to later in the course.
The potential energy stored in a spring is given by:
where x is the difference between the spring's length and its unstrained length.
In a perfect spring, no energy is lost; the energy is simply transferred back and forth between the kinetic energy of the mass on the spring and the potential energy of the spring (gravitational PE might be involved, too).
Conservation of energy
We'll take all of the different kinds of energy we know about, and even all the other ones we don't, and relate them through one of the fundamental laws of the universe.
The law of conservation of energy states that energy can not be created or destroyed, it can merely be changed from one form of energy to another. Energy often ends up as heat, which is thermal energy (kinetic energy, really) of atoms and molecules. Kinetic friction, for example, generally turns energy into heat, and although we associate kinetic friction with energy loss, it really is just a way of transforming kinetic energy into thermal energy.
The law of conservation of energy applies always, everywhere, in any situation. There is another conservation idea associated with energy which does not apply as generally, and is therefore called a principle rather than a law. This is the principle of the conservation of mechanical energy.
Subject:
Subject X2:
Fluids
Subject:
Subject X2:
Fluid dynamics and Bernoulli's equation
11-10-99
Sections 10.7 - 10.9
Moving fluids
Fluid dynamics is the study of how fluids behave when they're in motion. This can get very complicated, so we'll focus on one simple case, but we should briefly mention the different categories of fluid flow.
Fluids can flow steadily, or be turbulent. In steady flow, the fluid passing a given point maintains a steady velocity. For turbulent flow, the speed and or the direction of the flow varies. In steady flow, the motion can be represented with streamlines showing the direction the water flows in different areas. The density of the streamlines increases as the velocity increases.
Fluids can be compressible or incompressible. This is the big difference between liquids and gases, because liquids are generally incompressible, meaning that they don't change volume much in response to a pressure change; gases are compressible, and will change volume in response to a change in pressure.
Fluid can be viscous (pours slowly) or non-viscous (pours easily).
Fluid flow can be rotational or irrotational. Irrotational means it travels in straight lines; rotational means it swirls.
For most of the rest of the chapter, we'll focus on irrotational, incompressible, steady streamline non-viscous flow.
The equation of continuity
The equation of continuity states that for an incompressible fluid flowing in a tube of varying cross-section, the mass flow rate is the same everywhere in the tube. The mass flow rate is simply the rate at which mass flows past a given point, so it's the total mass flowing past divided by the time interval. The equation of continuity can be reduced to:
Generally, the density stays constant and then it's simply the flow rate (Av) that is constant.
Making fluids flow
There are basically two ways to make fluid flow through a pipe. One way is to tilt the pipe so the flow is downhill, in which case gravitational kinetic energy is transformed to kinetic energy. The second way is to make the pressure at one end of the pipe larger than the pressure at the other end. A pressure difference is like a net force, producing acceleration of the fluid.
As long as the fluid flow is steady, and the fluid is non-viscous and incompressible, the flow can be looked at from an energy perspective. This is what Bernoulli's equation does, relating the pressure, velocity, and height of a fluid at one point to the same parameters at a second point. The equation is very useful, and can be used to explain such things as how airplanes fly, and how baseballs curve.
Bernoulli's equation
The pressure, speed, and height (y) at two points in a steady-flowing, non-viscous, incompressible fluid are related by the equation:
Some of these terms probably look familiar...the second term on each side looks something like kinetic energy, and the third term looks a lot like gravitational potential energy. If the equation was multiplied through by the volume, the density could be replaced by mass, and the pressure could be replaced by force x distance, which is work. Looked at in that way, the equation makes sense: the difference in pressure does work, which can be used to change the kinetic energy and/or the potential energy of the fluid.
Pressure vs. speed
Bernoulli's equation has some surprising implications. For our first look at the equation, consider a fluid flowing through a horizontal pipe. The pipe is narrower at one spot than along the rest of the pipe. By applying the continuity equation, the velocity of the fluid is greater in the narrow section. Is the pressure higher or lower in the narrow section, where the velocity increases?
Your first inclination might be to say that where the velocity is greatest, the pressure is greatest, because if you stuck your hand in the flow where it's going fastest you'd feel a big force. The force does not come from the pressure there, however; it comes from your hand taking momentum away from the fluid.
The pipe is horizontal, so both points are at the same height. Bernoulli's equation can be simplified in this case to:
The kinetic energy term on the right is larger than the kinetic energy term on the left, so for the equation to balance the pressure on the right must be smaller than the pressure on the left. It is this pressure difference, in fact, that causes the fluid to flow faster at the place where the pipe narrows.
A geyser
Consider a geyser that shoots water 25 m into the air. How fast is the water traveling when it emerges from the ground? If the water originates in a chamber 35 m below the ground, what is the pressure there?
To figure out how fast the water is moving when it comes out of the ground, we could simply use conservation of energy, and set the potential energy of the water 25 m high equal to the kinetic energy the water has when it comes out of the ground. Another way to do it is to apply Bernoulli's equation, which amounts to the same thing as conservation of energy. Let's do it that way, just to convince ourselves that the methods are the same.
Bernoulli's equation says:
But the pressure at the two points is the same; it's atmospheric
pressure at both places. We can measure the potential energy from
ground level, so the potential energy term goes away on the left side,
and the kinetic energy term is zero on the right hand side. This
reduces the equation to:
The density cancels out, leaving:
This is the same equation we would have found if we'd done it using
the chapter 6 conservation of energy method, and canceled out the mass.
Solving for velocity gives v = 22.1 m/s.
To determine the pressure 35 m below ground, which forces the
water up, apply Bernoulli's equation, with point 1 being 35 m below
ground, and point 2 being either at ground level, or 25 m above ground.
Let's take point 2 to be 25 m above ground, which is 60 m above the
chamber where the pressurized water is.
We can take the velocity to be zero at both points (the acceleration
occurs as the water rises up to ground level, coming from the
difference between the chamber pressure and atmospheric pressure). The
pressure on the right-hand side is atmospheric pressure, and if we
measure heights from the level of the chamber, the height on the left
side is zero, and on the right side is 60 m.
This gives:
Why curveballs curve
Bernoulli's equation can be used to explain why curveballs curve. Let's say the ball is thrown so it spins. As air flows over the ball, the seams of the ball cause the air to slow down a little on one side and speed up a little on the other. The side where the air speed is higher has lower pressure, so the ball is deflected toward that side. To throw a curveball, the rotation of the ball should be around a vertical axis.
It's a little more complicated than that, actually. Although the
picture here shows nice streamline flow as the air moves left relative
to the ball, in reality there is some turbulence. The air does exert a
force down on the ball in the figure above, so the ball must exert an
upward force on the air. This causes air that travels below the ball in
the picture to move up and fill the space left by the ball as it moves
by, which reduces drag on the ball.
Subject:
Subject X2:
Pressure and buoyancy
11-12-99
Sections 10.1 - 10.6
What is a fluid?
You probably think of a fluid as a liquid, but a fluid is simply anything that can flow. This includes liquids, but gases are fluids too.
Mass density
When we talk about density it's usually mass density we're referring to. The mass density of an object is simply its mass divided by its volume. The symbol for density is the Greek letter rho, r :
Density depends on a few basic things. On a microscopic level, the density of an object depends on the weight of the individual atoms and molecules making up the object, and how much space there is between them. On a large-scale level, density depends on whether the object is solid, hollow, or something in between.
In general, liquids and solids have similar densities, which are of the order of 1000 kg / m3. Water at 4° C has a density of exactly this value; very dense materials like lead and gold have densities which are 10 - 20 times larger. Gases, on the other hand, have densities around 1 kg / m3, or about 1/1000 as much as water.
Densities are often given in terms of specific gravity. The specific gravity of an object or a material is the ratio of its density to the density of water at 4° C (this temperature is used because this is the temperature at which water is most dense). Gold has a specific gravity of 19.3, aluminum 2.7, and mercury 13.6. Note that these values are at standard temperature and pressure; objects will change size, and therefore density, in response to a change in temperature or pressure.
Pressure
Density depends on pressure, but what exactly is pressure? Pressure is simply the force experienced by an object divided by the area of the surface on which the force acts. Note that the force here is the force acting perpendicular to the surface.
Pressure : P = F / A (The force is applied perpendicular to the area A)
The unit for pressure is the pascal, Pa. Pressure is often measured in other units (atmospheres, pounds per square inch, millibars, etc.), but the pascal is the unit that goes with the MKS (meter-kilogram-second) system.
When we talk about atmospheric pressure, we're talking about the pressure exerted by the weight of the air above us. The air goes up a long way, so even though it has a low density it still exerts a lot of pressure:
On every square meter at the Earth's surface, then, the atmosphere exerts about 1.0 x 105 N of force. This is very large, but it is not usually noticed because there is generally air both inside and outside of things, so the forces applied by the atmosphere on each side of an object balance. It is when there are differences in pressure on two sides that atmospheric pressure becomes important. A good example is when you drink using a straw: you reduce the pressure at the top of the straw, and the atmosphere pushes the liquid up the straw and into your mouth.
Pressure vs. depth in a static fluid
The pressure at any point in a static fluid depends only on the pressure at the top of the fluid and the depth of the point in the fluid. If point 2 lies a vertical distance h below point 1, there is a higher pressure at point 2; the pressure at the two points is related by the equation:
Note that point 2 does not have to be directly below point 1; it is simply a vertical distance below point 1. This means that every point at a particular depth in a static fluid is at the same pressure.
Pascal's principle
Pascal's principle can be used to explain how hydraulic systems work. A common example of such a system is the lift used to raise a car off the ground so it can be repaired at a garage.
Pascal's principle : Pressure applied to an enclosed fluid is transmitted undiminished to every part of the fluid, as well as to the walls of the container.
In a hydraulic lift, a small force applied to a small-area piston is transformed to a large force at a large-area piston. If a car sits on top of the large piston, it can be lifted by applying a relatively small force, the ratio of the forces being equal to the ratio of the areas of the pistons.
Even though the force can be much less, the work done is the same. Work is force times the distance, so if the force on the large piston is 10 times larger than the force on the smaller piston, the distance it travels is 10 times smaller.
Measuring pressure
The relationship between pressure and depth is often exploited in instruments that measure pressure. Two pressure gauges based on this principle are the closed-tube manometer and the open-tube manometer, which measure pressure by comparing the pressure at one end of the tube with a known pressure at the other end.
A standard mercury barometer is a closed-tube manometer, with one end sealed. The sealed end is close to zero pressure, while the other end is open to the atmosphere, or is connected to where the pressure is being measured. Because there is a pressure difference between the two ends of the tube, a column of fluid can be maintained in the tube, with the height of the column proportional to the pressure difference. If the closed end is at zero pressure, then the height of the column is proportional to the pressure at the other end.
In an open-tube manometer, one end of the tube is open to the
atmosphere, and is thus at atmospheric pressure. The other end is
connected to a region where the pressure is to be measured. Again, if
there is a difference in pressure between the two ends of the tube, a
column of fluid can be supported in the tube, with the height of the
column being proportional to the pressure difference.
The actual pressure, P2, is known as the absolute pressure; the pressure difference between the absolute pressure and atmospheric pressure is called the gauge pressure. Many pressure gauges give only the gauge pressure.
Eureka!
According to legend, this is what Archimedes' cried when he discovered an important fact about buoyancy, so important that we call it Archimedes' principle (and so important that Archimedes allegedly jumped from his bath and ran naked through the streets after figuring it out).
Archimedes principle : An object that is partly or completely submerged in a fluid will experience a buoyant force equal to the weight of the fluid the object displaces.
The buoyant force applied by the fluid on the object is directed up. The force comes from the difference in pressure exerted on the top and bottom of an object. For a floating object, the top surface is at atmospheric pressure, while the bottom surface is at a higher pressure because it is in contact with the fluid at a particular depth in the fluid, and pressure increases with depth. For a completely-submerged object, the top surface is no longer at atmospheric pressure, but the bottom surface is still at a higher pressure because it's deeper in the fluid. In both cases, the difference in pressure results in a net upward force (the buoyant force) on the object.
Example
A basketball floats in a bathtub of water. The ball has a mass of 0.5 kg and a diameter of 22 cm.
(a) What is the buoyant force?
(b) What is the volume of water displaced by the ball?
(c) What is the average density of the basketball?
(a) To find the buoyant force, simply draw a free-body diagram. The ball floats on the water, so there is no net force: the weight is balanced by the buoyant force, so:
(b) By Archimedes' principle, the buoyant force is equal to the weight
of fluid displaced. The weight is the mass times g, and the mass is the
density times the volume, so:
and then the volume displaced is simply:
(c) To find the density of the ball, we need to determine the volume. This is given by:
The density is then just the mass divided by this volume, so:
Another way to find density is to use the volume of displaced fluid.
For a floating object, the weight of the object equals the buoyant
force, which equals the weight of the displaced fluid. Canceling out a
factor of g gives:
So the density is:
The basketball is much less dense than water because it is filled with
air. An object (or a fluid) will float on a fluid if its density is
less than that of the fluid; if its density is larger than the fluid's,
it will sink.
Subject:
Subject X2:
Viscosity and surface tension
11-15-99
Sections 10.10 - 10.13
Real-life fluids
Real-life fluids, like air, water, oil, blood, shampoo, or anything like that, often don't perfectly obey the fairly straight-forward Bernoulli's principle, and in some cases Bernoulli's principle doesn't really come close to describing the behavior of real-life fluids when they're flowing in real-life situations. Even static fluids exhibit unusual behavior, particularly associated with surface tension. We should get away from our ideal world (at least for one day!) and get into some more realistic situations.
Viscosity
The viscosity of a fluid is basically a measure of how sticky it is. Water has a fairly low viscosity; things like shampoo or syrup have higher viscosities. Viscosity also depends on temperature : engine oil, for instance, is much less viscous at high temperatures than it is in a cold engine in the middle of winter.
For fluids flowing through pipes, the viscosity produces a resistive force. This resistance can basically be thought of as a frictional force acting between parts of the fluid that are traveling at different speeds. The fluid very close to the pipe walls, for instance, travels more slowly than the fluid in the very center of the pipe.
Poiseuille's equation
The equation that governs fluid flowing through a pipe or tube is known as Poiseuille's equation. It accounts for the fluids viscosity, although it really is valid only for streamline (non-turbulent) flow. Blood flowing through blood vessels in the human body isn't exactly streamline, but applying Poiseuille's equation in that situation is a reasonable first approximation, and leads to some interesting implications.
For blood, the coefficient of viscosity is about 4 x 10-3 Pa s.
The most important thing to notice about the volume rate of flow is how strongly it depends on the radius of the tube. The flow rate is proportional to r4, so a relatively small change in radius can produce a significant change in flow. Decreasing the radius by a factor of two, for instance, reduces the flow rate by a factor of 16! A This is why it's so important to worry about cholesterol levels, or to worry about other things that can clog the arteries in our bodies - even a minor change in the size of the blood vessels can have a significant impact on the rate at which blood is pumped around our bodies, as well as on how much work our hearts have to do to move that blood around.
Surface tension
You've probably noticed the interesting behavior that can take place at the surfaces of liquids. According to Archimedes' principle, for instance, a steel needle should sink in water. A needle placed carefully on water, however, can be supported by the surface tension - the liquid responds in a way similar to a stretched membrane. Try it at home - see what you can get to float on water.
One way to think of surface tension is in terms of energy. The larger the surface, the more energy there is. To minimize energy, most fluids assume the shape with the smallest surface area This is why small drops of water are round, for instance - a sphere is the shape with the minimum suface area for a given volume. Soap bubbles also tend to form themselves into shapes with minimal surface area.
It takes work to increase the surface area of a liquid. The surface tension can be defined in terms of this work W, as follows:
If you have a thin film of fluid, and try to stretch it, the film
resists. The surface tension can also be defined as the force F per
unit length L tending to pull the surface back :
Water is often used for cleaning, but the surface tension makes it hard
for water to penetrate into small crevices or openings, such as are
found in clothes. Soap is added to water to reduce the surface tension,
so clothes (or whatever else) get much cleaner.
Subject:
Subject X2:
Forces and Newton's Laws
Subject:
Subject X2:
Assorted forces, and applying Newton's laws
9-22-99
Sections 4.6 - 4.7
Forces can come from various sources. Whenever two objects are touching, they usually exert forces on each other, Newton's third law reminding us that the forces are equal and opposite. Two objects do not have to be in contact to exert forces on each other, however. The force of gravity, for instance, is a good example of a force that can arise without two objects being in contact with each other.
Weight
Mass and weight are often used interchangeably, but they are quite different. The mass of an object is an intrinsic property of an object. If your mass is 50 kg, you have a mass of 50 kg no matter where you go: on Earth, on the Moon, in orbit, wherever. Your weight, on the other hand, will vary depending on where you are. Your weight is the magnitude of the gravitational force you experience, and it has units of force, Newtons. Because the gravitational force you experience on the Earth is different from that you'd experience on the Moon or in orbit, your weight would be different even though your mass remains constant.
We'll examine the force of gravity in more detail later in the course. For now, it's sufficient to remember that, at the surface of the Earth, the gravitational force on an object of mass m has a magnitude of mg. The direction is toward the center of the Earth.
The normal force
Many forces do come from objects being in contact with each other. A book rests on a table: the book exerts a downward force on the table, and the table exerts an equal-and-opposite force up on the book. We call this force the normal force, which doesn't mean that other forces are abnormal - "normal" is the technical physics word for perpendicular. We call it the normal force because the force is perpendicular to the interface where the book meets the table.
The normal force is just one component of the contact force between objects, the other component being the frictional force. The normal force is usually symbolized by . In many cases the normal force is simply equal to the weight of an object, but that's because in many cases the normal force is the only thing counter-acting the weight...that is not always the case, however, and one should always be careful to calculate by applying Newton's second law.
The tension force
Whenever we use a rope (or something equivalent, like a string) to exert a force on an object, we're creating tension in the rope that transmits the force we exert on the rope to the object at the other end of the rope. The tension force is usually labeled by T. To makes our lives simpler, we usually assume that the rope has no mass, and does not stretch. Using these assumptions, when we exert a certain T on our massless unstretchable rope, the rope exerts that same T on the object. The rope itself will feel like it's being pulled apart, because we'll be exerting a certain T in one direction and the object we're pulling on will be exerting an equal-and-opposite force at the other end.
One rule to remember - you can't push with a rope. The tension force always goes along the rope away from the object attached to it.
Applying Newton's laws
A good way to see how Newton's laws are applied is to do an example.
Example - A box of mass 3.60 kg rests on an inclined plane which is at an angle of 15.0° with respect to the horizontal. A string is tied to the box, and it exerts a force of 5.00 N up the ramp. What is the acceleration? Give the magnitude and direction.
The first step in solving this is to draw a picture, showing the box, inclined plane, and all the forces. Then choose a coordinate system, showing positive directions. One axis of your coordinate system should be aligned with the acceleration, which in this case is either up or down the ramp. Here, we've assumed that the box accelerates up the ramp, although we're not sure. This could be worked out by figuring out the component of the weight down the slope and comparing it to the tension force, but it's fine to guess. If we guess wrong we'll get a minus sign for the acceleration at the end which will tell us that the box accelerates down the slope...the magnitude will be correct, though.
The next step is to draw the free body diagram, which is similar to the first picture but without the inclined plane. Another difference is that the force of gravity has been split up into components parallel to the incline and perpendicular to the incline. In other words, its been split into its x and y components.
Applying Newton's second law in the y-direction gives:
The box is not accelerating in the y-direction, which is why the net
force in that direction is zero. Solving for the normal force gives:
Applying Newton's second law in the x-direction gives:
Solving for the acceleration gives:
ax = T/m - g sin15° = 5.0/3.60 - 9.80 sin15° = -1.15 m/s2
So, the magnitude of the acceleration is 1.15 m/s2. The minus sign means that the box accelerates down the slope, rather than up as we'd assumed. This is because the component of the weight down the slope is larger than the tension.
The problem-solving process
If you apply a logical, step-by-step approach to these kinds of problems, you'll find them much easier to deal with. The example above should give you some idea of the steps to follow when trying to solve a typical problem. Summarizing them here:
1. Draw a diagram.
2. Choose a coordinate system. Generally the problem will be easiest to solve if you align one direction of your coordinate system with the acceleration of the object.
3. Draw a free-body diagram for each object, showing the forces applied to each object. Apply Newton's third law, which states that equal-and-opposite forces are exerted between interacting objects.
4. Apply Newton's second law, the sum of all the forces equals ma, for each direction for each free-body diagram. In other words, write out equations with the sum of all the forces in one direction on the left side, and the mass times the acceleration in that direction on the right side. Remember to sum the forces with the appropriate plus or minus signs, depending on their directions.
5. If you have the same number of equations as unknowns, solve. Otherwise, think about other principles of physics you can use to relate the unknown variables in the problem.
6. Always check to make sure your answers are reasonable. For example, are the numbers sensible? Do they have correct units?
Subject:
Subject X2:
Friction
9-24-99
Sections 4.8 - 4.9
The force of friction
The normal force is one component of the contact force between two objects, acting perpendicular to their interface. The frictional force is the other component; it is in a direction parallel to the plane of the interface between objects. Friction always acts to oppose any relative motion between surfaces.
For the simple example of a book resting on a flat table, the frictional force is zero. There is no force trying to move the book across the table, so there is no need for a frictional force because there is nothing for the frictional force to oppose. If we try to slide the book across the table, however, friction will come in to play.
Let's say it takes a force of 5 N to start the book moving. If we push on the book with a force of less than 5 N, the book won't move, because the frictional force will exactly balance the force we apply. If we push with a 1 N force, a 1 N frictional force opposes us. If we exert a 2 N force, the frictional force matches us at 2 N, and so on. When a frictional force exists but there is no relative motion of the surfaces in contact (e.g., the book isn't sliding across the table), we call it a static frictional force. The static frictional force is given by the equation:
The coefficient of friction (static or kinetic) is a measure of how difficult it is to slide a material of one kind over another; the coefficient of friction applies to a pair of materials, and not simply to one object by itself.
Note that there is a less-than-or-equal-to sign in the equation for the static frictional force. The static force of friction has a maximum value, but when two surfaces are not moving relative to each other the static force of friction is always just enough to exactly balance any forces trying to produce relative motion.
What happens when one object is sliding over another, when there is relative motion between two surfaces? There will still be a frictional force, but because we're dealing with things in motion we call it the kinetic frictional force. There is a different coefficient of friction associated with kinetic friction, the kinetic coefficient of friction, which is always less than or equal to the static coefficient.
As with the static frictional force, the kinetic frictional force acts to oppose the relative motion of the surfaces in contact. One important difference between the two is that the kinetic friction equation has an equals sign: the kinetic force of friction is always equal to the kinetic coefficient of friction times the normal force.
Applying Newton's laws
Let's try a couple of examples involving friction.
Example 1 - A box of mass 3.60 kg travels at constant velocity down an inclined plane which is at an angle of 42.0° with respect to the horizontal. A string tied to the box exerts a vertical force of 7.38 N. What is the kinetic coefficient of friction?
Again, start by drawing a picture. In this case, because the box is traveling down the ramp, we know the frictional force is kinetic. It opposes the motion, so the frictional force must be directed up the slope. One thing to keep in mind in this problem is that the velocity is constant - this means the acceleration is zero.
The free-body diagram is also shown, with the forces split into
components parallel and perpendicular to the inclined plane. Because
there is no acceleration, any coordinate system is fine - a system
parallel and perpendicular to the ramp is pretty convenient, though,
because two of the forces are along those directions.
Applying Newton's second law to the forces in the y-direction :
Again, we can use this equation to solve for the normal force:
Applying Newton's second law in the x-direction gives:
The box is moving at a constant velocity, so that means the
acceleration is zero. Solving for the kinetic force of friction gives:
The coefficient of kinetic friction can be found from the normal force and the frictional force:
This is actually a relatively large value for the coefficient, so it's not easy to move this box along this ramp.
Example 2
Consider another example involving an inclined plane, only this time there will be two boxes involved. This is quite a challenging example, so don't be too intimidated if it looks tricky. Start by seeing if you agree with the free-body diagrams; if you understand those, you've made an important step in learning some physics.
Box 1, a wooden box, has a mass of 8.60 kg and a coefficient of kinetic friction with the inclined plane of 0.35. Box 2, a cardboard box, sits on top of box 1. It has a mass of 1.30 kg. The coefficient of kinetic friction between the two boxes is 0.45. The two boxes are linked by a rope which passes over a pulley at the top of the incline, as shown in the diagram. The inclined plane is at an angle of 38.0° with respect to the horizontal. What is the acceleration of each box?
The diagram for the situation looks like this:
The next step is to draw a free-body diagram of each box in turn. To
draw these, it helps to think about which way the boxes will
accelerate. The two boxes are tied together, and the heavier box will
win...in other words, it will accelerate down the slope and the lighter
one, on top, will be accelerated up towards the pulley. The pulley, by
the way, simply changes the direction of the tension force. We're
assuming that the pulley is massless and frictionless, so both boxes
feel the same tension force. It's important to know the direction of
the acceleration (or, if you don't know, to guess) and apply what you
figured out (or your guess) consistently to both boxes.
The free-body diagram of box 1 is relatively complicated, with a
total of 6 forces appearing. The free-body diagram for box 2 is a
little easier to deal with, having 4 forces, so that's a good place to
start.
For box 2 - start by summing the forces in the y-direction, where there is no acceleration:
This can be solved to give the normal force:
Now find the net force in the x direction, where there is an acceleration up the slope:
There are two unknowns in this equation, the tension T and ax, the acceleration. We can at least solve for T in terms of ax, like this:
Now move on to box 1. Going back to the free-body diagram and summing forces in the y-direction gives:
This equation can be solved to give the normal force associated with the interaction between the inclined plane and box 1:
Things are a little more complicated in the x-direction, but adding up the forces gives:
substituting in the expression we worked out for T, and what fB and fA are gives:
Moving the acceleration terms to the left side gives:
Solving for the acceleration gives:
Subject:
Subject X2:
Gravity
10-6-99
Sections 5.6 - 5.10
The force of gravity
Isaac Newton is probably best known for his study of gravity, seeing as just about everyone has heard the story about Newton being conked on the head by an apple. What Newton said was this: whenever there are two objects that have mass, they will exert a gravitational force on each other that is proportional to the product of the masses, and inversely proportional to the square of the distance between them. (Actually, inversely proportional to the square of the distance between the two centers of mass is more accurate.) If the first object has a mass of m1, and the second object has a mass m2, and there is a distance r between them (between their centers of mass, that is), the magnitude of the gravitational force is given by:
That equation is Newton's universal law of gravitation.
You might be used to thinking of the gravitational force as F = mg. Where does this other, more complicated, equation fit in? F = mg is actually a special-case form of the other one, applying only to objects very close to the surface of the Earth. This value of g, 9.8 m/s2, can be found by combining G, the mass of the Earth, and the radius of the Earth. If you set F = mg equal to the gravitational force equation, you get:
Plugging these numbers in, and the value of G, gives g = 9.80 m/s2.
Any two masses exert equal-and-opposite gravitational forces on each other. If we drop a ball, the Earth exerts a gravitational force on the ball, but the ball exerts a gravitational force of the same magnitude (and in the opposite direction) on the Earth. The force just makes a lot less difference to the Earth because of its large mass.
Example - The Earth orbiting the Sun. What is the magnitude of the acceleration experienced by the Earth in its orbit around the Sun? We can work out the answer two different ways.
The free-body diagram of the Earth in this situation involves only one force, the gravitational force exerted by the Sun on the Earth, given by Newton's law of universal gravitation, which we've seen before:
he two masses are the mass of the Sun and the mass of the Earth, and r is the distance between them. Because this is the only force acting on the Earth, we can set this equal to ma, remembering that a has the special form a = v2 / r:
This gives us two ways to get the acceleration,
Method 1 - To get the acceleration using the first equation, we need to know the mass of the Sun and the distance from the Earth to the Sun. Roughly, the Sun has a mass of 2 x 1030 kg, and it's 93 million miles = 150 million km = 1.5 x 1011 m away. Plugging these values in gives an acceleration of :
Method 2 - the second method should give us the same answer, but we need to know the speed of the Earth as it orbits the Sun. The period, T, the time it takes the Earth to orbit the Sun, is one year, which, very conveniently, happens to work out to very close to . The speed of the Earth is:
This gives an acceleration of:
That's pretty good agreement between the two methods, given the approximating we're doing here, which means the approximations are rather good. The acceleration is relatively small, but sufficient to keep the Earth in its orbit.
Kepler's laws
Johannes Kepler (1571-1630) was a German astronomer who made some observations about the motion of the planets. He summarized those in three statements known as Kepler's laws.
The one that's perhaps the most relevant for our purposes is Kepler's third law, which states that the ratio of the squares of the periods of any two planets orbiting the Sun is equal to the ratio of the cubes of their average distances from the Sun.
Newton showed that Kepler's third law can be derived from Newton's law of universal gravitation. We've already figured out that applying Newton's second law results in :
G m1 m2 / r2 = m1 v2 / r
This simplifies to:
G m2 / r = v2 (where m2 represents the mass of the Sun)
If the orbit is circular, then the speed is simply the circumference of the orbit divided by the period, T, the time to travel once around the orbit.
Combining these two equations and eliminating v gives:
This can be rearranged to get:
This represents Kepler's third law. For every planet in the solar
system, the right-hand side of the equation is the same, because it has
only the universal gravitational constant and the mass of the Sun.
Therefore the ratio of the square of the period to the cube of the
average distance is the same value for every planet in the solar system.
Subject:
Subject X2:
More circular motion
10-1-99
Sections 5.3 - 5.5
Cars on banked turns
A good example of uniform circular motion is a car going around a banked turn, such as on a highway off-ramp. These off-ramps often have the recommended speed posted; even if there was no friction between your car tires and the road, if you went around the curve at this "design speed" you would be fine. With no friction, if you went faster than the design speed you would veer towards the outside of the curve, and if you went slower than the design speed you would veer towards the inside of the curve.
In theory, then, accounting for friction, there is a range of speeds at which you can negotiate a curve. In most cases the coefficient of friction is sufficiently high, and the angle of the curve sufficiently small, that going too slowly around the curve is not an issue. Going too fast is another story, however.
The textbook does a good analysis of a car on a banked curve without friction, arriving at a connection between the angle of the curve, the radius, and the speed. The speed is known as the design speed of the curve (the speed at which you're safest negotiating the curve) and is given by:
Consider now the role that friction plays, and think about how to
determine the maximum speed at which you can negotiate the curve
without skidding. The first thing to realize is that the frictional
force is static friction. Even though the car is moving, the car tires
are not slipping on the road surface, so the part of tire in contact
with the road is instantaneously at rest with respect to the road.
Also, if we're worried about the maximum speed at which we can go
around the banked turn, if there was no friction the car would tend to
slide towards the outside of the curve, so the friction opposes this
tendency and points down the slope.
The diagram, and a free-body diagram, of the situation is shown
here. Note that the diagram looks similar to that of a box on an
inclined plane. There is a critical difference, however; for the box on
an inclined plane, the coordinate system was parallel and perpendicular
to the slope, because the box was either moving, and/or accelerating,
up or down the slope. In this case the coordinate system is horizontal
and vertical, because the centripetal acceleration points horizontally
in towards the center of the circle and there is no vertical component
of the acceleration.
Moving from the free-body diagram to the force equations gives:
This can be rearranged to solve for the normal force:
Note that we're solving for the maximum speed at which the car can go
around the curve, which will correspond to the static force of friction
being a maximum, which is why it's valid to say that
In the x-direction, the force equation is:
Substituting , and plugging in the equation for the normal force, gives:
There is an m in every term, so the mass cancels out. The equation can then be rearranged to solve for the maximum speed:
Note that when the coefficient of friction is zero (i.e., the road is
very slippery), the maximum speed reduces to the design speed,
and for certain combinations of theta and the coefficient of friction (both large, in general) the denominator turns out to be negative, implying that there is no maximum speed; in those cases, you could drive as fast as you wanted without worrying about skidding. Note that this does not apply to standard highway off-ramps! The appropriate conditions for no maximum safe speed (or at least a very high maximum) would be found at racetracks like the Indianapolis Speedway, for example.
Vertical circular motion
Some roller-coasters have loop-the-loop sections, where you travel in a vertical circle, so that you're upside-down at the top. To do this without falling off the track, you have to be traveling at least a particular minimum speed at the top. The critical factor in determining whether you make it completely around is the normal force; if the track has to exert a downward normal force at the top of the track to keep you moving in a circle, you're fine, but if the normal force drops to zero you're in trouble.
The normal force changes as you travel around a vertical loop; it changes because your speed changes and because your weight has a different effect at each part of the circle. To keep going in a circular path, you must always have a net force equal to mv2 / r pointing towards the center of the circle. If the net force drops below the required value, you will veer off the circular path away from the center, and if the net force is more than the required value you will veer off towards the center.
Consider what happens at the bottom of the loop, and compare it to what happens at the top. At the bottom, mg points down and the normal force points up, towards the center of the circle. The normal force is then not simply equal to the weight, but is larger because it must also supply the required centripetal acceleration:
This is why you actually feel heavier at the bottom of a loop like
this, because your apparent weight is equal to the normal force you
feel.
At the top of the loop, on the other hand, the normal force and
the weight both point towards the center of the circle, so the normal
force is less than the weight:
If you're going at just the right speed so mv2 / r = mg, the
normal force drops to zero, and you would actually feel weightless for
an instant. Faster than this speed and there is a normal force helping
to keep you on the circular path; slower and the normal force would go
up, which means you'll fall out of the coaster and/or the coaster will
fall off the track unless you're strapped in and the coaster is held
down to the track.
Subject:
Subject X2:
Newton's laws of motion
9-20-99
Sections 4.1 - 4.5
Force
We've introduced the concept of projectile motion, and talked about throwing a ball off a cliff, analyzing the motion as it traveled through the air. But, how did the ball get its initial velocity in the first place? When it hit the ground, what made it eventually come to a stop? To give the ball the initial velocity, we threw it, so we applied a force to the ball. When it hit the ground, more forces came into play to bring the ball to a stop.
A force is an interaction between objects that tends to produce acceleration of the objects. Acceleration occurs when there is a net force on an object; no acceleration occurs when the net force (the sum of all the forces) is zero. In other words, acceleration occurs when there is a net force, but no acceleration occurs when the forces are balanced. Remember that an acceleration produces a change in velocity (magnitude and/or direction), so an unbalanced force will change the velocity of an object.
Isaac Newton (1642-1727) studied forces and noticed three things in particular about them. These are important enough that we call them Newton's laws of motion. We'll look at the three laws one at a time.
Newton's first law
The ancient Greeks, guided by Aristotle (384-322 BC) in particular, thought that the natural state of motion of an object is at rest, seeing as anything they set into motion eventually came to a stop. Galileo (1564-1642) had a better understanding of the situation, however, and realized that the Greeks weren't accounting for forces such as friction acting on the objects they observed. Newton summarized Galileo's thoughts about the state of motion of an object in a statement we call Newton's first law.
Newton's first law states that an object at rest tends to remain at rest, and an object in motion tends to remain in motion with a constant velocity (constant speed and direction of motion), unless it is acted on by a nonzero net force.
Note that the net force is the sum of all the forces acting on an object.
The tendency of an object to maintain its state of motion, to remain at rest or to keep moving at a constant velocity, is known as inertia. Mass is a good measure of inertia; light objects are easy to move, but heavy objects are much harder to move, and it is much harder to change their motion once they start moving.
A good question to ask is: do Newton's laws apply all the time? In most cases they do, but if we're trying to analyze motion in an accelerated reference frame (while we're spinning around would be a good example) then Newton's law are not valid. A reference frame in which Newton's laws are valid is known as an inertial reference frame. Any measurements we take while we're not moving (while we're in a stationary reference frame, in other words) or while we're moving at constant velocity (on a train traveling at constant velocity, for example) will be consistent with Newton's laws.
Newton's second law
If there is a net force acting on an object, the object will have an acceleration and the object's velocity will change. How much acceleration will be produced by a given force? Newton's second law states that for a particular force, the acceleration of an object is proportional to the net force and inversely proportional to the mass of the object. This can be expressed in the form of an equation:
In the MKS system of units, the unit of force is the Newton (N). In terms of kilograms, meters, and seconds, 1 N = 1 kg m / s2.
Free-body diagrams
In applying Newton's second law to a problem, the net force, which is the sum of all the forces, often has to be determined so the acceleration can be found. A good way to work out the net force is to draw what's called a free-body diagram, in which all the forces acting on an object are shown. From this diagram, Newton's second law can be applied to arrive at an equation (or two, or three, depending on how many dimensions are involved) that will give the net force.
Let's take an example. This example gets us ahead of ourselves a little, by bringing in concepts we haven't talked about yet, but that's fine because (a) we'll be getting to them very shortly, and (b) there's a good chance you've seen them before anyway. Say you have a box, with a mass of 2.75 kg, sitting on a table. Neglect friction. There is a rope tied to the box and you pull on it, exerting a force of 20.0 N at an angle of 35.0¡ above the horizontal. A second rope is tied to the other side of the box, and your friend exerts a horizontal force of 12.0 N. What is the acceleration of the box?
The first step is to draw the free-body diagram, accounting for all the forces. The four forces we have to account for are the 20.0 N force you exert on it, the 12.0 N force your friend exerts, the force of gravity (the gravitational force exerted by the Earth on the box, in other words), and the support force provided by the table, which we'll call the normal force, because it is normal (perpendicular) to the surface the box sits on.
The free-body diagram looks like this:
We can apply Newton's second law twice, once for the horizontal direction, which we'll call the x-direction, and once for the vertical direction, which we'll call the y-direction. Let's take positive x to be right, and positive y to be up. The box accelerates across the table, so it has an acceleration in the x direction but not in the y direction (it doesn't accelerate vertically).
In the x direction, summing the forces gives:
The x-component of the force you exert is partly canceled by the force your friend exerts, but you win the tug-of-war and the box accelerates towards you. Solving for the horizontal acceleration gives:
ax = 4.4 / 2.75 = 1.60 m/s2 to the right.
In the y direction, there is no acceleration, which means the forces have to balance. This allows us to solve for the normal force, because when we add up all the forces we get:
The gravitational force is often referred to as the weight. To remind you that this is actually a force, I'll generally refer to it as the force of gravity, or gravitational force, rather than the weight. The force of gravity is simply the mass times g, 2.75 x 9.8 = 26.95 N. Solving for the normal force gives:
FN = 26.95 - 20.0 sin35 = 26.95 - 11.47 = 15.5 N. In many problems the normal force will turn out to have the same magnitude as the force of gravity, but that is not always true, and it is not true in this case.
Newton's third law
A force is an interaction between objects, and forces exist in equal-and-opposite pairs. Newton's third law summarizes this as follows: when one object exerts a force on a second object, the second object exerts an equal-and-opposite force on the first object. Note that "equal-and-opposite" is the shortened form of "equal in magnitude but opposite in direction".
Consider the free-body diagram of the box in the example above. The box experiences 4 different forces, one from you, one from your friend, one from the Earth (the gravitational force) and one from the table. By Newton's law, the box also exerts 4 forces. If you exert a 20.0 N force on the box, the box exerts a 20.0 N force on you. Your friend exerts a 12.0 N force to the left, so the box exerts a 12.0 N force to the right on your friend. The table exerts an upward force on the box, the normal force, which is 15.5 N, so the box exerts a downward force of 15.5 N on the table. Finally, the Earth exerts a 26.95 N force down on the box, so the box exerts a 26.95 N force up on the Earth.
Although the forces between two objects are equal-and-opposite, the effect of the forces may or may not be similar on the two; it depends on their masses. Remember that the acceleration depends on both force and mass, and let's look at the force exerted by the Earth on a falling object. If we drop a 100 g (0.1 kg) ball, it experiences a downward acceleration of 9.8 m/s2, and a force of about 1 N, because it is attracted towards the Earth. The ball exerts an equal-and-opposite force on the Earth, so why doesn't the Earth accelerate upwards towards the ball? The answer is that it does, but because the mass of the Earth is so large (6.0 x 1024 kg) the acceleration of the Earth is much too small (about 1.67 x 10-25 m/s2) for us to notice.
In cases where objects of similar mass exert forces on each other, the fact that forces come in equal-and-opposite pairs is much easier to see.
Subject:
Subject X2:
Uniform circular motion
9-29-99
Sections 5.1 - 5.2
Uniform circular motion
When an object is experiencing uniform circular motion, it is traveling in a circular path at a constant speed. If r is the radius of the path, and we define the period, T, as the time it takes to make a complete circle, then the speed is given by the circumference over the period. A similar equation relates the magnitude of the acceleration to the speed:
These two equations can be combined to give the equation:
This is known as the centripetal acceleration; v2 / r is the special form the acceleration takes when we're dealing with objects experiencing uniform circular motion.
A warning about the term "centripetal force"
In circular motion many people use the term centripetal force, and say that the centripetal force is given by:
I personally think that "centripetal force" is misleading, and I will
use the phrase centripetal acceleration rather than centripetal force
whenever possible. Centripetal force is a misleading term because,
unlike the other forces we've dealt with like tension, the
gravitational force, the normal force, and the force of friction, the
centripetal force should not appear on a free-body diagram. You do NOT
put a centripetal force on a free-body diagram for the same reason that
ma does not appear on a free body diagram; F = ma is the net force, and
the net force happens to have the special form when we're dealing with uniform circular motion.
The centripetal force is not something that mysteriously appears whenever an object is traveling in a circle; it is simply the special form of the net force.
Newton's second law for uniform circular motion
Whenever an object experiences uniform circular motion there will always be a net force acting on the object pointing towards the center of the circular path. This net force has the special form , and because it points in to the center of the circle, at right angles to the velocity, the force will change the direction of the velocity but not the magnitude.
It's useful to look at some examples to see how we deal with situations involving uniform circular motion.
Example 1 - Twirling an object tied to a rope in a horizontal circle. (Note that the object travels in a horizontal circle, but the rope itself is not horizontal). If the tension in the rope is 100 N, the object's mass is 3.7 kg, and the rope is 1.4 m long, what is the angle of the rope with respect to the horizontal, and what is the speed of the object?
As always, the place to start is with a free-body diagram, which just has two forces, the tension and the weight. It's simplest to choose a coordinate system that is horizontal and vertical, because the centripetal acceleration will be horizontal, and there is no vertical acceleration.
The tension, T, gets split into horizontal and vertical components. We
don't know the angle, but that's OK because we can solve for it. Adding
forces in the y direction gives:
This can be solved to get the angle:
In the x direction there's just the one force, the horizontal component
of the tension, which we'll set equal to the mass times the centripetal
acceleration:
We know mass and tension and the angle, but we have to be careful with
r, because it is not simply the length of the rope. It is the
horizontal component of the 1.4 m (let's call this L, for length), so
there's a factor of the cosine coming in to the r as well.
Rearranging this to solve for the speed gives:
which gives a speed of v = 5.73 m/s.
Example 2 - Identical objects on a turntable,
different distances from the center. Let's not worry about doing a full
analysis with numbers; instead, let's draw the free-body diagram, and
then see if we can understand why the outer objects get thrown off the
turntable at a lower rotational speed than objects closer to the
center.
In this case, the free-body diagram has three forces, the force
of gravity, the normal force, and a frictional force. The friction here
is static friction, because even though the objects are moving, they
are not moving relative to the turntable. If there is no relative
motion, you have static friction. The frictional force also points
towards the center; the frictional force acts to oppose any relative
motion, and the object has a tendency to go in a straight line which,
relative to the turntable, would carry it away from the center. So, a
static frictional force points in towards the center.
Summing forces in the y-direction tells us that the normal force is
equal in magnitude to the weight. In the x-direction, the only force
there is is the frictional force.
The maximum possible value of the static force of friction is
As the velocity increases, the frictional force has to increase to
provide the necessary force required to keep the object spinning in a
circle. If we continue to increase the rotation rate of the turntable,
thereby increasing the speed of an object sitting on it, at some point
the frictional force won't be large enough to keep the object traveling
in a circle, and the object will move towards the outside of the
turntable and fall off.
Why does this happen to the outer objects first? Because the
speed they're going is proportional to the radius (v = circumference /
period), so the frictional force necessary to keep an object spinning
on the turntable ends up also being proportional to the radius. More
force is needed for the outer objects at a given rotation rate, and
they'll reach the maximum frictional force limit before the inner
objects will.
Subject:
Subject X2:
Harmonic Motion
Subject:
Subject X2:
SHM Example; Damped and Driven Harmonic Motion
Resonance
11-22-99
Sections 10.5 - 10.6
An example, using a mass on a spring
Here's a good problem that brings in everything we know about springs, plus all the new things we're doing on SHM. You have a block with a mass of 0.2 kg. You also have a spring, but you don't know the spring constant. When you hang the spring vertically and attach the block, the spring stretches by 9.8 cm (at equilibrium) . You then take the spring and mount it horizontally with the mass at one end, with the mass resting on a frictionless surface. You displace the mass by 5 cm from the equilibrium position and let it go from rest, causing the mass to oscillate back and forth in simple harmonic motion.
Some good questions to ask are:
(a) What's the frequency of the motion when the mass is oscillating?
(b) What's the maximum speed of the mass, and where does it reach this maximum speed?
(c) If the equilibrium position is x = 0, and you let it go from x = +5 cm, what is the position of the mass exactly two seconds after you let it go?
To find the frequency for a mass on a spring, we need to know the spring constant and the mass. The mass is given, and the spring constant can be found from the information obtained when you hung the spring and mass vertically. At equilibrium, the upward spring force, kx, must balance the weight, mg. This gives:
k = mg/x = 0.2(9.8) / 0.098 = 20 N/m
The angular frequency is the square root of k/m, so that's:
The frequency is then:
This corresponds to a period of 0.628 seconds.
When the mass is oscillating horizontally, the maximum speed can be found in two different ways. One is to use the fact that the maximum speed is simply the amplitude multiplied by the angular frequency. This gives:
vmax= 0.05 (10) = 0.5 m/s
Another method is to apply conservation of energy. When the mass was initially let go from rest, all the energy was stored as potential energy in the spring. This initial energy is:
PE = 0.5 kx2= 0.5 (20) (0.05)2 = 0.025 J
When the spring passes through the equilibrium position, there is no potential energy. All the energy is kinetic, and we haven't lost any energy. This allows us to calculate the speed at which it passes through equilibrium:
at equilibrium : KE = 0.5 mv2 = 0.025 J
Solving for the speed gives v = 0.5 m/s.
So, the maximum speed is 0.5 m/s, and the mass reaches this maximum speed at the equilibrium position, because that's the only place where the energy is entirely kinetic energy.
Now, what about the position of the mass at t = 2 seconds? All we need to do is to plug that time into the equation:
One thing to be very careful of here is that the angular frequency is in radians/second, so you have to put your calculator in radians mode to do the cosine (or convert the radians to degrees). The amplitude, A, is 0.05 m, the amount we displaced the mass in the first place. This gives :
x = 0.05 cos (20 radians) = 0.0204 m, or just over 2 cm. The fact that this answer is positive means it's on the same side of the equilibrium position as the starting point.
One way to check this is to figure out how many periods are in 2 seconds. Dividing the time by the period gives 2 / 0.628 = 3.18 periods. So, the mass has gone back and forth completely 3 times. The extra 0.18 is the important bit. One quarter (0.25) of a period represents the motion from the endpoint to the equilibrium position. 0.18 is a little less than that, so it must be getting close to the equilibrium position but not be quite there yet. That's certainly consistent with it being at +2 cm.
Damped harmonic motion
In the absence of any resistance forces (like friction and air resistance), most simple harmonic motions would go on unchanged forever. In reality, this doesn't happen, because there are resistance forces.
Damped harmonic motion - harmonic motion in which energy is steadily removed from the system.
There are three kinds of damping:
1. Critically damped - the damping is the minimum necessary to return the system to equilibrium without over-shooting.
2. Underdamped - less than critical, the system oscillates with the amplitude steadily decreasing.
3. Overdamped - More than critical, the system returns slowly towards equilibrium.
Driven harmonic motion
Also known as forced harmonic motion, this is harmonic motion in which the system is given a periodic push. A perfect example is a person on a swing.
How the system behaves depends on how the frequency of the driving force compares to the natural frequency of oscillation of the system.
The most efficient way to transfer energy from the driver to the system is to match the frequency of the driving force to the natural frequency of the system, such as you do when pushing someone on a swing. This is known as resonance. At resonance, relatively small driving forces can build up to large-amplitude oscillations, just because energy is continually being injected into the system at just the right frequency.
Subject:
Subject X2:
Simple Harmonic Motion
11-17-99
Sections 10.1 - 10.4
The connection between uniform circular motion and SHM
It might seem like we've started a topic that is completely unrelated to what we've done previously; however, there is a close connection between circular motion and simple harmonic motion. Consider an object experiencing uniform circular motion, such as a mass sitting on the edge of a rotating turntable. This is two-dimensional motion, and the x and y position of the object at any time can be found by applying the equations:
The motion is uniform circular motion, meaning that the angular
velocity is constant, and the angular displacement is related to the
angular velocity by the equation:
Plugging this in to the x and y positions makes it clear that these are
the equations giving the coordinates of the object at any point in
time, assuming the object was at the position x = r on the x-axis at
time = 0:
How does this relate to simple harmonic motion? An object experiencing
simple harmonic motion is traveling in one dimension, and its
one-dimensional motion is given by an equation of the form
The amplitude is simply the maximum displacement of the object from the equilibrium position.
So, in other words, the same equation applies to the position of
an object experiencing simple harmonic motion and one dimension of the
position of an object experiencing uniform circular motion. Note that
the in the SHM displacement equation is known as the angular frequency. It
is related to the frequency (f) of the motion, and inversely related to
the period (T):
The frequency is how many oscillations there are per second, having units of hertz (Hz); the period is how long it takes to make one oscillation.
Velocity in SHM
In simple harmonic motion, the velocity constantly changes, oscillating just as the displacement does. When the displacement is maximum, however, the velocity is zero; when the displacement is zero, the velocity is maximum. It turns out that the velocity is given by:
Acceleration in SHM
The acceleration also oscillates in simple harmonic motion. If you consider a mass on a spring, when the displacement is zero the acceleration is also zero, because the spring applies no force. When the displacement is maximum, the acceleration is maximum, because the spring applies maximum force; the force applied by the spring is in the opposite direction as the displacement. The acceleration is given by:
Note that the equation for acceleration is similar to the equation for displacement. The acceleration can in fact be written as:
All of the equations above, for displacement, velocity, and acceleration as a function of time, apply to any system undergoing simple harmonic motion. What distinguishes one system from another is what determines the frequency of the motion. We'll look at that for two systems, a mass on a spring, and a pendulum.
The frequency of the motion for a mass on a spring
For SHM, the oscillation frequency depends on the restoring force. For a mass on a spring, where the restoring force is F = -kx, this gives:
This is the net force acting, so it equals ma:
This gives a relationship between the angular velocity, the spring constant, and the mass:
The simple pendulum
A simple pendulum is a pendulum with all the mass the same distance
from the support point, like a ball on the end of a string. Gravity
provides the restoring force (a component of the weight of the
pendulum).
Summing torques, the restoring torque being the only one, gives:
For small angular displacements :
So, the torque equation becomes:
Whenever the acceleration is proportional to, and in the opposite direction as, the displacement, the motion is simple harmonic.
For a simple pendulum, with all the mass the same distance from the suspension point, the moment of inertia is:
The equation relating the angular acceleration to the angular displacement for a simple pendulum thus becomes:
g
This gives the angular frequency of the simple harmonic motion of the simple pendulum, because:
Note that the frequency is independent of the mass of the pendulum.
Subject:
Subject X2:
Heat and Thermodynamics
Subject:
Subject X2:
Entropy and The Second Law
12-12-99
Sections 15.7 - 15.12
The second law revisited
The second law of thermodynamics is one of the most fundamental laws of nature, having profound implications. In essence, it says this:
The second law - The level of disorder in the universe is steadily increasing. Systems tend to move from ordered behavior to more random behavior.
One implication of the second law is that heat flows spontaneously from a hotter region to a cooler region, but will not flow spontaneously the other way. This applies to anything that flows: it will naturally flow downhill rather than uphill.
If you watched a film forwards and backwards, you would almost certainly be able to tell which way was which because of the way things happen. A pendulum will gradually lose energy and come to a stop, but it doesn't pick up energy spontaneously; an ice cube melts to form a puddle, but a puddle never spontaneously transforms itself into an ice cube; a glass falling off a table might shatter when it hits the ground, but the pieces will never spontaneously jump back together to form the glass again. Many processes are irreversible, and any irreversible process increases the level of disorder. One of the most important implications of the second law is that it indicates which way time goes - time naturally flows in a way that increases disorder.
The second law also predicts the end of the universe: it implies that the universe will end in a "heat death" in which everything is at the same temperature. This is the ultimate level of disorder; if everything is at the same temperature, no work can be done, and all the energy will end up as the random motion of atoms and molecules.
Entropy
A measure of the level of disorder of a system is entropy, represented by S. Although it's difficult to measure the total entropy of a system, it's generally fairly easy to measure changes in entropy. For a thermodynamic system involved in a heat transfer of size Q at a temperature T , a change in entropy can be measured by:
The second law of thermodynamics can be stated in terms of entropy.
If a reversible process occurs, there is no net change in entropy. In
an irreversible process, entropy always increases, so the change in
entropy is positive. The total entropy of the universe is continually
increasing.
There is a strong connection between probability and entropy.
This applies to thermodynamic systems like a gas in a box as well as to
tossing coins. If you have four pennies, for example, the likelihood
that all four will land heads up is relatively small. It is six times
more likely that you'll get two heads and two tails. The two heads -
two tails state is the most likely, shows the most disorder, and has
the highest entropy. Four heads is less likely, has the most order, and
the lowest entropy. If you tossed more coins, it would be even less
likely that they'd all land heads up, and even more likely that you'd
end up with close to the same number of heads as tails.
With a gas in a box, the probability that all the gas
molecules are in one corner of the box at the same time is very small
(for a typical box full of 1020 molecules or more,
incredibly small): this is therefore a low entropy state. It is much
more likely that the molecules are randomly distributed around the box,
and are moving in random directions; this high disorder state is a
considerably higher entropy state. The second law doesn't rule out all
the molecules ending up in one corner, but it means it's far more
likely that the molecules will be randomly distributed, and to move
towards a random distribution from an orderly distribution, as opposed
to the other way around.
Subject:
Subject X2:
Heat Engines and The Second Law
12-10-99
Sections 15.5 - 15.6
The second law of thermodynamics
The second law of thermodynamics comes in more than one form, but let's
state in a way that makes it obviously true, based on what you've
observed from simply being alive.
The second law states that heat flows naturally from regions of higher
temperature to regions of lower temperature, but that it will not flow
naturally the other way.
Heat can be made to flow from a colder region to a hotter region, which
is exactly what happens in an air conditioner, but heat only does this
when it is forced. On the other hand, heat flows from hot to cold
spontaneously.
Heat engines
We'll move on to look at heat engines, which are devices that use
heat to do work. A basic heat engine consists of a gas confined by a
piston in a cylinder. If the gas is heated, it expands, moving the
piston. This wouldn't be a particularly practical engine, though,
because once the gas reaches equilibrium the motion would stop. A
practical engine goes through cycles; the piston has to move back and
forth. Once the gas is heated, moving the piston up, it can be cooled
and the piston will move back down. A cycle of heating and cooling will
move the piston up and down.
A necessary component of a heat engine, then, is that two temperatures
are involved. At one stage the system is heated, at another it is
cooled.
In a full cycle of a heat engine, three things happen:
1. Heat is added. This is at a relatively high temperature, so the heat can be called QH.
2. Some of the energy from that input heat is used to perform work (W).
3. The rest of the heat is removed at a relatively cold temperature (QC).
The following diagram is a representation of a heat engine, showing the energy flow:
An important measure of a heat engine is its efficiency: how much of
the input energy ends up doing useful work? The efficiency is
calculated as a fraction (although it is often stated as a percentage):
Work is just the input heat minus the rejected heat, so:
Note that this is the maximum possible efficiency for an engine. In
reality there will be other losses (to friction, for example) that will
reduce the efficiency.
Carnot's principle
How can an engine achieve its maximum efficiency? It must operate
using reversible processes: a reversible process is one in which the
system and the surroundings can be returned to state they were in
before the process began. If energy is lost to friction during a
process, the process is irreversible; if energy is lost as heat flows
from a hot region to a cooler region, the process is irreversible. The
efficiency of an engine using irreversible processes can not be greater
than the efficiency of an engine using reversible processes that is
working between the same temperatures. This is known as Carnot's
principle, named after Sadi Carnot, a French engineer.
For any reversible engine (known as a Carnot engine) operating between
two temperatures, TH and TC, the efficiency is given by:
The efficiency is maximized when the cold reservoir is as cold as possible, and the hot temperature is as hot as possible.
The third law
The third law of thermodynamics states this : it is impossible to reach
absolute zero. This implies that a perpetual motion machine is
impossible, because the efficiency will always be less than 1.
Refrigerators, air conditioners, etc.
A device such as a refrigerator or air conditioner, designed to
remove heat from a cold region and transfer it to a hot region, is
essentially a heat engine operating in reverse, as the following energy
flow diagram shows:
A refrigerator, consisting of a fluid pumped through a closed system,
involves a four-step process. An air conditioner works the same way.
* Step 1 - The fluid passes through a nozzle and expands into a
low-pressure area. Similar to the way carbon dioxide comes out of a
fire extinguisher and cools down, the fluid turns into a gas and cools
down. This is essentially an adiabatic expansion.
* Step 2 - The cool gas is in thermal contact with the inner
compartment of the fridge; it heats up as heat is transferred to it
from the fridge. This takes place at constant pressure, so it's an
isobaric expansion.
* Step 3 - The gas is transferred to a compressor, which does most of
the work in this process. The gas is compressed adiabatically, heating
it and turning it back to a liquid.
* Step 4 - The hot liquid passes through coils on the outside of the
fridge, and heat is transferred to the room. This is an isobaric
compression process.
A refrigerator is rated by something known as the coefficient of
performance, which is the ratio of the heat removed from the fridge to
the work required to remove it:
The P-V graph for a refrigerator cycle
The P-V (pressure-volume) graph is very useful for calculating the work
done. For any kind of heat engine or refrigerator (reverse heat
engine), the processes involved form a cycle on the P-V graph. The work
is the area of the enclosed region on the graph. The diagram for a
refrigerator is a little more complicated than this because of the two
phase changes involved, but this is basically what it looks like:
Subject:
Subject X2:
Heat and Specific Heat
Heat
12-3-99
Sections 14.1 - 14.6
Temperature, internal energy, and heat
The temperature of an object is a measure of the energy per molecule of an object. To raise the temperature, energy must be added; to lower the temperature, energy has to be removed. This thermal energy is internal, in the sense that it is associated with the motion of the atoms and molecules making up the object.
When objects of different temperatures are brought together, the temperatures will tend to equalize. Energy is transferred from hotter objects to cooler objects; this transferred energy is known as heat.
Specific heat capacity
When objects of different temperature are brought together, and heat is transferred from the higher-temperature objects to the lower-temperature objects, the total internal energy is conserved. Applying conservation of energy means that the total heat transferred from the hotter objects must equal the total heat transferred to the cooler objects. If the temperature of an object changes, the heat (Q) added or removed can be found using the equation:
where m is the mass, and c is the specific heat capacity, a measure of the heat required to change the temperature of a particular mass by a particular temperature. The SI unit for specific heat is J / (kg °C).
This applies to liquids and solids. Generally, the specific heat capacities for solids are a few hundred J / (kg °C), and for liquids they're a few thousand J / (kg °C). For gases, the same equation applies, but there are two different specific heat values. The specific heat capacity of a gas depends on whether the pressure or the volume of the gas is kept constant; there is a specific heat capacity for constant pressure, and a specific heat capacity for constant volume.
Example
0.300 kg of coffee, at a temperature of 95 °C, is poured into a room-temperature steel mug, of mass 0.125 kg. Assuming no energy is lost to the surroundings, what does the temperature of the mug filled with coffee come to?
Applying conservation of energy, the total change in energy of the system must be zero. So, we can just add up the individual energy changes (the Q's) and set the sum equal to zero. The subscript c refers to the coffee, and m to the mug.
Note that room temperature in Celsius is about 20°. Re-arranging the equation to solve for the final temperature gives:
The temperature of the coffee doesn't drop by much because the specific heat of water (or coffee) is so much larger than that of steel. This is too hot to drink, but if you leave it heat will be transferred to the surroundings and the coffee will cool.
Changing phase; latent heat
Funny things happen when a substance changes phase. Heat can be transferred in or out without any change in temperature, because of the energy required to change phase. What is happening is that the internal energy of the substance is changing, because the relationship between neighboring atoms and molecules changes. Going from solid to liquid, for example, the solid phase of the material might have a particular crystal structure, and the internal energy depends on the structure. In the liquid phase, there is no crystal structure, so the internal energy is quite different (higher, generally) from what it is in the solid phase.
The change in internal energy associated with a change in phase is known as the latent heat. For a liquid-solid phase change, it's called the latent heat of fusion. For the gas-liquid phase change, it's the latent heat of vaporization, which is generally larger than the latent heat of fusion. Latent heats are relatively large compared to the heat required to change the temperature of a substance by 1° C.
If you use the sum-of-all-the-Q's equals zero equation, you have to
be careful with the heat associated with something changing phase
because you need to put it in with the appropriate sign. If heat is
going into a substance changing phase, such as when it's melting or
boiling, the Q is positive; if heat is being removed, such as when it's
freezing or condensing, the Q is negative. We don't have to worry about
the signs for the heat required to change temperature, because the sign
is already built in to the change in temperature.
The textbook use an alternate approach (see example 14-5 on
page 422). In that method, all the heat losses are set equal to all the
heat gains, with everything (even the changes in temperature) going in
with positive signs.
Note that a change in phase takes place only under the right
conditions. Water, for example, doesn't freeze at 10 °C, at least not
at atmospheric pressure. If you had water at that temperature, you
would first need to cool it to the melting point, 0 °C, before it would
start to freeze.
If you're putting in heat from an outside source, the sum-of-all-the-Q's equation becomes:
Subject:
Subject X2:
Heat transfer
12-6-99
Sections 14.7-14.9
Heat transfer
There are three basic ways in which heat is transferred. In fluids, heat is often transferred by convection, in which the motion of the fluid itself carries heat from one place to another. Another way to transfer heat is by conduction, which does not involve any motion of a substance, but rather is a transfer of energy within a substance (or between substances in contact). The third way to transfer energy is by radiation, which involves absorbing or giving off electromagnetic waves.
Convection
Heat transfer in fluids generally takes place via convection. Convection currents are set up in the fluid because the hotter part of the fluid is not as dense as the cooler part, so there is an upward buoyant force on the hotter fluid, making it rise while the cooler, denser, fluid sinks. Birds and gliders make use of upward convection currents to rise, and we also rely on convection to remove ground-level pollution.
Forced convection, where the fluid does not flow of its own accord but is pushed, is often used for heating (e.g., forced-air furnaces) or cooling (e.g., fans, automobile cooling systems).
Conduction
When heat is transferred via conduction, the substance itself does not flow; rather, heat is transferred internally, by vibrations of atoms and molecules. Electrons can also carry heat, which is the reason metals are generally very good conductors of heat. Metals have many free electrons, which move around randomly; these can transfer heat from one part of the metal to another.
The equation governing heat conduction along something of length (or thickness) L and cross-sectional area A, in a time t is:
k is the thermal conductivity, a constant depending only on the material, and having units of J / (s m °C).
Copper, a good thermal conductor, which is why some pots and pans have copper bases, has a thermal conductivity of 390 J / (s m °C). Styrofoam, on the other hand, a good insulator, has a thermal conductivity of 0.01 J / (s m °C).
Example
Consider what happens when a layer of ice builds up in a freezer. When this happens, the freezer is much less efficient at keeping food frozen. Under normal operation, a freezer keeps food frozen by transferring heat through the aluminum walls of the freezer. The inside of the freezer is kept at -10 °C; this temperature is maintained by having the other side of the aluminum at a temperature of -25 °C.
The aluminum is 1.5 mm thick. Let's take the thermal conductivity of aluminum to be 240 J / (s m °C). With a temperature difference of 15°, the amount of heat conducted through the aluminum per second per square meter can be calculated from the conductivity equation:
This is quite a large heat-transfer rate. What happens if 5 mm of
ice builds up inside the freezer, however? Now the heat must be
transferred from the freezer, at -10 °C, through 5 mm of ice, then
through 1.5 mm of aluminum, to the outside of the aluminum at -25 °C.
The rate of heat transfer must be the same through the ice and the
aluminum; this allows the temperature at the ice-aluminum interface to
be calculated.
Setting the heat-transfer rates equal gives:
The thermal conductivity of ice is 2.2 J / (s m °C). Solving for T gives:
Now, instead of heat being transferred through the aluminum with a
temperature difference of 15°, the difference is only 0.041°. This
gives a heat transfer rate of:
With a layer of ice covering the walls, the rate of heat transfer is reduced by a factor of more than 300! It's no wonder the freezer has to work much harder to keep the food cold.
Radiation
The third way to transfer heat, in addition to convection and conduction, is by radiation, in which energy is transferred in the form of electromagnetic waves. We'll talk about electromagnetic waves in a lot more detail in PY106; an electromagnetic wave is basically an oscillating electric and magnetic field traveling through space at the speed of light. Don't worry if that definition goes over your head, because you're already familiar with many kinds of electromagnetic waves, such as radio waves, microwaves, the light we see, X-rays, and ultraviolet rays. The only difference between the different kinds is the frequency and wavelength of the wave.
Note that the radiation we're talking about here, in regard to heat transfer, is not the same thing as the dangerous radiation associated with nuclear bombs, etc. That radiation comes in the form of very high energy electromagnetic waves, as well as nuclear particles. The radiation associated with heat transfer is entirely electromagnetic waves, with a relatively low (and therefore relatively safe) energy.
Everything around us takes in energy from radiation, and gives it off in the form of radiation. When everything is at the same temperature, the amount of energy received is equal to the amount given off. Because there is no net change in energy, no temperature changes occur. When things are at different temperatures, however, the hotter objects give off more energy in the form of radiation than they take in; the reverse is true for the colder objects.
The amount of energy an object radiates depends strongly on temperature. For an object with a temperature T (in Kelvin) and a surface area A, the energy radiated in a time t is given by the Stefan-Boltzmann law of radiation:
The constant e is known as the emissivity, and it's a measure of the
fraction of incident radiation energy is absorbed and radiated by the
object. This depends to a large extent on how shiny it is. If an object
reflects a lot of energy, it will absorb (and radiate) very little; if
it reflects very little energy, it will absorb and radiate quite
efficiently. Black objects, for example, generally absorb radiation
very well, and would have emissivities close to 1. This is the largest
possible value for the emissivity, and an object with e = 1 is called a
perfect blackbody,
Note that the emissivity of an object depends on the wavelength
of radiation. A shiny object may reflect a great deal of visible light,
but it may be a good absorber(and therefore emitter) of radiation of a
different wavelength, such as ultraviolet or infrared light.
Note that the emissivity of an object is a measure of not just
how well it absorbs radiation, but also of how well it radiates the
energy. This means a black object that absorbs most of the radiation it
is exposed to will also radiate energy away at a higher rate than a
shiny object with a low emissivity.
The Stefan-Boltzmann law tells you how much energy is radiated
from an object at temperature T. It can also be used to calculate how
much energy is absorbed by an object in an environment where everything
around it is at a particular temperature :
The net energy change is simply the difference between the radiated
energy and the absorbed energy. This can be expressed as a power by
dividing the energy by the time. The net power output of an object of
temperature T is thus:
Heat transfer in general
We've looked at the three types of heat transfer. Conduction and convection rely on temperature differences; radiation does, too, but with radiation the absolute temperature is important. In some cases one method of heat transfer may dominate over the other two, but often heat transfer occurs via two, or even all three, processes simultaneously.
A stove and oven are perfect examples of the different kinds of heat transfer. If you boil water in a pot on the stove, heat is conducted from the hot burner through the base of the pot to the water. Heat can also be conducted along the handle of the pot, which is why you need to be careful picking the pot up, and why most pots don't have metal handles. In the water in the pot, convection currents are set up, helping to heat the water uniformly. If you cook something in the oven, on the other hand, heat is transferred from the glowing elements in the oven to the food via radiation.
Subject:
Subject X2:
Ideal Gas Law
The gas laws
12-1-99
Sections 13.7 - 13.10
A bit of chemistry
Let's delve into some concepts that you might associate with chemistry, but which are equally relevant to physics. The first is the idea of the mole, and Avogadro's number. A mole is a number like a dozen, just a lot bigger. A dozen means 12; a mole means 6.022 x 1023. That number, 6.022 x 1023, is known as Avogadro's number.
You can have a mole of eggs, just as you can have a dozen eggs, but a mole is more useful when it's applied to elements. A mole of aluminum and a mole of lead both have 6.022 x 1023 atoms. The mole of lead has more mass, though, because a mole of an element has a mass in grams equal to the atomic mass listed in the periodic table of elements. A mole of lead, then, has a mass of 207.2 g while a mole of aluminum has a mass of 26.9815 g.
A mole of an element has a mass conveniently measured in grams. A single atom, on the other hand, has a mass which is just a small fraction of a gram. A single atom of aluminum, for example, has a mass of:
Note that this is the mass of an average atom of aluminum, accounting for different isotopes.
The mass of individual atoms are more conveniently measured in atomic mass units (u). 1 u = 1.66 x 10-24 g = 1.66 x 10-27 kg. For aluminum, then, which has an atomic mass of 26.9815, one mole has a mass of 26.9815 g and an average atom has a mass of 26.9815 u.
The gas laws
Although we're now familiar with the ideal gas law, which relates the pressure, volume, and temperature of an ideal gas in one compact equation, it's useful to spend a few minutes on the history of gas laws. Three names in particular are associated with gas laws, those being Robert Boyle (1627 - 1691), Jacques Charles (1746-1823), and J.L. Gay-Lussac (1778-1850).
Boyle showed that for a fixed amount of gas at constant temperature, the pressure and volume are inversely proportional to one another. In other words:
Boyle's law : PV = constant.
In Charles' law, it is the pressure that is kept constant. Under this constraint, the volume is proportional to the temperature. This can be expressed as :
Charles' law : V1 / T1 = V2 / T2
When the volume is kept constant, it is the pressure of the gas that is proportional to temperature:
Gay-Lussac's law : P1 / T1 = P2 / T2
All of the above laws are combined in the ideal gas law. Before stating that, we should summarize what constitutes an ideal gas.
An ideal gas
An ideal gas has a number of properties; real gases often exhibit behavior very close to ideal. The properties of an ideal gas are:
1. An ideal gas consists of a large number of identical molecules.
2. The volume occupied by the molecules themselves is negligible compared to the volume occupied by the gas.
3. The molecules obey Newton's laws of motion, and they move in random motion.
4. The molecules experience forces only during collisions; any collisions are completely elastic, and take a negligible amount of time.
The ideal gas law
An ideal gas is an idealized model of real gases; real gases follow ideal gas behavior if their density is low enough that the gas molecules don't interact much, and when they do interact they undergo elastic collisions, with no loss of kinetic energy.
The behavior of an ideal gas, that is, the relationship of pressure (P), volume (V), and temperature (T), can be summarized in the ideal gas law:
Ideal gas law : PV = nRT
where n is the number of moles of gas, and R = 8.31 J / (mol K) is known as the universal gas constant.
An alternate way to express the ideal gas law is in terms of N, the number of molecules, rather than n, the number of moles. N is simply n multiplied by Avogadro's number, so the ideal gas law can be written as:
We'll come back to the ideal gas law, but let's back up a little and
get a feel for pressure on the molecular level. This gets us into the
theory of the motion of gas molecules, known as the kinetic theory of
gases.
Subject:
Subject X2:
Kinectic Theory
12-1-99
Sections 13.11 - 13.15
We're now going to draw on much of what we've learned in this course to
understand the motion of gases at the molecular level. We'll examine
the ideal gas law from the perspective of physics, and we'll come to a
deeper understanding of what temperature is.
Kinetic theory
Consider a cube-shaped box, each side of length L, filled with
molecules of an ideal gas. A molecule of ideal gas is like a bouncy
rubber ball; whenever it's involved in a collision with a wall of the
box, it rebounds with the same kinetic energy it had before hitting the
wall. Similarly, if ideal gas molecules collide, the collisions are
elastic, so no kinetic energy is lost.
Now consider one of these ideal gas molecules in this box, with a mass
m and velocity v. If this molecule bounces off one of the walls
perpendicular to the x-direction, the y and z components of the
molecule's velocity are unaffected, and the x-component of velocity
reverses. The molecule maintains the same speed, because the collsion
is elastic. How much force, on average, does it exert on the wall?
To answer this we just have to think about momentum, and impulse.
Momentum is a vector, so if the particle reverses its x-component of
momentum there is a net change in momentum of 2 m vx. The magnitude of
the average force exerted by the wall to produce this change in
momentum can be found from the impulse equation:
If we're dealing with the average force, the time interval is just
the time between collisions, which is the time it takes for the
molecule to make a round trip in the box and come back to hit the same
wall. This time simply depends on the distance travelled in the
x-direction (2L), and the x-component of velocity; the time between
collisions with that wall is 2L / vx.
Solving for the average force gives:
This is the magnitude of the average force exerted by the wall on
the molecule, as well as the magnitude of the average force exerted by
the molecule on the wall; the forces are equal and opposite.
This is just the average force exerted on one wall by one
molecule selected at random. To find the total force, we need to
include all the other molecules, which travel at a wide range of
speeds. The distribution of speeds follows a curve that looks a lot
like a Bell curve, with the peak of the distribution increasing as the
temperature increases. The shape of the speed distribution is known as
a Maxwellian distribution curve, named after James Clerk Maxwell, the
Scottish physicist who first worked it out.
To find the total force on the wall, then, we can just add up all the individual forces:
Multiplying and dividing the right-hand side by N, the number of molecules in the box, gives:
The term in square brackets is simply an average...we're adding up the
square of the x-component of velocity for all the molecules and
dividing by the number of molecules. This average is known as the
root-mean-square average, symbolized by rms.
Therefore:
Consider now how this average x velocity compares to the average
velocity. For any molecule, the velocity can be found from its
components using the Pythagorean theorem in three dimensions:
For a randomly-chosen molecule, the x, y, and z components of velocity
may be similar but they don't have to be. If we take an average over
all the molecules in the box, though, then the average x, y, and z
speeds should be equal, because there's no reason for one direction to
be preferred over another. So:
The force exerted by the molecules on a wall of the box can then be
expressed in terms of the average velocity, rather than the average x
component of velocity.
The pressure exerted by the gas on each wall is simply the force divided by the area of a wall. Therefore:
Rearranging things a little gives:
This equation has many of the same variables as the ideal gas law, PV = NkT. This means that:
This is a very important result, because it tells us something
fundamental about temperature. The absolute temperature of an ideal gas
is proportional to the average kinetic energy per gas molecule. If
changes in pressure and/or volume result in changes in temperature, it
means the average kinetic energy of the molecules has been changed.
The internal energy of an ideal gas
The result above says that the average translational kinetic energy
of a molecule in an ideal gas is 3/2 kT. For a gas made up of single
atoms (the gas is monatomic, in other words), the translational kinetic
energy is also the total internal energy. Rotational kinetic energy can
be ignored, because the atoms are so small that the moment of inertia
is negligible.There is also no energy associated with bonds between
atoms in molecules, because there are no bonds in a monatomic gas. For
a monatomic ideal gas, then, the total internal energy (U) is simply:
Note that gases made up of molecules with more than one atom per
molecule have more internal energy than 3/2 nRT, because energy is
associated with the bonds and the vibration of the molecules. Another
interesting result involves the equipartition of energy, which says
that each contributer to the internal energy contributes an equal
amount of energy. For a monatomic ideal gas, each of the three
directions (x, y, and z) contribute 1/2 kT per molecule, for a total of
3/2 kT per molecule.
For a diatomic molecule, the three translation direction contribute 1/2
kT per molecule, and for each molecule there are also two axes of
rotation, contributing rotational kinetic energy in the amount of 1/2
kT each. This amounts to a total internal energy of U = 5/2 NkT for a
diatomic gas, and a polyatomic gas has contributions from three
translation direction and three axes of rotation, giving U = 6/2 NkT,
or 3NkT.
Diffusion
Physics is full of cases where similar behavior in different kinds
of systems can be described by similar equations. Diffusion, for
example, the flow of a substance from a region of higher concentration
to a region of lower concentration, is a similar process to thermal
conductivity, which involves heat flowing from a higher temperature
region to a lower temperature region. The similarities can be seen in
the equations:
Both equations involve a length, a time, a cross-sectional area, and
a constant. D is the diffusion constant, while k is the thermal
conductivity; both depend on what the flow is passing through. In
addition, both equations involve differences; temperature difference
for heat flow, and a concentration difference in the case of the mass
flow.
Always look for parallels. If you can relate one system back to
another system you already understand, you'll be able to figure out the
new system much more easily.
Subject:
Subject X2:
Temperature and Thermal Expansion
11-29-99
Sections 13.1 - 13.6
We'll shift gears in the course now, moving from the physics of mechanical systems to thermal physics.
Temperature scales
In the USA, the Fahrenheit temperature scale is used. Most of the rest of the world uses Celsius, and in science it is often most convenient to use the Kelvin scale.
The Celsius scale is based on the temperatures at which water freezes and boils. 0°C is the freezing point of water, and 100° C is the boiling point. Room temperature is about 20° C, a hot summer day might be 40° C, and a cold winter day would be around -20° C.
To convert between Fahrenheit and Celsius, use these equations:
The two scales agree when the temperature is -40°. A change by 1.0° C is a change by 1.8° F.
The Kelvin scale has the same increments as the Celsius scale (100 degrees between the freezing and boiling points of water), but the zero is in a different place. The two scales are simply offset by 273.15 degrees. The zero of the Kelvin scale is absolute zero, which is the lowest possible temperature that a substance can be cooled to. Several physics formulas involving temperature only make sense when an absolute temperature (a temperature measured in Kelvin) is used, so the fact that the Kelvin scale is an absolute scale makes it very convenient to apply to scientific work.
Measuring temperature
A device used to measure temperature is called a thermometer, and all thermometers exploit the fact that properties of a material depend on temperature. The pressure in a sealed bulb depends on temperature; the volume occupied by a liquid depends on temperature; the voltage generated across a junction of two different metals depends on temperature, and all these effects can be used in thermometers.
Linear thermal expansion
The length of an object is one of the more obvious things that depends on temperature. When something is heated or cooled, its length changes by an amount proportional to the original length and the change in temperature:
The coefficient of linear expansion depends only on the material an object is made from.
If an object is heated or cooled and it is not free to expand or contract (it's tied down at both ends, in other words), the thermal stresses can be large enough to damage the object, or to damage whatever the object is constrained by. This is why bridges have expansion joints in them (check this out where the BU bridge meets Comm. Ave.). Even sidewalks are built accounting for thermal expansion.
Holes expand and contract the same way as the material around them.
Example
This is similar to problem 12.20 in the text. Consider a 2 m long brass rod and a 1 m long aluminum rod. When the temperature is 22 °C, there is a gap of 1.0 x 10-3 m separating their ends. No expansion is possible at the other end of either rod. At what temperature will the two bars touch?
The change in temperature is the same for both, the original length is
known for both, and the coefficients of linear expansion can be found
from Table 12.2 in the textbook.
Both rods will expand when heated. They will touch when the sum of the
two length changes equals the initial width of the gap. Therefore:
So, the temperature change is:
If the original temperature was 22 °C, the final temperature is 38.4 °C.
Thermal expansion : expanding holes
Consider a donut, a flat, two-dimensional donut, just to make things a little easier. The donut has a hole, with radius r, and an outer radius R. It has a width w which is simply w = R - r.
What happens when the donut is heated? It expands, but what happens to the hole? Does it get larger or smaller? If you apply the thermal expansion equation to all three lengths in this problem, do you get consistent results? The three lengths would change as follows:
The final width should also be equal to the difference between the outer and inner radii. This gives:
This is exactly what we got by applying the linear thermal expansion equation to the width of the donut above. So, with something like a donut, an increase in temperature causes the width to increase, the outer radius to increase, and the inner radius to increase, with all dimensions obeying linear thermal expansion. The hole expands just as if it's made as the same material as the hole.
Volume thermal expansion
When something changes temperature, it shrinks or expands in all three dimensions. In some cases (bridges and sidewalks, for example), it is just a change in one dimension that really matters. In other cases, such as for a mercury or alcohol-filled thermometer, it is the change in volume that is important. With fluid-filled containers, in general, it's how the volume of the fluid changes that's important. Often you can neglect any expansion or contraction of the container itself, because liquids generally have a substantially larger coefficient of thermal expansion than do solids. It's always a good idea to check in a given situation, however, comparing the two coefficients of thermal expansion for the liquid and solid involved.
The equation relating the volume change to a change in temperature has the same form as the linear expansion equation, and is given by:
The volume expansion coefficient is three times larger than the linear expansion coefficient.
Subject:
Subject X2:
The first Law of Thermodynamics
12-8-99
Sections 15.1 - 15.4
Thermodynamics
Thermodynamics is the study of systems involving energy in the form of heat and work. A good example of a thermodynamic system is gas confined by a piston in a cylinder. If the gas is heated, it will expand, doing work on the piston; this is one example of how a thermodynamic system can do work.
Thermal equilibrium is an important concept in thermodynamics. When two systems are in thermal equilibrium, there is no net heat transfer between them. This occurs when the systems are at the same temperature. In other words, systems at the same temperature will be in thermal equilibrium with each other.
The first law of thermodynamics relates changes in internal energy to heat added to a system and the work done by a system. The first law is simply a conservation of energy equation:
The internal energy has the symbol U. Q is positive if heat is added
to the system, and negative if heat is removed; W is positive if work
is done by the system, and negative if work is done on the system.
We've talked about how heat can be transferred, so you probably
have a good idea about what Q means in the first law. What does it mean
for the system to do work? Work is simply a force multiplied by the
distance moved in the direction of the force. A good example of a
thermodynamic system that can do work is the gas confined by a piston
in a cylinder, as shown in the diagram.
If the gas is heated, it will expand and push the piston up, thereby doing work on the piston. If the piston is pushed down, on the other hand, the piston does work on the gas and the gas does negative work on the piston. This is an example of how work is done by a thermodynamic system. An example with numbers might make this clearer.
An example of work done
Consider a gas in a cylinder at room temperature (T = 293 K), with a volume of 0.065 m3. The gas is confined by a piston with a weight of 100 N and an area of 0.65 m2. The pressure above the piston is atmospheric pressure.
(a) What is the pressure of the gas?
This can be determined from a free-body diagram of the piston. The weight of the piston acts down, and the atmosphere exerts a downward force as well, coming from force = pressure x area. These two forces are balanced by the upward force coming from the gas pressure. The piston is in equilibrium, so the forces balance. Therefore:
Solving for the pressure of the gas gives:
The pressure in the gas isn't much bigger than atmospheric pressure, just enough to support the weight of the piston.
(b) The gas is heated, expanding it and moving the piston up. If
the volume occupied by the gas doubles, how much work has the gas done?
An assumption to make here is that the pressure is constant.
Once the gas has expanded, the pressure will certainly be the same as
before because the same free-body diagram applies. As long as the
expansion takes place slowly, it is reasonable to assume that the
pressure is constant.
If the volume has doubled, then, and the pressure has remained
the same, the ideal gas law tells us that the temperature must have
doubled too.
The work done by the gas can be determined by working out the
force applied by the gas and calculating the distance. However, the
force applied by the gas is the pressure times the area, so:
W = F s = P A s
and the area multiplied by the distance is a volume,
specifically the change in volume of the gas. So, at constant pressure,
work is just the pressure multiplied by the change in volume:
This is positive because the force and the distance moved are in the same direction, so this is work done by the gas.
The pressure-volume graph
As has been discussed, a gas enclosed by a piston in a cylinder can do work on the piston, the work being the pressure multiplied by the change in volume. If the volume doesn't change, no work is done. If the pressure stays constant while the volume changes, the work done is easy to calculate. On the other hand, if pressure and volume are both changing it's somewhat harder to calculate the work done.
As an aid in calculating the work done, it's a good idea to draw a pressure-volume graph (with pressure on the y axis and volume on the x-axis). If a system moves from one point on the graph to another and a line is drawn to connect the points, the work done is the area underneath this line. We'll go through some different thermodynamic processes and see how this works.
Types of thermodynamic processes
There are a number of different thermodynamic processes that can change the pressure and/or the volume and/or the temperature of a system. To simplify matters, consider what happens when something is kept constant. The different processes are then categorized as follows :
1. Isobaric - the pressure is kept constant. An example of an isobaric system is a gas, being slowly heated or cooled, confined by a piston in a cylinder. The work done by the system in an isobaric process is simply the pressure multiplied by the change in volume, and the P-V graph looks like:
2. Isochoric - the volume is kept constant. An example of this system is a
gas in a box with fixed walls. The work done is zero in an isochoric
process, and the P-V graph looks like:
3. Isothermal - the temperature is kept constant. A gas confined by a piston in a cylinder is again an example of this, only this time the gas is not heated or cooled, but the piston is slowly moved so that the gas expands or is compressed. The temperature is maintained at a constant value by putting the system in contact with a constant-temperature reservoir (the thermodynamic definition of a reservoir is something large enough that it can transfer heat into or out of a system without changing temperature).
If the volume increases while the temperature is constant, the pressure must decrease, and if the volume decreases the pressure must increase.
4. Adiabatic - in an adiabatic process, no heat is added or removed from the system.
The isothermal and adiabatic processes should be examined in a little more detail.
Isothermal processes
In an isothermal process, the temperature stays constant, so the pressure and volume are inversely proportional to one another. The P-V graph for an isothermal process looks like this:
The work done by the system is still the area under the P-V curve, but
because this is not a straight line the calculation is a little tricky,
and really can only properly be done using calculus.
The internal energy of an ideal gas is proportional to the temperature, so if the temperature is kept fixed the internal energy does not change. The first law, which deals with changes in the internal energy, thus becomes 0 = Q - W, so Q = W. If the system does work, the energy comes from heat flowing into the system from the reservoir; if work is done on the system, heat flows out of the system to the reservoir.
Adiabatic processes
In an adiabatic process, no heat is added or removed from a system. The first law of thermodynamics is thus reduced to saying that the change in the internal energy of a system undergoing an adiabatic change is equal to -W. Since the internal energy is directly proportional to temperature, the work becomes:
An example of an adiabatic process is a gas expanding so quickly that
no heat can be transferred. The expansion does work, and the
temperature drops. This is exactly what happens with a carbon dioxide
fire extinguisher, with the gas coming out at high pressure and cooling
as it expands at atmospheric pressure.
Specific heat capacity of an ideal gas
With liquids and solids that are changing temperature, the heat associated with a temperature change is given by the equation:
A similar equation holds for an ideal gas, only instead of writing the
equation in terms of the mass of the gas it is written in terms of the
number of moles of gas, and use a capital C for the heat capacity, with
units of J / (mol K):
For an ideal gas, the heat capacity depends on what kind of
thermodynamic process the gas is experiencing. Generally, two different
heat capacities are stated for a gas, the heat capacity at constant
pressure (Cp) and the heat capacity at constant volume (Cv).
The value at constant pressure is larger than the value at constant
volume because at constant pressure not all of the heat goes into
changing the temperature; some goes into doing work. On the other hand,
at constant volume no work is done, so all the heat goes into changing
the temperature. In other words, it takes less heat to produce a given
temperature change at constant volume than it does at constant
pressure, so Cv < Cp.
That's a qualitative statement about the two different heat
capacities, but it's very easy to examine them quantitatively. The
first law says:
We also know that PV = nRT, and at constant pressure the work done is:
Note that this applies for a monatomic ideal gas. For all gases, though, the following is true:
Another important number is the ratio of the two specific heats, represented by the Greek letter gamma (g). For a monatomic ideal gas this ratio is:
Subject:
Subject X2:
Magnetism
Subject:
Subject X2:
Ferromagnetism
Magnetic materials
7-20-99
Ferromagnets
A ferromagnetic material is one that has magnetic properties similar to those of iron. In other words, you can make a magnet out of it. Some other ferromagnetic materials are nickel, cobalt, and alnico, an aluminum-nickel-cobalt alloy.
Magnetic fields come from currents. This is true even in ferromagnetic materials; their magnetic properties come from the motion of electrons in the atoms. Each electron has a spin. This is a quantum mechanical phenomenon that is difficult to make a comparison to, but can be thought of as similar to the rotation of the Earth about its axis.
Electron spins are in one of two states, up or down. This is another way of stating that the magnetic quantum number can be +1/2 or -1/2. Electrons are arranged in shells and orbitals in an atom. If they fill the orbitals so that there are more spins pointing up than down (or vice versa), each atom will act like a tiny magnet.
That's not the whole picture, however; in non-magnetic materials such as aluminum, neighboring atoms do not align themselves with each other or with an external magnetic field. In ferromagnetic materials, the spins of neighboring atoms do align (through a quantum effect known as exchange coupling), resulting in small (a tenth of a millimeter, or less) neighborhoods called domains where all the spins are aligned. When a piece of unmagnetized iron (or other ferromagnetic material) is exposed to an external magnetic field, two things happen. First, the direction of magnetization (the way the spins point) of each domain will tend to shift towards the direction of the field. Secondly, domains which are aligned with the field will expand to take over regions occupied by domains aligned opposite to the field. This is what is meant by magnetizing a piece of iron.
Iron comes in two forms, hard and soft. If you were hit on the head with a soft iron bar, it would still feel very hard; soft is simply a term describing the magnetic properties. In hard iron, the domains will not shift back to their starting points when the field is taken away. In soft iron, the domains return to being randomly aligned when the field is removed.
Hard iron is used in permanent magnets. To make a permanent magnet, a piece of hard iron is placed in a magnetic field. The domains align with the field, and retain a good deal of that alignment when the field is removed, resulting in a magnet.
An electromagnet, in contrast, uses soft iron; this allows the field to be turned on and off. It's easy to make an electromagnet. One method is to coil a wire around a nail (made of iron or steel), and connect the two ends of the wire to a battery. A coil of wire with a current running through it acts as a magnet all by itself, so why is the nail necessary? The answer is that when the domains in the nail align with the field produced by the current, the magnetic field is magnified by a large factor, typically by 100 - 1000 times.
Magnetic effects are sensitive to temperature. It is much easier to keep permanent magnets magnetized at low temperatures, because at higher temperatures the atoms tend to move around much more, throwing the spins out of alignment. Above a critical temperature known as the Curie temperature, ferromagnets lose their ferromagnetic properties.
Subject:
Subject X2:
Forces and Torques; Examples
Forces on currents in magnetic fields
7-15-99
The magnetic force on a current-carrying wire
A magnetic field will exert a force on a single moving charge, so it follows that it will also exert a force on a current, which is a collection of moving charges.
The force experienced by a wire of length l carrying a current I in a magnetic field B is given by
Again, the right-hand rule can be used to find the direction of the force. In this case, your thumb points in the direction of the current, your fingers point in the direction of B. Your palm gives the direction of F.
The force between two parallel wires
Parallel wires carrying currents will exert forces on each other. One wire sets up a magnetic field that influences the other wire, and vice versa. When the current goes the same way in the two wires, the force is attractive. When the currents go opposite ways, the force is repulsive. You should be able to confirm this by looking at the magnetic field set up by one current at the location of the other wire, and by applying the right-hand rule.
Here's the approach. In the picture above, both wires carry current
in the same direction. To find the force on wire 1, look first at the
magnetic field produced by the current in wire 2. Everywhere to the
right of wire 2, the field due to that current is into the page.
Everywhere to the left, the field is out of the page. Thus, wire 1
experiences a field that is out of the page.
Now apply the right hand rule to get the direction of the force
experienced by wire 1. The current is up (that's your fingers) and the
field is out of the page (curl your fingers that way). Your thumb
should point right, towards wire 2. The same process can be used to
figure out the force on wire 2, which points toward wire 1.
Reversing one of the currents reverses the direction of the forces.
The magnitude of the force in this situation is given by F =
IlB. To get the force on wire 1, the current is the current in wire 1.
The field comes from the other wire, and is proportional to the current
in wire 2. In other words, both currents come into play. Using the
expression for the field from a long straight wire, the force is given
by:
Note that it is often the force per unit length, F / l, that is asked for rather than the force.
The torque on a current loop
A very useful effect is the torque exerted on a loop by a magnetic field, which tends to make the loop rotate. Many motors are based on this effect.
The torque on a coil with N turns of area A carrying a current I is given by:
The combination NIA is usually referred to as the magnetic moment of the coil. It is a vector normal (i.e., perpendicular) to the loop. If you curl your fingers in the direction of the current around the loop, your thumb will point in the direction of the magnetic moment.
Applications of magnetic forces and fields
There are a number of good applications of the principle that a magnetic field exerts a force on a moving charge. One of these is the mass spectrometer : a mass spectrometer separates charged particles (usually ions) based on their mass.
The mass spectrometer
The mass spectrometer involves three steps. First the ions are accelerated to a particular velocity; then just those ions going a particular velocity are passed through to the third and final stage where the separation based on mass takes place. It's worth looking at all three stages because they all rely on principles we've learned in this course.
Step 1 - Acceleration
In physics, we usually talk about charged particles (or ions) being accelerated through a potential difference of so many volts. What this means is that we're applying a voltage across a set of parallel plates, and then injecting the ions at negligible speed into the are between the plates near the plate that has the same sign charge as the ions. The ions will be repelled from that plate, attracted to the other one, and if we cut a hole in the second one they will emerge with a speed that depends on the voltage.
The simplest way to figure out how fast the ions are going is to analyze it in terms of energy. When the ions enter the region between the plates, the ions have negligible kinetic energy, but plenty of potential energy. If the plates have a potential difference of V, the potential energy is simply U = qV. When the ions reach the other plate, all this energy has been converted into kinetic energy, so the speed can be calculated from:
Step 2 - the velocity selector
The ions emerge from the acceleration stage with a range of speeds. To distinguish between the ions based on their masses, they must enter the mass separation stage with identical velocities. This is done using a velocity selector, which is designed to allow ions of only a particular velocity to pass through undeflected. Slower ions will generally be deflected one way, while faster ions will deflect another way. The velocity selector uses both an electric field and a magnetic field, with the fields at right angles to each other, as well as to the velocity of the incoming charges.
Let's say the ions are positively charged, and move from left to right across the page. An electric field pointing down the page will tend to deflect the ions down the page with a force of F = qE. Now, add a magnetic field pointing into the page. By the right hand rule, this gives a force of F = qvB which is directed up the page. Note that the magnetic force depends on the velocity, so there will be some particular velocity where the electric force qE and the magnetic force qvB are equal and opposite. Setting the forces equal, qE = qvB, and solving for this velocity gives v = E / B. So, a charge of velocity v = E / B will experience no net force, and will pass through the velocity selector undeflected.
Any charge moving slower than this will have the magnetic force reduced, and will bend in the direction of the electric force. A charge moving faster will have a larger magnetic force, and will bend in the direction of the magnetic force.
A velocity selector works just as well for negative charges, the only difference being that the forces are in the opposite direction to the way they are for positive charges.
Step 3 - mass separation
All these ions, with the same charge and velocity, enter the mass separation stage, which is simply a region with a uniform magnetic field at right angles to the velocity of the ions. Such a magnetic field causes the charges to follow circular paths of radius r = mv / qB. The only thing different for these particles is the mass, so the heavier ions travel in a circular path of larger radius than the lighter ones.
The particles are collected after they have traveled half a circle in the mass separator. All the particles enter the mass separator at the same point, so if a particle of mass m1 follows a circular path of radius r1, and a second mass m2 follows a circular path of radius r2, after half a circle they will be separated by the difference between the diameters of the paths after half a circle. The separation is
The Hall Effect
Another good application of the force exerted by moving charges is the Hall effect. The Hall effect is very interesting, because it is one of the few physics phenomena that tell us that current in wires is made up of negative charges. It is also a common way of measuring the strength of a magnetic field.
Start by picturing a wire of square cross-section, carrying a current out of the page. We want to figure out whether the charges flowing in that wire are positive, and out of the page, or negative, flowing in to the page. There is a uniform magnetic field pointing down the page.
First assume that the current is made up of positive charges flowing out of the page. With a magnetic field down the page, the right-hand rule indicates that these positive charges experience a force to the right. This will deflect the charges to the right, piling up positive charge on the right and leaving a deficit of positive charge (i.e., a net negative charge) on the left. This looks like a set of charged parallel plates, so an electric field pointing from right to left is set up inside the wire by these charges. The field builds up until the force experienced by the charges in this electric field is equal and opposite to the force applied on the charges by the magnetic field.
With an electric field, there is a potential difference across the wire that can be measured with a voltmeter. This is known as the Hall voltage, and in the case of the positive charges, the sign on the Hall voltage would indicate that the right side of the wire is positive.
Now, what if the charges flowing through the wire are really negative, flowing into the page? Applying the right-hand rule indicates a magnetic force pointing right. This tends to pile up negative charges on the right, resulting in a deficit of negative charge (i.e., a net positive charge) on the left. As above, an electric field is the result, but this time it points from left to right. Measuring the Hall voltage this time would indicate that the left side of the wire is negative.
So, the potential difference set up across the wire is of one sign for negative charges, and the other sign for positive charges, allowing us to distinguish between the two, and to tell that when charges flow in wires, they are negative. Note that the electric field, and the Hall voltage, increases as the magnetic field increases, which is why the Hall effect can be used to measure magnetic fields.
Subject:
Subject X2:
The Magnetic Field; The Force on a Charged Particle
Magnetic fields and how to make them
7-14-99
Magnetism
There is a strong connection between electricity and magnetism. With electricity, there are positive and negative charges. With magnetism, there are north and south poles. Similar to charges, like magnetic poles repel each other, while unlike poles attract.
An important difference between electricity and magnetism is that in electricity it is possible to have individual positive and negative charges. In magnetism, north and south poles are always found in pairs. Single magnetic poles, known as magnetic monopoles, have been proposed theoretically, but a magnetic monopole has never been observed.
In the same way that electric charges create electric fields around them, north and south poles will set up magnetic fields around them. Again, there is a difference. While electric field lines begin on positive charges and end on negative charges, magnetic field lines are closed loops, extending from the south pole to the north pole and back again (or, equivalently, from the north pole to the south pole and back again). With a typical bar magnet, for example, the field goes from the north pole to the south pole outside the magnet, and back from south to north inside the magnet.
Electric fields come from charges. So do magnetic fields, but from moving charges, or currents, which are simply a whole bunch of moving charges. In a permanent magnet, the magnetic field comes from the motion of the electrons inside the material, or, more precisely, from something called the electron spin. The electron spin is a bit like the Earth spinning on its axis.
The magnetic field is a vector, the same way the electric field is. The electric field at a particular point is in the direction of the force a positive charge would experience if it were placed at that point. The magnetic field at a point is in the direction of the force a north pole of a magnet would experience if it were placed there. In other words, the north pole of a compass points in the direction of the magnetic field.
One implication of this is that the magnetic south pole of the Earth is located near to the geographic north pole. This hasn't always been the case: every once in a while (a long while) something changes inside the Earth's core, and the earth's field flips direction. Even at the present time, while the Earth's magnetic field is relatively stable, the location of the magnetic poles is slowly shifting.
The symbol for magnetic field is the letter B. The unit is the tesla (T).
The magnetic field produced by currents in wires
The simplest current we can come up with is a current flowing in a straight line, such as along a long straight wire. The magnetic field from a such current-carrying wire actually wraps around the wire in circular loops, decreasing in magnitude with increasing distance from the wire. To find the direction of the field, you can use your right hand. If you curl your fingers, and point your thumb in the direction of the current, your fingers will point in the direction of the field. The magnitude of the field at a distance r from a wire carrying a current I is given by:
Currents running through wires of different shapes produce different
magnetic fields. Consider a circular loop with a current traveling in a
counter-clockwise direction around it (as viewed from the top). By
pointing your thumb in the direction of the current, you should be able
to tell that the magnetic field comes up through the loop, and then
wraps around on the outside, going back down. The field at the center
of a circular loop of radius r carrying a current I is given by:
For N loops put together to form a flat coil, the field is just multiplied by N:
f a number of current-carrying loops are stacked on top of each other
to form a cylinder, or, equivalently, a single wire is wound into a
tight spiral, the result is known as a solenoid. The field along the
axis of the solenoid has a magnitude of:
where n = N/L is the number of turns per unit length (or, in other words, the total number of turns over the total length).
The force on a charged particle in a magnetic field
An electric field E exerts a force on a charge q. A magnetic field B will also exert a force on a charge q, but only if the charge is moving (and not moving in a direction parallel to the field). The direction of the force exerted by a magnetic field on a moving charge is perpendicular to the field, and perpendicular to the velocity (i.e., perpendicular to the direction the charge is moving).
The equation that gives the force on a charge moving at a velocity v in a magnetic field B is:
This is a vector equation : F is a vector, v is a vector, and B is a vector. The only thing that is not a vector is q.
Note that when v and B are parallel (or at 180°) to each other,
the force is zero. The maximum force, F = qvB, occurs when v and B are
perpendicular to each other.
The direction of the force, which is perpendicular to both v
and B, can be found using your right hand, applying something known as
the right-hand rule. One way to do the right-hand rule is to do this:
point all four fingers on your right hand in the direction of v. Then
curl your fingers so the tips point in the direction of B. If you hold
out your thumb as if you're hitch-hiking, your thumb will point in the
direction of the force.
At least, your thumb points in the direction of the force as
long as the charge is positive. A negative charge introduces a negative
sign, which flips the direction of the force. So, for a negative charge
your right hand lies to you, and the force on the negative charge will
be opposite to the direction indicated by your right hand.
In a uniform field, a charge initially moving parallel to the
field would experience no force, so it would keep traveling in
straight-line motion, parallel to the field. Consider, however, a
charged particle that is initially moving perpendicular to the field.
This particle would experience a force perpendicular to its velocity. A
force perpendicular to the velocity can only change the direction of
the particle, and it can't affect the speed. In this case, the force
will send the particle into uniform circular motion. The particle will
travel in a circular path, with the plane of the circle being
perpendicular to the direction of the field.
In this case, the force applied by the magnetic field ( F =
qvB ) is the only force acting on the charged particle. Using Newton's
second law gives:
The particle is undergoing uniform circular motion, so the acceleration is the centripetal acceleration:
a = v2 / r
so, q v B = m v2 / r
A factor of v cancels out on both sides, leaving
q B = m v / r The radius of the circular path is then: r = m v / (q B)
A particle that is initially moving at some angle between
parallel and perpendicular to the field would follow a motion which is
a combination of circular motion and straight-line motion...it would
follow a spiral path. The axis of the spiral would be parallel to the
field.
To understand this, simply split the velocity of the particle into two components:
The field does not affect v-parallel in any way; this is where the straight line motion comes from. On the other hand, the field and v-perpendicular combine to produce circular motion. Superimpose the two motions and you get a spiral path.
Working in three dimensions
With the force, velocity, and field all perpendicular to each other, we have to work in three dimensions. It can be hard to draw in 3-D on a 2-D surface such as a piece of paper or a chalk board, so to represent something pointing in the third dimension, perpendicular to the page or board, we usually draw the direction as either a circle with a dot in the middle or a circle with an X in the middle.
Think of an arrow with a tip at one end and feathers at the other. If you look at an arrow coming toward you, you see the tip; if you look at an arrow going away from you, you see the X of the feathers. A circle with a dot, then, represents something coming out of the page or board at you; a circle with an X represents something going into the page or board.
The following diagram shows the path followed by two charges, one positive and one negative, in a magnetic field that points into the page:
Subject:
Subject X2:
Modern Physics
Subject:
Subject X2:
Nuclear Reactions
8-6-98
Ionizing radiation
Radiation in the form of a fast-moving particle is dangerous to life forms like us because each particle can ionize a lot of molecules. When a radioactive nucleus decays, the alpha, beta, or gamma particle released generally has an energy of hundreds of keV or even MeV. Ionizing a molecule takes only a few eV, so a fast-moving particle can easily ionize thousands of molecules.
Ionized molecules inside a cell are bad news because they change the chemistry, which can seriously affect how the cell behaves. A little radiation is generally fine; all of us receive some radiation exposure. A lot of radiation is generally to be avoided, however.
From a biological perspective, it makes most sense to talk about radiation from the point of view of absorbed dose. This is the absorbed energy divided by the mass of the material that is exposed to the radiation.
absorbed dose (Gy) = absorbed energy (J) / mass (kg)
The SI unit for absorbed dose is the gray (Gy). A more commonly used unit is the rad, which is a hundredth of a gray.
1 rad = 0.01 gray
Different kinds of radiation have different levels of effectiveness when it comes to ionizing molecules in living tissue. The absorbed dose really needs to be corrected for this, and the correction is an easy one. Different types of radiation are measured relative to 200 keV x-rays, and assigned a multiplication factor known as the relative biological effectiveness (RBE) based on how effective they are relative to 200 keV x-rays. The biologically-equivalent dose is measured in rem, and is given by:
Biologically-equivalent dose (rem) = Absorbed dose (rad) x RBE
Different RBE values are given here:
Fission and nuclear reactors
If a uranium atom absorbs a neutron it will be unstable, and will generally split into two fragments. This process, the splitting of a large nucleus into two smaller ones, is known as nuclear fission.
Many nuclear reactors use uranium as fuel to generate electricity. Although radioactive by-products are produced in the reactor, generating electricity in a nuclear reactor is much more efficient than using a chemical process, such as burning oil, gas, or coal. The chemical processes that occur during burning produce a few eV of energy per molecule. Splitting a uranium nucleus into two pieces produces an average of 200 MeV per nucleus, a factor of about 10^8 more energy per nucleus than you get from burning something.
Uranium-238 is by far the most naturally-abundant isotope of uranium; uranium-235, however, is much more likely to absorb a neutron and break apart. For this reason many reactors use enriched uranium, uranium with about 3% of U-235 (about 4 times as much as the natural abundance).
U-235 is most easily split by a slow-moving neutron. Such neutrons, with kinetic energy of 0.04 eV or less, are known as thermal neutrons. When a thermal neutron hits a U-235 nucleus and is absorbed, the nucleus generally splits into two big pieces and a few neutrons. Two of the possible reactions are:
As many as five neutrons can be released in a reaction, but the average number is 2.5. These neutrons are used to sustain the chain reaction in the reactor: neutrons don't have to be sent in continually because they are produced in the reactions. These neutrons have kinetic energies of several MeV, however, and this energy must be removed so the neutron becomes a thermal neutron and can be used to break apart another uranium nucleus. The neutrons are slowed to thermal energies by a moderator, which is often water.
A nuclear reactor is designed to safely sustain the chain reaction of fissioning nuclei in its core. To keep a reactor operating safely it must be ensured that, on average, each reaction produces one thermal neutron that is used to split apart another nucleus. If less than one, on average, carried on the chain, the chain would soon die out; this is known as subcritical. If exactly one neutron per reaction goes on take part in the chain reaction, the reactor is critical, meaning its operating at exactly the right level. The danger comes if more than one neutron per reaction goes on to sustain the chain; in this case the reactor would be supercritical, the rate of reaction would spiral out of control, and a meltdown could occur.
The system used to control the reaction rate is a set of rods that can be moved into or out of the reactor core. These rods absorb excess neutrons. If the reaction rate is too high, the rods are moved further into the core so more neutrons are absorbed, slowing the reaction rate to a safe level; a rate too low and the rods are moved out of the core so that more neutrons are available.
To sum up, then, a nuclear reactor requires these components:
1. fuel with nuclei that can be split using thermal neutrons
2. a moderator to slow down the high-energy neutrons produced in the reactions
3. control rods to control the rate at which the reaction occurs
Elementary particles
There is life beyond the nucleus; atoms may be made up of electrons, neutrons, and protons, but protons and neutrons are themselves made up of quarks. There are also plenty of exotic particles (muons, pions, etc. ). If you'd like to learn more about these things, one place to start is by going to The Particle Adventure home page on the web.
Subject:
Subject X2:
Radioactive Decay and Radioactivity
8-11-99
The nucleus
When we looked at the atom from the point of view of quantum mechanics,
we treated the nucleus as a positive point charge and focused on what
the electrons were doing. In many cases, such as in chemical reactions,
that's all that matters; in other cases, such as radioactivity, or for
nuclear reactions, what happens in the nucleus is critical, and the
electrons can be ignored.
A nucleus consists of a bunch of protons and neutrons; these are known
as nucleons. Each nucleus can be characterized by two numbers: A, the
atomic mass number, which is the total number of nucleons; and Z, the
atomic number, representing the number of protons. Any nucleus can be
written in a form like this:
where Al is the element (aluminum in this case), the 27 is the
atomic mass number (the number of neutrons plus the number of protons),
and the 13 is Z, the atomic number, the number of protons.
How big is a nucleus? We know that atoms are a few angstroms,
but most of the atom is empty space. The nucleus is much smaller than
the atom, and is typically a few femtometers. The nucleus can be
thought of as a bunch of balls (the protons and neutrons) packed into a
sphere, with the radius of the sphere being approximately:
The strong nuclear force
What holds the nucleus together? The nucleus is tiny, so the protons
are all very close together. The gravitational force attracting them to
each other is much smaller than the electric force repelling them, so
there must be another force keeping them together. This other force is
known as the strong nuclear force; it works only at small distances.
The strong nuclear force is a very strong attractive force for protons
and neutrons separated by a few femtometers, but is basically
negligible for larger distances.
The tug-of-war between the attractive force of the strong nuclear force
and the repulsive electrostatic force between protons has interesting
implications for the stability of a nucleus. Atoms with very low atomic
numbers have about the same number of neutrons and protons; as Z gets
larger, however, stable nuclei will have more neutrons than protons.
Eventually, a point is reached beyond which there are no stable nuclei:
the bismuth nucleus with 83 protons and 126 neutrons is the largest
stable nucleus. Nuclei with more than 83 protons are all unstable, and
will eventually break up into smaller pieces; this is known as
radioactivity.
Nuclear binding energy and the mass defect
A neutron has a slightly larger mass than the proton. These are
often given in terms of an atomic mass unit, where one atomic mass unit
(u) is defined as 1/12th of the mass of a carbon-12 atom.
Something should probably strike you as being a bit odd here. The
carbon-12 atom has a mass of 12.000 u, and yet it contains 12 objects
(6 protons and 6 neutrons) that each have a mass greater than 1.000 u.
The fact is that these six protons and six neutrons have a larger mass
when they're separated than when they're bound together into a
carbon-12 nucleus.
This is true for all nuclei, that the mass of the nucleus is a
little less than the mass of the individual neutrons and protons. This
missing mass is known as the mass defect, and is essentially the
equivalent mass of the binding energy.
Einstein's famous equation relates energy and mass:
If you convert some mass to energy, Einstein's equation tells you how
much energy you get. In any nucleus there is some binding energy, the
energy you would need to put in to split the nucleus into individual
protons and neutrons. To find the binding energy, then, all you need to
do is to add up the mass of the individual protons and neutrons and
subtract the mass of the nucleus:
The binding energy is then:
In a typical nucleus the binding energy is measured in MeV,
considerably larger than the few eV associated with the binding energy
of electrons in the atom. Nuclear reactions involve changes in the
nuclear binding energy, which is why nuclear reactions give you much
more energy than chemical reactions; those involve changes in electron
binding energies.
Radioactive decay
Many nuclei are radioactive. This means they are unstable, and will
eventually decay by emitting a particle, transforming the nucleus into
another nucleus, or into a lower energy state. A chain of decays takes
place until a stable nucleus is reached.
During radioactive decay, principles of conservation apply. Some of these we've looked at already, but the last is a new one:
* conservation of energy
* conservation of momentum (linear and angular)
* conservation of charge
* conservation of nucleon number
Conservation of nucleon number means that the total number of nucleons
(neutrons + protons) must be the same before and after a decay.
There are three common types of radioactive decay, alpha, beta, and
gamma. The difference between them is the particle emitted by the
nucleus during the decay process.
Alpha decay
In alpha decay, the nucleus emits an alpha particle; an alpha
particle is essentially a helium nucleus, so it's a group of two
protons and two neutrons. A helium nucleus is very stable.
An example of an alpha decay involves uranium-238:
The process of transforming one element to another is known as transmutation.
Alpha particles do not travel far in air before being absorbed; this
makes them very safe for use in smoke detectors, a common household
item.
Beta decay
A beta particle is often an electron, but can also be a positron, a
positively-charged particle that is the anti-matter equivalent of the
electron. If an electron is involved, the number of neutrons in the
nucleus decreases by one and the number of protons increases by one. An
example of such a process is:
In terms of safety, beta particles are much more penetrating than alpha particles, but much less than gamma particles.
Gamma decay
The third class of radioactive decay is gamma decay, in which the
nucleus changes from a higher-level energy state to a lower level.
Similar to the energy levels for electrons in the atom, the nucleus has
energy levels. The concepts of shells, and more stable nuclei having
filled shells, apply to the nucleus as well.
When an electron changes levels, the energy involved is usually a few
eV, so a visible or ultraviolet photon is emitted. In the nucleus,
energy differences between levels are much larger, typically a few
hundred keV, so the photon emitted is a gamma ray.
Gamma rays are very penetrating; they can be most efficiently absorbed
by a relatively thick layer of high-density material such as lead.
A list of known nuclei and their properties can be found in the on-line chart of the nuclides .
Radioactivity
Making a precise prediction of when an individual nucleus will decay is
not possible; however, radioactive decay is governed by statistics, so
it is very easy to predict the decay pattern of a large number of
radioactive nuclei. The rate at which nuclei decay is proportional to
N, the number of nuclei there are:
Whenever the rate at which something occurs is proportional to the
number of objects, the number of objects will follow an exponential
decay. In other words, the equation telling you how many objects there
are at a particular time looks like this:
The decay constant is closely related to the half-life, which is the
time it takes for half of the material to decay. Using the radioactive
decay equation, it's easy to show that the half-life and the decay
constant are related by:
The activity of a sample of radioactive material (i.e., a bunch of
unstable nuclei) is measured in disintegrations per second, the SI unit
for this being the becquerel.
Understanding half-life using M&M's
Please note that M&M's are perfectly safe, and are not
radioactive. M&M's can be used as a model of a sample of
radioactive nuclei, however, because when they lie on a flat surface
they can be in one of just two states - they can lie with the M up or
with the M down. Let one of those states (M down, say) represent
decayed nuclei.
With a package of M&M's, you can model a sample of decaying nuclei like this:
* step 1 - count the number of M&M's you have.
* step
2 - throw them onto a flat surface, and count the number of M&M's
with M up. Remove all the M down M&M's from the sample.
* step 3 - repeat step 2 until you have no M&M's left.
Every time you throw the M&M's, you've gone through one more half-life. Here's the data from one trial:
The above is just a single trial; you should try it yourself to see
what you get. This trial shows something interesting, however. When you
have a large number of particles, they follow the predicted behavior
very closely. When you only have a small number, the inherent
randomness of the decay process is a little more obvious.
Radioactive dating
Radioactivity is often used in determining how old something is;
this is known as radioactive dating. When carbon-14 is used, as is
often the case, the process is called radiocarbon dating, but
radioactive dating can involve other radioactive nuclei. The trick is
to use an appropriate half-life; for best results, the half-life should
be on the order of, or somewhat smaller than, the age of the object.
Carbon-14 is used because all living things take up carbon from the
atmosphere, so the proportion of carbon-14 in the carbon in a living
organism is the same as the proportion in the carbon-14 in the carbon
in the atmosphere. For many thousands of years this proportion has been
about 1 atom of C-14 for every 8.3 x 1011 atoms of carbon.
When an organism dies the carbon-14 slowly decays, so the proportion of
C-14 is reduced over time. Carbon-14 has a half life of 5730 years,
making it very useful for measuring ages of objects that are a few
thousand to several tens of thousands of years old. To measure the age
of something, then, you measure the activity of carbon-14, and compare
it to the activity you'd expect it to have if it was brand new.
Plugging these numbers into the decay equation along with the
half-life, you can calculate the time period over which the nuclei
decayed, which is the age of the object.
An example
Subject:
Subject X2:
Special Relativity
7-30-98
Physics close to the speed of light
Special relativity, developed by Albert Einstein, applies to situations
where objects are moving very quickly, at speeds near the speed of
light. Generally, you should account for relativistic effects when
speeds are higher than 1 / 10th of the speed of light.
Relativity produces very surprising results. We have no experience
dealing with objects traveling at such high speeds, so perhaps it
shouldn't be too surprising that we get surprising results. These are a
few of the things that happen at relativistic speeds:
* Moving clocks run slow.
* Lengths contract when traveling at high speeds.
* Two events that occur simultaneously for one observer are not
simultaneous for another observer in a different frame of reference if
the events take place in different locations.
That might sound very odd, but it only sounds odd because we don't see these effects in our daily lives.
Frames of reference
Everything is relative; it depends on your frame of reference.
Different observers see different things if they are in different
reference frames (i.e., they are moving relative to each other).
Special relativity deals with observers moving at constant velocity;
this is a lot easier than general relativity, in which observers can
accelerate with respect to each other. Note that frames of reference
where the velocity is constant are known is inertial frames.
Postulates of special relativity
Relativity is based on two very simple ideas; everything else follows from these. These are:
1. The relativity postulate : the laws of physics apply in every inertial reference frame.
2. The speed of light postulate : The speed of light in vacuum is the
same for any inertial reference frame (c = 3.00 x 108 m/s). This is
true no matter how fast a light source is moving relative to an
observer.
Time dilation
Time dilation refers to the fact that clocks moving at close to the
speed of light run slow. Consider two observers, each holding an
identical clock. These clocks work using pulses of light. An emitter
bounces light off a mirror, and the reflected pulse is picked up by a
detector next to the emitter. Every time a pulse is detected, a new
pulse is sent out. So, the clock measures time by counting the number
of pulses received; the interval between pulses is the time it takes
for a pulse to travel to the mirror and back.
If our two observers are stationary relative to each other, they
measure the same time. If they are moving at constant velocity relative
to each other, however, they measure different times. As an example,
let's say one observer stays on the Earth, and the other goes off in a
spaceship to a planet 9.5 light years away. If the spaceship travels at
a speed of 0.95 c (95% of the speed of light), the observer on Earth
measures a time of 10 years for the trip.
The person on the spaceship, however, measures a much shorter time for
the trip. In fact, the time they measure is known as the proper time.
The time interval being measured is the time between two events; first,
when the spaceship leaves Earth, and second, when the spaceship arrives
at the planet. The observer on the spaceship is present at both
locations, so they measure the proper time. All observers moving
relative to this observer measure a longer time, given by:
In this case we can use this equation to get the proper time, the time measured for the trip by the observer on the spaceship:
So, during the trip the observer on Earth ages 10 years. Anyone on the spaceship only ages 3.122 years.
It is very easy to get confused about who's measuring the proper time.
Generally, it's the observer who's present at both the start and end
who measures the proper time, and in this case that's the person on the
spaceship.
Length contraction
Carrying on with our example of the spaceship traveling to a
distant planet, let's think about what it means for measuring distance.
The one thing that might puzzle you is this: everything is relative, so
a person on the Earth sees the clock on the spaceship running slow.
Similarly, the person on the Earth is moving at 0.95c relative to the
observer on the spaceship, so the observer on the ship sees their own
clock behaving perfectly and the clock on the Earth moving slow. So, if
the clock on the spaceship is measuring time properly according to an
observer moving with the clock, how can we account for the fact that
the observer on the ship seems to cover a distance of 9.5 light years
in 3.122 years, which would imply that they're traveling at a speed of
3.04c?
That absolutely can not be true. For one thing, one of the implications
of relativity is that nothing can travel faster than c, the speed of
light in vacuum. c is the ultimate speed limit in the universe. For
another, two observers will always agree on their relative velocities.
If the person on the Earth sees the spaceship moving at 0.95c, the
observer on the spaceship agrees that the Earth is moving at 0.95c with
respect to the spaceship (and because the other planet is not moving
relative to the Earth), everyone's in agreement that the relative
velocity between the spaceship and planet is 0.95c.
So, distance is velocity multiplied by time and we know the velocity
and time measured by the observer on the spacecraft is 0.95c and 3.122
years. This implies that they measure a distance for the trip of 2.97
light-years, much smaller than the 9.5 light-year distance measured by
the observer on the Earth.
This is in fact exactly what happens; a person who is moving measures a
contracted length. In this case, the person on the Earth measures the
proper length, because they are not moving relative to the far-off
planet. The observer on the spaceship, however, is moving relative to
the Earth-planet reference frame, so they measure a shorter distance
for the distance from the Earth to the planet. The length measured by
the moving observer is related to the proper length by the equation:
In this case we can solve for the length measured by the observer on the spaceship:
This agrees with what we calculated above, as it should.
One important thing to note about length contraction: the contraction
is only measured along the direction parallel to the motion of the
observer. No contraction is seen in directions perpendicular to the
motion.
Relative velocities
At the start of PY105 we talked about relative velocities. Let's
say you're standing on an interstate freeway that runs north and south.
You see a truck heading north at 60 km/h, and a car heading south at 70
km/h. All three of you (you, the car driver, and the truck driver)
agree on these points:
* the truck is traveling at 60 km/h north relative to you, and 130 km/h north relative to the car.
* the car is traveling at 70 km/h south relative to you, and 130 km/h south relative to the truck.
* you are traveling at 60 km/h south relative to the truck, and 70 km/h north relative to the car.
Two observers always agree on their relative velocity. The simple
addition we used to get the velocity of the truck relative to the car
can not be applied to a relativistic situation, however.
Let's say you now stand on an intergalactic freeway. You see a truck
heading in one direction at 0.6c, and a car heading in the opposite
direction at 0.7c. What is the velocity of the truck relative to the
car? It is not 1.3c, because nothing can travel faster than c. The
relative velocity can be found using this equation:
In this case, u is the velocity of the car relative to you, v is the
velocity of the truck relative to you, and u' is the velocity of the
car relative to the truck. Taking the direction the car is traveling to
be the positive direction:
So, now everyone involved agrees on this:
* the truck is traveling at 0.6c relative to you, and 0.915c relative to the car.
* the car is traveling at 0.7c relative to you, and 0.915c relative to the truck.
* you are traveling at 0.6c relative to the truck, and 0.7c relative to the car.
The relativistic equation for velocity addition shown above can also be
used for non-relativistic velocities. We're more used to adding
velocities like this : u' = u - v. This is exactly what the
relativistic equation reduces to for velocities much less than the
speed of light. The relativistic equation applies to any situation; the
one we're used to is a special case that applies only for small
velocities.
Subject:
Subject X2:
The Bohr Model of the Atom
Understanding the atom
8-9-99
Rutherford scattering
Let's focus on the atom, starting from a historical perspective. Ernest Rutherford did a wonderful experiment in which he fired alpha particles (basically helium nuclei) at a very thin gold foil. He got a rather surprising result: rather than all the particle passing straight through the foil, many were scattered off at large angles, some even coming straight back. This was inconsistent with the plum-pudding model of the atom, in which the atom was viewed as tiny electrons embedded in a dispersed pudding of positive charge. Rutherford proposed that the positive charge must really be localized, concentrated in a small nucleus.
This led to the planetary model of the atom, with electrons orbiting the nucleus like planets orbiting the Sun.
Line spectra
If the atom looked like a solar system, how could line spectra be explained? Line spectra are what you get when you excite gases with a high voltage. Gases emit light at only a few sharply-defined frequencies, and the frequencies are different for different gases. These emission spectra, then, are made up of a few well-defined lines.
Gases will also selectively absorb light at these same frequencies. You can see this if you expose a gas to a continuous spectrum of light. The absorption spectra will be very similar to a continuous spectrum, except for a few dark lines corresponding to the frequencies absorbed by the gas.
The Bohr model
The Bohr model is a planetary model of the atom that explains things like line spectra. Neils Bohr proposed that the electrons orbiting the atom could only occupy certain orbits, orbits in which the angular momentum satisfied a particular equation:
where m is the mass of the electron, r is the radius of the orbit, and v is the orbital speed of the electron.
In other words, Bohr was proposing that the angular momentum of an electron in an atom is quantized.
What does quantization of the angular momentum mean for the
energy of the electron in a particular orbit? We can analyze the energy
very simply using concepts of circular motion and the potential energy
associated with two charges. The electron has a charge of -e, while the
nucleus has a charge of +Ze, where Z is the atomic number of the
element. The energy is then given by:
The electron is experiencing uniform circular motion, with the only
force on it being the attractive force between the negative electron
and the positive nucleus. Thus:
Plugging this back into the energy equation gives:
If you rearrange the angular momentum equation to solve for the velocity, and then plug that back into the equation:
and solve that for r, you get:
This can now be substituted into the energy equation, giving the total energy of the nth level:
Energy level diagrams and the hydrogen atom
It's often helpful to draw a diagram showing the energy levels for the particular element you're interested in. The diagram for hydrogen is shown on page 918 in the text. Hydrogen's easy to deal with because there's only one electron to worry about.
The n = 1 state is known as the ground state, while higher n states are known as excited states. If the electron in the atom makes a transition from a particular state to a lower state, it is losing energy. To conserve energy, a photon with an energy equal to the energy difference between the states will be emitted by the atom. In the hydrogen atom, with Z = 1, the energy of the emitted photon can be found using:
Atoms can also absorb photons. If a photon with an energy equal to the energy difference between two levels is incident on an atom, the photon can be absorbed, raising the electron up to the higher level.
Angular momentum
Bohr's model of the atom was based on the idea the angular momentum is quantized, and quantized in a particular way. de Broglie came up with an explanation for why the angular momentum might be quantized in this way. de Broglie realized that if you use the wavelength associated with the electron, and only allow for standing waves to exist in any orbit (in other words, the circumference of the orbit has to be an integral number of wavelengths), then you arrive at the same relationship for the angular momentum that Bohr got.
The derivation works like this, starting from the idea that the circumference of the circular orbit must be an integral number of wavelengths:
Taking the wavelength to be the de Broglie wavelength, this becomes:
The momentum, p, is simply mv as long as we're talking about non-relativistic speeds, so this becomes:
Rearranging this a little, and recognizing that the angular momentum
for a point mass is simply L = mvr, gives the Bohr relationship:
Subject:
Subject X2:
The Periodic Table
The quantum mechanical view of the atom
8-10-99
Heisenberg uncertainty principle
The uncertainty principle is a rather interesting idea, stating that it is not possible to measure both the position and momentum of a particle with infinite precision. It also states that the more accurately you measure a particle's position, the less accurately you're able to measure it's momentum, and vice versa.
This idea is really not relevant when you're making measurements of large objects. It is relevant, however, when you're looking at very small objects such as electrons. Consider that you're trying to measure the position of an electron. To do so, you bounce photons off the electron; by figuring out the time it takes for each photon to come back to you, you can figure out where the electron is. The more photons you use, the more precisely you can measure the electron's position.
However, each time a photon bounces off the electron, momentum is transferred to the electron. The more photons you use, the more momentum is transferred, and because you can't measure that momentum transferred to infinite precision the more uncertainty you're introducing in the measurement of the momentum of the electron.
Heisenberg showed that there is a limit to the accuracy you can measure things:
The uncertainty can also be stated in terms of the energy of a particle
in a particular state, and the time in which the particle is in that
state:
Quantum numbers
The Bohr model of the atom involves a single quantum number, the integer n that appears in the expression for the energy of an electron in an orbit. This picture of electrons orbiting a nucleus in well-defined orbits, the way planets orbit the Sun, is not our modern view of the atom. We now picture the nucleus surrounded by electron clouds, so the orbitals are not at all well-defined; we still find the Bohr theory to be useful, however, because it gives the right answer for the energy of the electron orbitals.
The Bohr model uses one quantum number, but a full quantum mechanical treatment requires four quantum numbers to characterize the electron orbitals. These are known as the principal quantum number, the orbital quantum number, the magnetic quantum number, and the spin quantum number. These are all associated with particular physical properties.
n, the principal quantum number, is associated with the total energy, the same way it is in the Bohr model. In fact, calculating the energy from the quantum mechanical wave function gives the expression Bohr derived for the energy:
, the orbital quantum number, is connected to the total angular
momentum of the electron. This quantum number is an integer less than
n, and the total angular momentum of the electron can be calculated
using:
, the magnetic quantum number, is related to one particular component
of the angular momentum. By convention, we call this the z-component.
The energy of any orbital depends on the magnetic quantum number only
when the atom is in an external magnetic field. This quantum number is
also an integer; it can be positive or negative, but it has a magnitude
less than or equal to the orbital quantum number. The z-component of
the electron's angular momentum is given by:
, the spin quantum number is related to something called the spin
angular momentum of the electron. The closest analogy is that it's
similar to the Earth spinning on its axis. There are only two possible
states for this quantum number, often referred to as spin up and spin
down.
What's the use of having all these quantum numbers? We need all four to completely describe the state an electron occupies in the atom.
Electron probability density clouds
A very important difference between the Bohr model and the full quantum mechanical treatment of the atom is that Bohr proposed that the electrons were found in very well-defined circular orbits around the nucleus, while the quantum mechanical picture of the atom has the electron essentially spread out into a cloud. We call this a probability density cloud, because the density of the cloud tells us what the probability is of finding the electron at a particular distance from the nucleus.
In quantum mechanics, something called a wave function is associated with each electron state in an atom. The probability of finding an electron at a particular distance from the nucleus is related to the square of the wave function, so these electron probability density clouds are basically three-dimensional pictures of the square of the wave function.
The Pauli exclusion principle
If you've got a hydrogen atom, with only a single electron, it's very easy to determine the possible states that electron can occupy. A particular state means one particular combination of the 4 quantum numbers; there are an infinite number of states available, but the electron is more likely to occupy a low-energy state (i.e., a low n state) than a higher-energy (higher n) state.
What happens for other elements, when there is more than one electron to worry about? Can all the electrons be found in one state, the ground state, for example? It turns out that this is forbidden: the Pauli exclusion principle states that no two electrons can occupy the same state. In other words, no two electrons can have the same set of 4 quantum numbers.
Shells and subshells
As usual, for historical reasons we have more than one way to characterize an electron state in an atom. We can do it using the 4 quantum numbers, or we can use the notion of shells and subshells. A shell consists of all those states with the same value of n, the principal quantum number. A subshell groups all the states within one shell with the same value of , the orbital quantum number.
The subshells are usually referred to by letters, rather than by
the corresponding value of the orbital quantum number. The letters s,
p, d, f, g, and h stand for values of 0, 1, 2, 3, 4, and 5,
respectively. Using these letters allows us to use a shorthand to
denote how many electrons are in a subshell; this is useful for
specifying the ground state (lowest energy state) of a particular atom.
The ground state configuration for oxygen, for instance, can be written as :
This means that the lowest energy configuration of oxygen, with 8
electrons, is to have two electrons in the n=1 s-subshell, two in the
n=2 s-subshell, and four in the n=2 p-subshell.
Potassium (Z = 19) has an interesting ground state configuration:
That's interesting because there is a d-subshell in the n = 3 shell,
but instead of the last electron going into that subshell it goes into
the s-subshell of the n=4 shell. It does this to minimize the energy:
the 4s subshell is at a lower energy than the 3d subshell.
The periodic table
When Mendeleev organized the elements into the periodic table, he
knew nothing about quantum numbers and subshells. The way the elements
are organized in the periodic table, however, is directly related to
how the electrons fill the levels in the different shells.
Different columns of the periodic table group elements with
similar properties; they have similar properties because of the
similarities between their ground state electron configurations. The
noble gases (He, Ne, Ar, etc.) are all in the right-most column of the
periodic table. Their ground state configurations have no partially
filled subshells; having a complete subshell is favorable from the
standpoint of minimizing energy so these elements do not react readily.
On the other hand, the column next to the noble gases is the
halogens; these are one electron short of having completely-filled
subshells, so if they can share an electron from another element
they're happy to do so. They react readily with elements whose ground
state configurations have a single electron in one subshell like the
alkali metals (Li, Na, K, etc.).
WebElements is a nice web-based periodic table, having all
sorts of useful information about different elements. Click on the icon
below to check it out.
Subject:
Subject X2:
The Quantum World
Electrons, photons, and the photo-electric effect
8-6-99
We're now starting to talk about quantum mechanics, the physics of the very small.
Planck's constant
At the end of the 19th century one of the most intriguing puzzles in
physics involved the spectrum of radiation emitted by a hot object.
Specifically, the emitter was assumed to be a blackbody, a perfect
radiator. The hotter a blackbody is, the more the peak in the spectrum
of emitted radiation shifts to shorter wavelength. Nobody could explain
why there was a peak in the distribution at all, however; the theory at
the time predicted that for a blackbody, the intensity of radiation
just kept increasing as the wavelength decreased. This was known as the
ultraviolet catastrophe, because the theory predicted that an infinite
amount of energy was emitted by a radiating object.
Clearly, this prediction was in conflict with the idea of
conservation of energy, not to mention being in serious disagreement
with experimental observation. No one could account for the
discrepancy, however, until Max Planck came up with the idea that a
blackbody was made up of a whole bunch of oscillating atoms, and that
the energy of each oscillating atom was quantized. That last point is
the key : the energy of the atoms could only take on discrete values,
and these values depended on the frequency of the oscillation:
Planck's prediction of the energy of an oscillating atom : E = nhf (n = 0, 1, 2, 3 ...)
where f is the frequency, n is an integer, and h is a constant
known as Planck's constant. This constant shows up in many different
areas of quantum mechanics.
The spectra predicted for a radiating blackbody made up of these oscillating atoms agrees very well with experimentally-determined spectra.
Planck's idea of discrete energy levels led Einstein to the idea that electromagnetic waves have a particle nature. When Planck's oscillating atoms lose energy, they can do so only by making a jump down to a lower energy level. The energy lost by the atoms is given off as an electromagnetic wave. Because the energy levels of the oscillating atoms are separated by hf, the energy carried off by the electromagnetic wave must be hf.
The photoelectric effect
Einstein won the Nobel Prize for Physics not for his work on relativity, but for explaining the photoelectric effect. He proposed that light is made up of packets of energy called photons. Photons have no mass, but they have momentum and they have an energy given by:
Energy of a photon : E = hf
The photoelectric effect works like this. If you shine light of high enough energy on to a metal, electrons will be emitted from the metal. Light below a certain threshold frequency, no matter how intense, will not cause any electrons to be emitted. Light above the threshold frequency, even if it's not very intense, will always cause electrons to be emitted.
The explanation for the photoelectric effect goes like this: it takes a certain energy to eject an electron from a metal surface. This energy is known as the work function (W), which depends on the metal. Electrons can gain energy by interacting with photons. If a photon has an energy at least as big as the work function, the photon energy can be transferred to the electron and the electron will have enough energy to escape from the metal. A photon with an energy less than the work function will never be able to eject electrons.
Before Einstein's explanation, the photoelectric effect was a real mystery. Scientists couldn't really understand why low-frequency high-intensity light would not cause electrons to be emitted, while higher-frequency low-intensity light would. Knowing that light is made up of photons, it's easy to explain now. It's not the total amount of energy (i.e., the intensity) that's important, but the energy per photon.
When light of frequency f is incident on a metal surface that has a work function W, the maximum kinetic energy of the emitted electrons is given by:
Note that this is the maximum possible kinetic energy because W is the
minimum energy necessary to liberate an electron. The threshold
frequency, the minimum frequency the photons can have to produce the
emission of electrons, is when the photon energy is just equal to the
work function:
The Compton effect
Although photons have no mass, they do have momentum, given by:
Convincing evidence for the fact that photons have momentum can be seen
when a photon collides with a stationary electron. Some of the energy
and momentum is transferred to the electron (this is known as the
Compton effect), but both energy and momentum are conserved in such a
collision. Applying the principles of conservation of energy and
momentum to this collision, one can show that the wavelength of the
outgoing photon is related to the wavelength of the incident photon by
the equation:
Wave-particle duality
To explain some aspects of light behavior, such as interference and diffraction, you treat it as a wave, and to explain other aspects you treat light as being made up of particles. Light exhibits wave-particle duality, because it exhibits properties of both waves and particles.
Wave-particle duality is not confined to light, however. Everything exhibits wave-particle duality, everything from electrons to baseballs. The behavior of relatively large objects, like baseballs, is dominated by their particle nature; to explain the behavior of very small things like electrons, both the wave properties and particle properties have to be considered. Electrons, for example, exhibit the same kind of interference pattern as light does when they're incident on a double slit.
The de Broglie wavelength
In 1923, Louis de Broglie predicted that since light exhibited both wave and particle behavior, particles should also. He proposed that all particles have a wavelength given by:
Note that this is the same equation that applies to photons.
de Broglie's prediction was shown to be true when beams of electrons and neutrons were directed at crystals and diffraction patterns were seen. This is evidence of the wave properties of these particles.
Everything has a wavelength, but the wave properties of matter are only observable for very small objects. If you work out the wavelength of a moving baseball, for instance, you will find that the wavelength is far too small to be observable.
What is a particle wave?
The probability of finding a particle at a particular location, then, is related to the wave associated with the particle. The larger the amplitude of the wave at a particular point, the larger the probability that the electron will be found there. Similarly, the smaller the amplitude the smaller the probability. In fact, the probability is proportional to the square of the amplitude of the wave.
Quantum mechanics
All these ideas, that for very small particles both particle and wave properties are important, and that particle energies are quantized, only taking on discrete values, are the cornerstones of quantum mechanics. In quantum mechanics we often talk about the wave function of a particle; the wave function is the wave discussed above, with the
probability of finding the particle in a particular location being
proportional to the square of the amplitude of the wave function.
Subject:
Subject X2:
Motion in One and Two Dimensions
Subject:
Subject X2:
Constant Acceleration
9-10-99
Sections 2.6 - 2.7
Applying the equations
Doing a sample problem is probably the best way to see how you would use the kinematics equations. Let's say you're driving in your car, approaching a red light on Commonwealth Avenue. A black Porsche is stopped at the light in the right lane, but there's no-one in the left lane, so you pull into the left lane. You're traveling at 40 km/hr, and when you're 15 meters from the stop line the light turns green. You sail through the green light at a constant speed of 40 km/hr and pass the Porsche, which accelerated from rest at a constant rate of 3 m/s2 starting at the moment the light turned green.
(a) How far from the stop line do you pass the Porsche?
(b) When does the Porsche pass you?
(c) If a Boston police officer happens to get you and the Porsche on the radar gun at the instant the Porsche passes you, will either of you be pulled over for speeding? Assume the speed limit is 50 km/hr.
Step 1 - Write down everything you know. Define an origin - the stop line is a good choice in this problem. Then choose a positive direction. In this case, let's take the positive direction to be the direction you're traveling. Decide on a system of units...meters and seconds is a good choice here, so convert your speed to m/s from km/hr. Drawing a diagram is also a good idea.
Origin = stop line
Positive direction = the direction you're traveling
Step 2 - Figure out what you need to solve for. At the instant you pass the Porsche, the x values (yours and the Porsche's) have to be equal. You're both the same distance from the stop line, in other words. Write out the expression for your x-value and the Porsche's. We'll use the equation:
For you : x = -15 + 11.11 t + 0
For the Porsche : x = 0 + 0 + 1/2 (3) t2 = 1.5 t2
At some time t, when you pass the Porsche, these x values will be the same. So, we can set the equations equal to one another and solve for time, and then plug the time back in to either x equation to get the distance from the stop line. Doing this gives:
-15 + 11.11 t = 1.5 t2
Bringing everything to one side gives:
1.5 t2 - 11.11 t + 15 = 0
This is a quadratic equation, which we can solve using the quadratic formula:
where a = 1.5, b = -11.11, and c = 15
This gives two values for t, t = 1.776 s and t = 5.631 s.
What do these two values mean? In many cases only one answer will be relevant, and you'll have to figure out which. In this case both are relevant. The smaller value is when you pass the Porsche, while the larger one is when the Porsche passes you back.
To get the answer to question (a), plug t = 1.776 into either of your x expressions. They should both give you the same value for x, so you can use one as a check.
For you, at t = 1.776, x = 4.73 m.
For the Porsche, at t = 1.776 s, x = 4.73 m.
We've actually already calculated the answer to (b), when the Porsche passes you, which is at t = 5.6 s.
To get the answer to part (c), we already know that you're traveling at a constant speed of 40 km/hr, which is under the speed limit. To figure out how fast the Porsche is going at t = 5.631 seconds, use:
v = vo + a t = 0 + (3) (5.631) = 16.893 m/s.
Converting this to km/hr gives a speed of 60.8 km/hr, so the driver of the Porsche is in danger of getting a speeding ticket.
Free fall
Objects falling straight down under the influence of gravity are excellent examples of objects traveling at constant acceleration in one dimension. This also applies to anything you throw straight up in the air which, because of the constant acceleration downwards, will rise until the velocity drops to zero and then will fall back down again.
The acceleration experienced by a dropped or thrown object while it is in flight comes from the gravitational force exerted on the object by the Earth. If we're dealing with objects at the Earth's surface, which we usually are, we call this acceleration g, which has a value of 9.8 m/s2. This value is determined by three things: the mass of the Earth, the radius of the Earth, and a number called the universal gravitational constant. We'll be dealing with all that later in the semester, though, so don't worry about it yet. For now, all you need to remember is that g is 9.8 m/s2 at the surface of the Earth, directed down.
A typical one-dimensional free fall question (free fall meaning that the only acceleration we have to worry about is g) might go like this.
You throw a ball straight up. It leaves your hand at 12.0 m/s.
(a) How high does it go?
(b) If, when the ball is on the way down, you catch it at the same height at which you let it go, how long was it in flight?
(c) How fast is it traveling when you catch it?
Origin = height at which it leaves your hand
Positive direction = up
(a) At the very top of its flight, the ball has an instantaneous velocity of zero. We can plug v = 0 into the equation:
This gives:
0 = 144 + 2 (-9.8) x
Solving for x gives x = 7.35 m, so the ball goes 7.35 m high.
(b) To analyze the rest of the problem, it's helpful to remember that the down half of the trip is a mirror image of the up half. In other words, if, while going up, the ball passes through a particular height at a particular velocity (2 m/s up, for example), on its way down it will pass through that height at the same speed, with its velocity directed down rather than up. This means that the up half of the trip takes the same time as the down half of the trip, so we could just figure out how long it takes to reach its maximum height, and then double that to get the total time.
Another way to do it is simply to plug x = 0 into the equation:
This gives 0 = 0 + 12 t - 4.9 t2
A factor of t can be canceled out of both terms, leaving:
0 = 12 - 4.9 t, which gives a time of t = 12 / 4.9 = 2.45 s.
(c) The answer for part (c) has to be 12 m/s down, because of the mirror-image relationship between the up half of the flight and the down half. We could also figure it out using the equation:
v = vo + a t
which gives:
v = 12 - 9.8 (2.45) = -12 m/s.
Subject:
Subject X2:
Graphical analysis and Vectors
9-13-99 Sections 2.8 - 3.4 Graphs Drawing good pictures can be the secret to solving physics problems. It's amazing how much information you can get from a diagram. We also usually need equations to find numerical solutions. Graphs are basically pictures of equations. Learning how to interpret these pictures can really help you understand physics. Let's return to our last example, a ball thrown vertically upward with an initial speed of 12 m/s. The only acceleration we have to worry about is the acceleration due to gravity, 9.8 m/s2 down. This acceleration is constant, so it's easy to plot on a graph.
If the time T represents the time when the ball returns to your hand, the area under the curve must equal -24.0 m/s, because we know the velocity changes from 12.0 m/s to -12.0 m/s. This allows us to solve for T, using:
T = -24.0 / -9.8 = 2.45 s, agreeing with what we calculated previously.
What about the velocity graph? The equation for velocity is:
v = vo + at
Plugging in the initial velocity and acceleration here gives v = 12.0 -9.8t
The velocity graph can give all sorts of information:
* The slope of the velocity graph is the acceleration, while the area under the curve is the displacement.
* For this example of a ball going up and then back down, the graph confirms that the time taken on the way up equals the time taken on the way down.
* Calculating the area under the curve for the ball on the way up (the positive area on the graph) gives the maximum displacement. The area is just a triangle, with a a base T/2 = 1.2245 s and height of 12 m/s. This gives an area of 0.5(1.2245)(12) = 7.35 m. Again, this agrees with the maximum height calculated previously.
* The positive and negative areas cancel each other out, meaning the net displacement is zero. This is correct, as the ball returns to its starting point.
The graph of position as a function of time is a plot of the equation:
x = xo + vot + 1/2 at2
In this case, that's x = 0 + 12t -4.9t2
The slope of the position graph gives the instantaneous velocity. This is positive but steadily decreasing on the way up, zero at the very top, and then becomes more and more negative on the way down.
Vectors and scalars
We'll move on from looking at motion in one dimension to motion in two or three dimensions. It's critical now to distinguish between two kinds of quantities, scalars and vectors. A scalar is something that's just a number with a unit, like mass ( 200 g ) or temperature ( -30°C). A vector has both a number and a direction, like velocity. If you came to campus on the T today, at some point you may have been traveling 20 km/hr east. Velocity is a combination of a scalar (speed, 20 km/hr) and a direction (east).
Examples of scalars : mass, temperature, speed, distance
Examples of vectors : displacement, velocity, acceleration, force
One crucial difference between scalars and vectors involves the use of plus and minus signs. A scalar with a negative sign means something very different from a scalar with a plus sign; +30°C feels an awful lot different than -30°C, for example. With a vector the sign simply tells you the direction of the vector. If you're traveling with a velocity of 20 km/hr east, it means you're traveling east, and your speed is 20 km/hr. A velocity of -20 km/hr east also means that you're traveling at a speed of 20 km/hr, but in the direction opposite to east : 20 km/hr west, in other words. With a vector, the negative sign can always be incorporated into the direction.
Note that a vector will normally be written in bold, like this : A. A scalar, like the magnitude of the vector, will not be in bold face (e.g., A).
Components of a vector
A vector pointing in a random direction in the x-y plane has x and y components: it can be split into two vectors, one entirely in the x-direction (the x-component) and one entirely in the y-direction (the y-component). Added together, the two components give the original vector.
The easiest way to add or subtract vectors, which is often required in physics, is to add or subtract components. Splitting a vector into its components involves nothing more complicated than the trigonometry associated with a right-angled triangle.
Consider the following example. A vector, which we will call A, has a length of 5.00 cm and points at an angle of 25.0° above the negative x-axis, as shown in the diagram. The x and y components of A, Ax and Ay are found by drawing right-angled triangles, as shown. Only one right-angled triangle is actually necessary; the two shown in the diagram are identical.
Knowing the length of A, and the angle of 25.0°, Ax and Ay can be found by re-arranging the expressions for sin and cos.
Note that this analysis, using trigonometry, produces just the magnitudes of the vectors Ax and Ay. The directions can be found by looking on the diagram. Usually, positive x is to the right of the origin; Ax points left, so it is negative:
Ax = -4.53 cm in the x-direction (or, 4.53 cm in the negative x-direction)
Positive y is generally up; Ay is directed up, so it is positive:
Ay = 2.11 cm in the y-direction
Adding vectors
It's fairly easy to add vectors that are parallel to each other, or at right angles. In general, however, the angle between vectors being added (or subtracted) will be something other than 0, 90, or 180°. Consider the following example, where the vector C equals A + B.
A has a length of 5.00 cm and points at an angle of 25.0° above the negative x-axis. B has a length of 7.00 cm and points at an angle of 40.0° above the positive x-axis. If C = A + B, what is the magnitude and direction of C? There are basically two ways to answer this. One way is to draw a vector diagram, moving the tail of B to the head of A, or vice versa. The vector C will then extend from the origin to wherever the tip of the second vector is.
The second way to find the magnitude and direction of C we'll use a lot in this course, because we'll often have vector equations of the form C =A + B. The simplest way to solve any vector equation is to split it up into one-dimensional equations, one equation for each dimension of the vector. In this case we're working in two dimensions, so the one vector equation can be replaced by two equations:
In the x-direction : Cx = Ax + Bx
In the y-direction : Cy = Ay + By
In other words, to find the magnitude and direction of C, the vectors A and B are split into components. The components are:
Ax = -4.532 cm in the x-direction
Ay = 2.113 cm in the y-direction
Bx = 7.00 cos40 = 5.362 cm
By = 7.00 sin40 = 4.500 cm
Bx = 5.362 cm in the x-direction
By = 4.500 cm in the y-direction
The components of C are found by adding the components of A and B:
Cx = Ax + Bx = (-4.532 + 5.362) cm in the x-direction = 0.83 cm in the x-direction
Cy = Ay + By= (2.113 + 4.500) cm in the y-direction = 6.61 cm in the y-direction
The magnitude of C can be found from its components using the Pythagorean theorem:
The direction of C can be found by taking the inverse tangent of Cy/Cx:
inverse tan of 6.613 / 0.830 = 82.8°.
Combined, this gives C = 6.66 cm at an angle of 82.8° above the positive x-axis.
Note how the calculations and the diagrams go hand-in-hand. This will often be the case; it is always a good idea to draw diagrams as you go along.
Note also that we could have used the cosine law to get the length of C, and then applied the sine law, with a bit of geometry, to get the angle. It's worth trying that for yourself, just to convince yourself that the numbers come out the same.
Subject:
Subject X2:
Introduction
9-3-99
Sections 1.1 - 1.8 and Appendix A
If you were taking a trip to Greece, you'd get the most out of your
trip if you learned some Greek before going. Knowing a little of the
language would help you somewhat; being fluent in the language would
help you immensely. The same holds true for physics.This introduction
to physics is simply a review of the language of physics. If you're
unfamiliar with some of these concepts, spending the time to become
fluent will help you immensely in the course. Practice makes perfect!
MKS units and the metric system
MKS (meter-kilogram-second) units are part of the metric system, based
on powers of ten to keep things simple. The more common prefixes used
in the metric system, and the powers of ten associated with them, are
given in the table below. You should know all of these off by heart.
Unit analysis and conversion
You will often need to convert a value from one unit to another,
converting from centimeters to meters, for example. Be extra careful if
you have units which are squared, cubed, or have some other exponent.
If you have a cube which is 10 cm on each side, then the volume is
simply the length x the width x the height:
V = 10 cm x 10 cm x 10 cm = 1000 cm3.
In m3, the volume is
Consider a slightly more complicated example, with two steps rather
than one. When he set the 200-meter world record, 19.32 seconds,
Michael Johnson ran at an average speed of 200 m / 19.32 s = 10.35 m/s.
If you want to know how fast this is in miles/hour, the conversion
would be carried out like this:
10.35 m/s x (1 mile / 1609 m) x (3600 s / 1 hour) = 23.2 miles / hour.
All you do to convert is multiply the original value by x/y, where x
and y are the same thing, expressed in different units. Something else
to keep in mind is that when values are multiplied or divided, they can
have different units. When you add or subtract values, however, the
values must have the same units.
Significant figures
When you punch in 200/19.32 in your calculator, your calculator gives
you the number 10.35196687. You have to round this off (10.35 is a good
choice), because most of the figures the calculator gives you are not
significant, meaning, essentially, that they're meaningless. The
calculator assumes that what you type in is accurate to about 12
figures; typically, your numbers are accurate to 2 or 3 or 4 figures.
When you're combining numbers, the general rule of thumb is that you
should round off your answers to the same number of significant figures
as there are in the number with the smallest number of significant
figures.
Another general rule of thumb : if you have to calculate intermediate
values before you get to a final value, keep one or two extra
significant figures for the intermediate values, just so you won't
introduce any inaccuracies in the final answer by rounding off too soon.
Trigonometry
Basic trigonometry is usually introduced by looking at a right-angled
triangle. Let's use a triangle with sides of length 3 cm, 4 cm, and 5
cm. This satisfies the Pythagorean theorem, which states that for a
right-angled triangle with sides a and b, and with a hypotenuse c (the
side opposite the 90¡ angle), the square of the hypotenuse equals the
sum of the squares of the other two sides.
Let's say we'd like to figure out the angle between the 3 cm side and
the 5 cm side. We'll call this angle by the Greek letter theta. For a
right-angled triangle, we can use the following relationships:
where hyp stands for hypotenuse, opp stands for the side opposite to ,
and adj stands for the side adjacent to (the adjacent side that's not
the hypotenuse). Note that the units cancel out, so these values have
no units.
If we wanted to find the third angle in the triangle, we could use
trigonometry, or geometry, remembering that the three angles in a
triangle must add up to 180¡.
The Sine law and the Cosine law
The sine relationship used above for the right-angled triangle, as well
as the Pythagorean theorem, are simply special cases of the sine law
and the cosine law, respectively. Most triangles do not have 90¡ angles
in them, but there are still ways to relate sides and angles. In any
triangle the sine and cosine laws are as follows:
Be extra careful with the sine law. If the angle is greater than 90¡,
your calculator will give you 180 - the angle, because your calculator
gives you an angle less than 90¡. To find the angle, subtract what your
calculator gives you from 180¡.
Algebra
Algebra involves the manipulation of equations to solve for unknown
variables. PY105 involves a great deal of problem solving, requiring a
lot of reasonably straightforward algebra. An example will help
illustrate the sort of manipulations you'll be expected to carry out.
Let's say you have an equation that states:
and you're given a = -2.00 m/s2 and v = 2.00 m/s. You
don't know x, so you have to rearrange the equation to solve for x,
which means getting x by itself on the left side. Note that the
equation involves numbers, variables, and units...it would be easy to
confuse a unit with a variable, but usually it's fairly obvious what is
what. In this case, v, a, and x are variables, while m and s are units
(meters and seconds).
First of all, let's analyze the units. The left hand side has units of m2/s2,
and the first term on the right does also. For the equation to make
sense, the second term on the right must have the same units, which
means x must have units of m. x is a length, in other words.
You don't have to do this in one step, but you should be able to re-arrange the equation above to solve for x:
Getting a feel for numbers
Just one word of caution about relying too much on your calculator.
Just because your calculator gives you an answer doesn't mean it's the
correct answer. Think about whether your answer makes sense. Is it
about the right size, or is it much too large or too small? Does the
answer have the right sign? Does the answer make physical sense? It's
always a good idea to do a "back-of-the-envelope" calculation to come
up with an approximate value for the answer. Round your numbers off to
easily-calculated values, work out a rough answer on paper or in your
head, and then plug the exact values into your calculator to get the
answer, making sure the answer is in the same ballpark as your rough
answer.
Subject:
Subject X2:
Motion in one dimension
9-8-99
Sections 2.1 - 2.5
Motion in 1 dimension
We live in a 3-dimensional world, so why bother analyzing 1-dimensional situations? Basically, because any translational (straight-line, as opposed to rotational) motion problem can be separated into one or more 1-dimensional problems. Problems are often analyzed this way in physics; a complex problem can often be reduced to a series of simpler problems.
The first step in solving a problem is to set up a coordinate system. This defines an origin (a starting point) as well as positive and negative directions. We'll also need to distinguish between scalars and vectors. A scalar is something that has only a magnitude, like area or temperature, while a vector has both a magnitude and a direction, like displacement or velocity.
In analyzing the motion of objects, there are four basic parameters to keep track of. These are time, displacement, velocity, and acceleration. Time is a scalar, while the other three are vectors. In 1 dimension, however, it's difficult to see the difference between a scalar and a vector! The difference will be more obvious in 2 dimensions.
Displacement
The displacement represents the distance traveled, but it is a vector, so it also gives the direction. If you start in a particular spot and then move north 5 meters from where you started, your displacement is 5 m north. If you then turn around and go back, with a displacement of 5 m south, you would have traveled a total distance of 10 m, but your net displacement is zero, because you're back where you started. Displacement is the difference between your final position (x) and your starting point (xo) :
Speed and velocity
Imagine that on your way to class one morning, you leave home on time, and you walk at 3 m/s east towards campus. After exactly one minute you realize that you've left your physics assignment at home, so you turn around and run, at 6 m/s, back to get it. You're running twice as fast as you walked, so it takes half as long (30 seconds) to get home again.
There are several ways to analyze those 90 seconds between the time you left home and the time you arrived back again. One number to calculate is your average speed, which is defined as the total distance covered divided by the time. If you walked for 60 seconds at 3 m/s, you covered 180 m. You covered the same distance on the way back, so you went 360 m in 90 seconds.
Average speed = distance / elapsed time = 360 / 90 = 4 m/s.
The average velocity, on the other hand, is given by:
Average velocity = displacement / elapsed time.
In this case, your average velocity for the round trip is zero, because you're back where you started so the displacement is zero
We usually think about speed and velocity in terms of their instantaneous values, which tell us how fast, and, for velocity, in what direction an object is traveling at a particular instant. The instantaneous velocity is defined as the rate of change of position with time, for a very small time interval. In a particular time interval delta t, if the displacement is , the velocity during that time interval is:
The instantaneous speed is simply the magnitude of the instantaneous velocity.
Acceleration
An object accelerates whenever its velocity changes. Going back to the example we used above, let's say instead of instantly breaking into a run the moment you turned around, you steadily increased your velocity from 3m/s west to 6 m/s west in a 10 second period. If your velocity increased at a constant rate, you experienced a constant acceleration of 0.3 m/s per second (or, 0.3 m/s2).
We can figure out the average velocity during this time. If the acceleration is constant, which it is in this case, then the average velocity is simply the average of the initial and final velocities. The average of 3 m/s west and 6 m/s west is 4.5 m/s west. This average velocity can then be used to calculate the distance you traveled during your acceleration period, which was 10 seconds long. The distance is simply the average velocity multiplied by the time interval, so 45 m.
Similar to the way the average velocity is related to the displacement, the average acceleration is related to the change in velocity: the average acceleration is the change in velocity over the time interval (in this case a change in velocity of 3 m/s in a time interval of 10 seconds). The instantaneous acceleration is given by:
As with the instantaneous velocity, the time interval is very small (unless the acceleration is constant, and then the time interval can be as big as we feel like making it).
On the way out, you traveled at a constant velocity, so your acceleration was zero. On the trip back your instantaneous acceleration was 0.3 m/s2 for the first 10 seconds, and then zero after that as you maintained your top speed. Just as you arrived back at your front door, your instantaneous acceleration would be negative, because your velocity drops from 6 m/s west to zero in a small time interval. If you took 2 seconds to come to a stop, your acceleration is -6 / 2 = -3 m/s2.
Kinematics equations when the acceleration is constant
When the acceleration of an object is constant, calculations of the distance traveled by an object, the velocity it's traveling at a particular time, and/or the time it takes to reach a particular velocity or go a particular distance, are simplified. There are four equations that can be used to relate the different variables, so that knowing some of the variables allows the others to be determined.
Note that the equations apply under these conditions:
1. the acceleration is constant
2. the motion is measured from t = 0
3. the equations are vector equations, but the variables are not normally written in bold letters. The fact that they are vectors comes in, however, with positive and negative signs.
The equations are:
The equations above are all derived in section 2.5.
Subject:
Subject X2:
Motion in two dimensions
9-15-99
Sections 3.5 - 3.7
Extending things from 1 dimension
In 1 dimension, we wrote down some general equations relating velocity to displacement, and relating acceleration to the change in velocity. We also wrote down the four equations that apply in the special case where the acceleration is constant. We're going to do the same thing in 2 dimensions, and the equations will look similar; this shouldn't be surprising because, as we will see, a two (or three) dimensional problem can always be broken down into two (or three) 1-dimensional problems.
When we're dealing with more than 1 dimension (and we'll focus on 2D, but we could use these same equations for 3D), the position is represented by the vector r. The velocity will still be represented by v and the acceleration by a. In general, the average velocity will be given by:
The instantaneous velocity is given by a similar formula, with the condition that a very small time interval is used to measure the displacement.
A similar formula gives the average acceleration:
Again, the instantaneous acceleration is found by measuring the change in velocity over a small time interval.
The constant acceleration equations
When the acceleration is constant, we can write out four equations relating the displacement, initial velocity, velocity, acceleration, and time for each dimension. Like the 1D equations, these apply under the following conditions:
1. the acceleration is constant
2. the motion is measured from t = 0
3. the equations are vector equations, but the variables are not normally written in bold letters. The fact that they are vectors comes in, however, with positive and negative signs.
If we focus on two dimensions, we get four equations for the x direction and four more for the y direction. The four x equations involve only the x-components, while the four y equations involve only the y-components.
One thing to notice is that the time, t, is the only thing that doesn't involve an x or a y. This is because everything else is a vector (or a component of a vector, if you'd rather look at it that way), but time is a scalar. Time is the one thing that can be used directly in both the x and y equations; everything else (displacement, velocity, and acceleration) has to be split into components.
This is important!
Something that probably can't be emphasized enough is that even though an object may travel in a two-dimensional path (often following a parabola, in the standard case of an object moving under the influence of gravity alone), the motion can always be reduced to two independent one-dimensional motions. The x motion takes place as if the y motion isn't happening, and the y motion takes place independent of whatever is happening in the x direction.
One good example of this is the case of two objects (e.g., baseballs) which are released at the same time. One is dropped so it falls straight down; the other is thrown horizontally. As long as they start at the same height, both objects will hit the ground at the same time, no matter how fast the second one is thrown.
What we're ignoring
We will generally neglect the effect of air resistance in most of the problems we do. In some cases that's just fine. In other cases it's not so fine. A feather and a brick dropped at the same time from the same height will not reach the ground at the same time, for example. This has nothing to do with the weight of the feather compared to the brick. It's simply air resistance; if we took away all the air and dropped the feather and brick, they would hit the ground at exactly the same time.
So, remember that we're often analyzing ideal cases, especially this early in the semester. In reality, things might be a little different because of factors we're neglecting at the moment.
An example
Probably the simplest way to see how to apply these constant acceleration equations is to work through a sample problem. Let's say you're on top of a cliff, which drops vertically 150 m to a flat valley below. You throw a ball off the cliff, launching it at 8.40 m/s at an angle of 20° above the horizontal.
(a) How long does it take to reach the ground?
(b) How far is it from the base of the cliff to the point of impact?
It's a good idea to be as systematic as possible when it comes to analyzing the situation. Here's an example of how to organize the information you're given. First, draw a diagram.
Then set up a table to keep track of everything you know. It's important to pick an origin, and to choose a coordinate system showing positive directions. In this case, the origin was chosen to be the base of the cliff, with +x being right and +y being up. You don't have to choose the origin or the positive directions this way. Pick others if you'd like, and stick with them (an origin at the top of the cliff, and/or positive y-direction down would be two possible changes).
Now that everything's neatly organized, think about what can be used to calculate what. You know plenty of y-information, so we can use that to find the time it takes to reach the ground. One way to do this (definitely not the only way) is to do it in two steps, first calculating the final velocity using the equation:
This gives vy2 = 2.8732 + 2 (-9.8) (-150) = 2948.3 m2 / s2 . Taking the square root gives: vy = +/- 54.30 m/s.
Remember that the square root can be positive or negative. In this case it's negative, because the y-component of the velocity will be directed down when the ball hits the ground.
Now we can use another equation to solve for time:
So, -54.30 = 2.873 - 9.8 t, which gives t = 5.834 seconds. Rounding off, the ball was in the air for 5.83 s.
We can use this time for part (b), to get the distance traveled in the x-direction during the course of its flight. The best equation to use is:
So, from the base of the cliff to the point of impact is 46.0 m.
A point about symmetry
At some point in its flight, the ball in the example above returned to the level of the top of the cliff (you threw it from the top of the cliff, it went up, and on its way down it passed through a point the same height off the ground as the top of the cliff). What was the ball's velocity when it passed this height? Its speed will be the same as the initial speed, 8.40 m/s, and its angle will be the same as the launch angle, only measured below the horizontal.
This is not just true of the initial height. At every height the ball passes through on the way up, there is a mirror-image point (at the same height, with the same speed, and the same angle, just down rather than up) on the downward part of the path.
Subject:
Subject X2:
Relative velocity
Relative velocity in 1 dimension
Most people find relative velocity to be a relatively difficult concept. In one dimension, however, it's reasonably straight-forward. Let's say you're walking along a road, heading west at 8 km/hr. A train track runs parallel to the road and a train is passing by, traveling at 40 km/hr west. There is also a car driving by on the road, going 30 km/hr east. How fast is the train traveling relative to you? How fast is the car traveling relative to you? And how fast is the train traveling relative to the car?
One way to look at it is this: in an hour, the train will be 40 km west of where you are now, but you will be 8 km west, so the train will be 32 km further west than you in an hour. Relative to you, then, the train has a velocity of 32 km/hr west. Similarly, relative to the train, you have a velocity of 32 km/hr east.
Using a subscript y for you, t for the train, and g for the ground, we can say this: the velocity of you relative to the ground = ![]() = 8 km/hr west the velocity of the train relative to the ground =
= 8 km/hr west the velocity of the train relative to the ground = ![]() = 40 km/hr west
= 40 km/hr west
Note that if you flip the order of the subscripts, to get the velocity of the ground relative to you, for example, you get an equal and opposite vector. You can write this equal and opposite vector by flipping the sign, or by reversing the direction, like this: the velocity of the ground relative to you =![]() = -8 km/hr west = 8 km/hr east
= -8 km/hr west = 8 km/hr east
The velocity of the train relative to you, ![]() , can be found by adding vectors appropriately. Note the order of the subscripts in this equation:
, can be found by adding vectors appropriately. Note the order of the subscripts in this equation:
![]()
Rearranging this gives:
![]()
A similar argument can be used to show that the velocity of the car relative to you is 38 km/hr east. the velocity of you relative to the ground = ![]() = 8 km/hr west = -8 km/hr east the velocity of the car relative to the ground =
= 8 km/hr west = -8 km/hr east the velocity of the car relative to the ground = ![]() = 30 km/hr east
= 30 km/hr east
![]()
The velocity of the train relative to the car is 70 km/hr west, and the velocity of the car relative to the train is 70 km/hr east.
Relative velocity in 2 dimensions
In two dimensions, the relative velocity equations look identical to the way they look in one dimension. The main difference is that it's harder to add and subtract the vectors, because you have to use components. Let's change the 1D example to 2D. The train still moves at 40 km/hr west, but the car turns on to a road going 40° south of east, and travels at 30 km/hr. What is the velocity of the car relative to the train now?
The relative velocity equation for this situation looks like this:
![]()
The corresponding vector diagram looks like this:

Because this is a 2-D situation, we have to write this as two separate equations, one for the x-components (east-west) and one for the y-components (north-south):
![]()
Now we have to figure out what the x and y components are for these vectors. The train doesn't have a y-component, because it is traveling west. So:
![]()
The car has both an x and y component:
![]()
Plugging these in to the x and y equations gives:
![]()
Combining these two components into the vector gives a magnitude of:
![]()
at an angle given by the inverse tangent of 19.3 / 63.0, which is 17 degrees. So, the velocity of the car relative to the train is 66 km/hr, 17 degrees south of east.
Subject:
Subject X2:
Optics
Subject:
Subject X2:
Diffraction; Thin-film Interference
8-3-99
Diffraction
We discussed diffraction
in PY105 when we talked about sound waves; diffraction is the bending
of waves that occurs when a wave passes through a single narrow
opening. The analysis of the resulting diffraction pattern from a
single slit is similar to what we did for the double slit. With the
double slit, each slit acted as an emitter of waves, and these waves
interfered with each other. For the single slit, each part of the slit
can be thought of as an emitter of waves, and all these waves interfere
to produce the interference pattern we call the diffraction pattern.
After
we do the analysis, we'll find that the equation that gives the angles
at which fringes appear for a single slit is very similar to the one
for the double slit, one obvious difference being that the slit width
(W) is used in place of d, the distance between slits. A big difference
between the single and double slits, however, is that the equation that
gives the bright fringes for the double slit gives dark fringes for the
single slit.
To see why this is, consider the diagram below, showing light going away from the slit in one particular direction.
In the diagram above, let's say that the light leaving the edge of the
slit (ray 1) arrives at the screen half a wavelength out of phase with
the light leaving the middle of the slit (ray 5). These two rays would
interfere destructively, as would rays 2 and 6, 3 and 7, and 4 and 8.
In other words, the light from one half of the opening cancels out the
light from the other half. The rays are half a wavelength out of phase
because of the extra path length traveled by one ray; in this case that
extra distance is :
The factors of 2 cancel, leaving:
The argument can be extended to show that :
The
bright fringes fall between the dark ones, with the central bright
fringe being twice as wide, and considerably brighter, than the rest.
Diffraction effects with a double slit
Note
that diffraction can be observed in a double-slit interference pattern.
Essentially, this is because each slit emits a diffraction pattern, and
the diffraction patterns interfere with each other. The shape of the
diffraction pattern is determined by the width (W) of the slits, while
the shape of the interference pattern is determined by d, the distance
between the slits. If W is much larger than d, the pattern will be
dominated by interference effects; if W and d are about the same size
the two effects will contribute equally to the fringe pattern.
Generally what you see is a fringe pattern that has missing
interference fringes; these fall at places where dark fringes occur in
the diffraction pattern.
Diffraction gratings
We've
talked about what happens when light encounters a single slit
(diffraction) and what happens when light hits a double slit
(interference); what happens when light encounters an entire array of
identical, equally-spaced slits? Such an array is known as a
diffraction grating. The name is a bit misleading, because the
structure in the pattern observed is dominated by interference effects.
With
a double slit, the interference pattern is made up of wide peaks where
constructive interference takes place. As more slits are added, the
peaks in the pattern become sharper and narrower. With a large number
of slits, the peaks are very sharp. The positions of the peaks, which
come from the constructive interference between light coming from each
slit, are found at the same angles as the peaks for the double slit;
only the sharpness is affected.
Why
is the pattern much sharper? In the double slit, between each peak of
constructive interference is a single location where destructive
interference takes place. Between the central peak (m = 0) and the next
one (m = 1), there is a place where one wave travels 1/2 a wavelength
further than the other, and that's where destructive interference takes
place. For three slits, however, there are two places where destructive
interference takes place. One is located at the point where the path
lengths differ by 1/3 of a wavelength, while the other is at the place
where the path lengths differ by 2/3 of a wavelength. For 4 slits,
there are three places, for 5 slits there are four places, etc.
Completely constructive interference, however, takes place only when
the path lengths differ by an integral number of wavelengths. For a
diffraction grating, then, with a large number of slits, the pattern is
sharp because of all the destructive interference taking place between
the bright peaks where constructive interference takes place.
Diffraction
gratings, like prisms, disperse white light into individual colors. If
the grating spacing (d, the distance between slits) is known and
careful measurements are made of the angles at which light of a
particular color occurs in the interference pattern, the wavelength of
the light can be calculated.
Thin-film interference
Interference
between light waves is the reason that thin films, such as soap
bubbles, show colorful patterns. This is known as thin-film
interference, because it is the interference of light waves reflecting
off the top surface of a film with the waves reflecting from the bottom
surface. To obtain a nice colored pattern, the thickness of the film
has to be similar to the wavelength of light.
An important
consideration in determining whether these waves interfere
constructively or destructively is the fact that whenever light
reflects off a surface of higher index of refraction, the wave is
inverted. Peaks become troughs, and troughs become peaks. This is
referred to as a 180° phase shift in the wave, but the easiest way to
think of it is as an effective shift in the wave by half a wavelength.
Summarizing
this, reflected waves experience a 180° phase shift (half a wavelength)
when reflecting from a higher-n medium (n2 > n1), and no phase shift
when reflecting from a medium of lower index of refraction (n2 < n1).
For
completely constructive interference to occur, the two reflected waves
must be shifted by an integer multiple of wavelengths relative to one
another. This relative shift includes any phase shifts introduced by
reflections off a higher-n medium, as well as the extra distance
traveled by the wave that goes down and back through the film.
Note
that one has to be very careful in dealing with the wavelength, because
the wavelength depends on the index of refraction. Generally, in
dealing with thin-film interference the key wavelength is the
wavelength in the film itself. If the film has an index of refraction
n, this wavelength is related to the wavelength in vacuum by:
A step-by step approach
Many
people have trouble with thin-film interference problems. As usual,
applying a systematic, step-by-step approach is best. The overall goal
is to figure out the shift of the wave reflecting from one surface of
the film relative to the wave that reflects off the other surface.
Depending on the situation, this shift is set equal to the condition
for constructive interference, or the condition for destructive
interference.
Note that typical thin-film interference problems involve
"normally-incident" light. The light rays are not drawn perpendicular
to the interfaces on the diagram to make it easy to distinguish between
the incident and reflected rays. In the discussion below it is assumed
that the incident and reflected rays are perpendicular to the
interfaces.
A good method for analyzing a thin-film problem involves these steps:
Step 1. Write down , the shift for the wave reflecting off the top surface of the film.
Step 2. Write down , the shift for the wave reflecting off the film's bottom surface.
One contribution to this shift comes from the extra distance
travelled. If the film thickness is t, this wave goes down and back
through the film, so its path length is longer by 2t. The other
contribution to this shift can be either 0 or , depending on what happens when it reflects (this reflection occurs at point b on the diagram).
Step 3. Calculate the relative shift by subtracting the individual shifts.
Step 4. Set the relative shift equal to the condition for constructive
interference, or the condition for destructive interference, depending
on the situation. If a certain film looks red in reflected light, for
instance, that means we have constructive interference for red light.
If the film is dark, the light must be interfering destructively.
Step 5. Rearrange the equation (if necessary) to get all factors of on one side.
Step 6. Remember that the wavelength in your equation is the
wavelength in the film itself. Since the film is medium 2 in the
diagram above, we can label it The wavelength in the film is related to the wavelength in vacuum by:
Step
7. Solve. Your equation should give you a relationship between t, the
film thickness, and either the wavelength in vacuum or the wavelength
in the film.
Example - a film of oil on water
Working
through an example is a good way to see how the step-by-step approach
is applied. In this case, white light in air shines on an oil film that
floats on water. When looking straight down at the film, the reflected
light is red, with a wavelength of 636 nm. What is the minimum possible
thickness of the film?
Step 1. Because oil has a higher index of refraction than air, the wave
reflecting off the top surface of the film is shifted by half a
wavelength.
Step 2. Because water has a lower index of refraction than oil, the
wave reflecting off the bottom surface of the film does not have a
half-wavelength shift, but it does travel the extra distance of 2t.
Step 3. The relative shift is thus:
Step 4. Now, is this constructive interference or destructive
interference? Because the film looks red, there is constructive
interference taking place for the red light.
Step 5. Moving all factors of the wavelength to the right side of the equation gives:
Note that this looks like an equation for destructive interference! It
isn't, because we used the condition for constructive interference in
step 4. It looks like a destructive interference equation only because
one reflected wave experienced a
shift.
Step 6. The wavelength in the equation above is the wavelength
in the thin film. Writing the equation so this is obvious can be done
in a couple of different ways:
Step 7. The equation can now be solved. In this situation, we are asked
to find the minimum thickness of the film. This means choosing the
minimum value of m, which in this case is m = 0. The question specified
the wavelength of red light in vacuum, so:
This
is not the only thickness that gives completely constructive
interference for this wavelength. Others can be found by using m = 1, m
= 2, etc. in the equation in step 6.
If 106 nm gives
constructive interference for red light, what about the other colors?
They are not completely cancelled out, because 106 nm is not the right
thickness to give completely destructive interference for any
wavelength in the visible spectrum. The other colors do not reflect as
intensely as red light, so the film looks red.
Why is it the wavelength in the film itself that matters?
The
light reflecting off the top surface of the film does not pass through
the film at all, so how can it be the wavelength in the film that is
important in thin-film interference? A diagram can help clarify this.
The diagram looks a little complicated at first glance, but it really
is straightforward once you understand what it shows.
Figure A shows a wave incident on a thin film. Each half wavelength
has been numbered, so we can keep track of it. Note that the thickness
of the film is exactly half the wavelength of the wave when it is in
the film.
Figure B shows the situation two periods later, after two
complete wavelengths have encountered the film. Part of the wave is
reflected off the top surface of the film; note that this reflected
wave is flipped by 180°, so peaks are now troughs and troughs are now
peaks. This is because the wave is reflecting off a higher-n medium.
Another part of the wave reflects off the bottom surface of the
film. This does not flip the wave, because the reflection is from a
lower-n medium. When this wave re-emerges into the first medium, it
destructively interferes with the wave that reflects off the top
surface. This occurs because the film thickness is exactly half the
wavelength of the wave in the film. Because a half wavelength fits in
the film, the peaks of one reflected wave line up precisely with the
troughs of the other (and vice versa), so the waves cancel. Destructive
interference would also occur with the film thickness being equal to 1
wavelength of the wave in the film, or 1.5 wavelengths, 2 wavelengths,
etc.
If the thickness was 1/4, 3/4, 5/4, etc. the wavelength in the
film, constructive interference occurs. This is only true when one of
the reflected waves experiences a half wavelength shift (because of the
relative sizes of the refractive indices). If neither wave, or both
waves, experiences a shift of
, there would be constructive interference whenever the film thickness
was 0.5, 1, 1.5, 2, etc. wavelengths, and destructive interference if
the film was 1/4, 3/4, 5/4, etc. of the wavelength in the film.
One
final philosophical note, to really make your head spin if it isn't
already. In the diagram above we drew the two reflected waves and saw
how they cancelled out. This means none of the wave energy is reflected
back into the first medium. Where does it go? It must all be
transmitted into the third medium (that's the whole point of a
non-reflective coating, to transmit as much light as possible through a
lens). So, even though we did the analysis by drawing the waves
reflecting back, in some sense they really don't reflect back at all,
because all the light ends up in medium 3.
Non-reflective coatings
Destructive
interference is exploited in making non-reflective coatings for lenses.
The coating material generally has an index of refraction less than
that of glass, so both reflected waves have a shift. A film thickness of 1/4 the wavelength in the film results in destructive interference (this is derived below)
For non-reflective coatings in a case like this, where the index of
refraction of the coating is between the other two indices of
refraction, the minimum film thickness can be found by applying the
step-by-step approach:
Subject:
Subject X2:
Electromagnetic Waves
7-26-99
At this point in the course we'll move into optics. This might seem like a separate topic from electricity and magnetism, but optics is really a sub-topic of electricity and magnetism. This is because optics deals with the behavior of light, and light is one example of an electromagnetic wave.
Light and other electromagnetic waves
Light is not the only example of an electromagnetic wave. Other electromagnetic waves include the microwaves you use to heat up leftovers for dinner, and the radio waves that are broadcast from radio stations. An electromagnetic wave can be created by accelerating charges; moving charges back and forth will produce oscillating electric and magnetic fields, and these travel at the speed of light. It would really be more accurate to call the speed "the speed of an electromagnetic wave", because light is just one example of an electromagnetic wave.
speed of light in vacuum: c = 3.00 x 108 m/s
As we'll go into later in the course when we get to relativity, c is the ultimate speed limit in the universe. Nothing can travel faster than light in a vacuum.
There is a wonderful connection between c, the speed of light in a vacuum, and the constants that appeared in the electricity and magnetism equations, the permittivity of free space and the permeability of free space. James Clerk Maxwell, who showed that all of electricity and magnetism could be boiled down to four basic equations, also worked out that:
![]()
This clearly shows the link between optics, electricity, and magnetism.
Creating an electromagnetic wave
We've already learned how moving charges (currents) produce magnetic fields. A constant current produces a constant magnetic field, while a changing current produces a changing field. We can go the other way, and use a magnetic field to produce a current, as long as the magnetic field is changing. This is what induced emf is all about. A steadily-changing magnetic field can induce a constant voltage, while an oscillating magnetic field can induce an oscillating voltage.
Focus on these two facts:
1. an oscillating electric field generates an oscillating magnetic field
2. an oscillating magnetic field generates an oscillating electric field
Those two points are key to understanding electromagnetic waves.
An electromagnetic wave (such as a radio wave) propagates outwards from the source (an antenna, perhaps) at the speed of light. What this means in practice is that the source has created oscillating electric and magnetic fields, perpendicular to each other, that travel away from the source. The E and B fields, along with being perpendicular to each other, are perpendicular to the direction the wave travels, meaning that an electromagnetic wave is a transverse wave. The energy of the wave is stored in the electric and magnetic fields.
Properties of electromagnetic waves
Something interesting about light, and electromagnetic waves in general, is that no medium is required for the wave to travel through. Other waves, such as sound waves, can not travel through a vacuum. An electromagnetic wave is perfectly happy to do that.
An electromagnetic wave, although it carries no mass, does carry energy. It also has momentum, and can exert pressure (known as radiation pressure). The reason tails of comets point away from the Sun is the radiation pressure exerted on the tail by the light (and other forms of radiation) from the Sun.
The energy carried by an electromagnetic wave is proportional to the frequency of the wave. The wavelength and frequency of the wave are connected via the speed of light:
![]()
Electromagnetic waves are split into different categories based on their frequency (or, equivalently, on their wavelength). In other words, we split up the electromagnetic spectrum based on frequency. Visible light, for example, ranges from violet to red. Violet light has a wavelength of 400 nm, and a frequency of 7.5 x 1014 Hz. Red light has a wavelength of 700 nm, and a frequency of 4.3 x 1014 Hz. Any electromagnetic wave with a frequency (or wavelength) between those extremes can be seen by humans.
Visible light makes up a very small part of the full electromagnetic spectrum. Electromagnetic waves that are of higher energy than visible light (higher frequency, shorter wavelength) include ultraviolet light, X-rays, and gamma rays. Lower energy waves (lower frequency, longer wavelength) include infrared light, microwaves, and radio and television waves.
Energy in an electromagnetic wave
The energy in an electromagnetic wave is tied up in the electric and magnetic fields. In general, the energy per unit volume in an electric field is given by:
![]()
In a magnetic field, the energy per unit volume is:
![]()
An electromagnetic wave has both electric and magnetic fields, so the
total energy density associated with an electromagnetic wave is:
![]()
It turns out that for an electromagnetic wave, the energy associated
with the electric field is equal to the energy associated with the
magnetic field, so the energy density can be written in terms of just
one or the other:
![]()
This also implies that in an electromagnetic wave, E = cB.
A more common way to handle the energy is to look at how much
energy is carried by the wave from one place to another. A good measure
of this is the intensity of the wave, which is the power that passes
perpendicularly through an area divided by the area. The intensity, S,
and the energy density are related by a factor of c:
![]()
Generally, it's most useful to use the average power, or average
intensity, of the wave. To find the average values, you have to use
some average for the electric field E and the magnetic field B. The
root mean square averages are used; the relationship between the peak
and rms values is:
![]()
Subject:
Subject X2:
Interference
7-29-99
The wave nature of light
When we discussed the reflection and refraction of light, light was
interacting with mirrors and lenses. These objects are much larger than
the wavelength of light, so the analysis can be done using geometrical
optics, a simple model that uses rays and wave fronts. In this chapter
we'll need a more sophisticated model, physical optics, which treats
light as a wave. The wave properties of light are important in
understanding how light interacts with objects such as narrow openings
or thin films that are about the size of the wavelength of light.
Because physical optics deals with light as a wave, it is helpful to
have a quick review of waves. The principle of linear superposition is
particularly important.
Linear superposition
When two or more waves come together, they will interfere with each
other. This interference may be constructive or destructive. If you
take two waves and bring them together, they will add wherever a peak
from one matches a peak from the other. That's constructive
interference. Wherever a peak from one wave matches a trough in another
wave, however, they will cancel each other out (or partially cancel, if
the amplitudes are different); that's destructive interference.
The most interesting cases of interference usually involve identical
waves, with the same amplitude and wavelength, coming together.
Consider the case of just two waves, although we can generalize to more
than two. If these two waves come from the same source, or from sources
that are emitting waves in phase, then the waves will interfere
constructively at a certain point if the distance traveled by one wave
is the same as, or differs by an integral number of wavelengths from,
the path length traveled by the second wave. For the waves to interfere
destructively, the path lengths must differ by an integral number of
wavelengths plus half a wavelength.
Young's double slit
Light, because of its wave properties, will show constructive and
destructive interference. This was first shown in 1801 by Thomas Young,
who sent sunlight through two narrow slits and showed that an
interference pattern could be seen on a screen placed behind the two
slits. The interference pattern was a set of alternating bright and
dark lines, corresponding to where the light from one slit was
alternately constructively and destructively interfering with the light
from the second slit.
You might think it would be easier to simply set up two light sources
and look at their interference pattern, but the phase relationship
between the waves is critically important, and two sources tend to have
a randomly varying phase relationship. With a single source shining on
two slits, the relative phase of the light emitted from the two slits
is kept constant.
This makes use of Huygen's principle, the idea that each point on a
wave can be considered to be a source of secondary waves. Applying this
to the two slits, each slit acts as a source of light of the same
wavelength, with the light from the two slits interfering
constructively or destructively to produce an interference pattern of
bright and dark lines.
This pattern of bright and dark lines is known as a fringe pattern, and
is easy to see on a screen. The bright fringe in the middle is caused
by light from the two slits traveling the same distance to the screen;
this is known as the zero-order fringe.The dark fringes on either side
of the zero-order fringe are caused by light from one slit traveling
half a wavelength further than light from the other slit. These are
followed by the first-order fringes (one on each side of the zero-order
fringe), caused by light from one slit traveling a wavelength further
than light from the other slit, and so on.
The diagram above shows the geometry for the fringe pattern. For two
slits separated by a distance d, and emitting light at a particular
wavelength, light will constructively interfere at certain angles.
These angles are found by applying the condition for constructive
interference, which in this case becomes:
The angles at which dark fringes occur can be found be applying the condition for destructive interference:
If the interference pattern was being viewed on a screen a distance L
from the slits, the wavelength can be found from the equation:
where y is the distance from the center of the interference pattern to
the mth bright line in the pattern. That applies as long as the angle
is small (i.e., y must be small compared to L).
Dispersion
Although we talk about an index of refraction for a particular
material, that is really an average value. The index of refraction
actually depends on the frequency of light (or, equivalently, the
wavelength). For visible light, light of different colors means light
of different wavelength. Red light has a wavelength of about 700 nm,
while violet, at the other end of the visible spectrum, has a
wavelength of about 400 nm.
This doesn't mean that all violet light is at 400 nm. There are
different shades of violet, so violet light actually covers a range of
wavelengths near 400 nm. Likewise, all the different shades of red
light cover a range near 700 nm.
Because the refractive index depends on the wavelength, light of
different colors (i.e., wavelengths) travels at different speeds in a
particular material, so they will be refracted through slightly
different angles inside the material. This is called dispersion,
because light is dispersed into colors by the material.
When you see a rainbow in the sky, you're seeing something produced by
dispersion and internal reflection of light in water droplets in the
atmosphere. Light from the sun enters a spherical raindrop, and the
different colors are refracted at different angles, reflected off the
back of the drop, and then bent again when they emerge from the drop.
The different colors, which were all combined in white light, are now
dispersed and travel in slightly different directions. You see red
light coming from water droplets higher in the sky than violet light.
The other colors are found between these, making a rainbow.
Rainbows are usually seen as half circles. If you were in a plane or on
a very tall building or mountain, however, you could see a complete
circle. In double rainbows the second, dimmer, band, which is higher in
the sky than the first, comes from light reflected twice inside a
raindrop. This reverses the order of the colors in the second band.
Subject:
Subject X2:
Lenses
Total internal reflection, and Lenses
7-28-99
Total internal reflection

When light crosses an interface into a medium with a higher index of
refraction, the light bends towards the normal. Conversely, light
traveling across an interface from higher n to lower n will bend away
from the normal. This has an interesting implication: at some angle,
known as the critical angle, light travelling from a medium with higher
n to a medium with lower n will be refracted at 90°; in other words,
refracted along the interface. If the light hits the interface at any
angle larger than this critical angle, it will not pass through to the
second medium at all. Instead, all of it will be reflected back into
the first medium, a process known as total internal reflection.
The critical angle can be found from Snell's law, putting in an angle of 90° for the angle of the refracted ray. This gives:
![]()
For any angle of incidence larger than the critical angle, Snell's law
will not be able to be solved for the angle of refraction, because it
will show that the refracted angle has a sine larger than 1, which is
not possible. In that case all the light is totally reflected off the
interface, obeying the law of reflection.
Optical fibers are based entirely on this principle of total internal
reflection. An optical fiber is a flexible strand of glass. A fiber
optic cable is usually made up of many of these strands, each carrying
a signal made up of pulses of laser light. The light travels along the
optical fiber, reflecting off the walls of the fiber. With a straight
or smoothly bending fiber, the light will hit the wall at an angle
higher than the critical angle and will all be reflected back into the
fiber. Even though the light undergoes a large number of reflections
when traveling along a fiber, no light is lost.
Depth perception
Because light is refracted at interfaces, objects you see across an
interface appear to be shifted relative to where they really are. If
you look straight down at an object at the bottom of a glass of water,
for example, it looks closer to you than it really is. Looking
perpendicular to an interface, the apparent depth is related to the
actual depth by:
![]()
An example
A beam of light travels from water into a piece of diamond in the shape
of a triangle, as shown in the diagram. Step-by-step, follow the beam
until it emerges from the piece of diamond.

(a) How fast is the light traveling inside the piece of diamond?
The speed can be calculated from the index of refraction:
![]()
(b) What is ![]()
, the angle between the normal and the beam of light inside the diamond at the water-diamond interface?
A diagram helps for this. In fact, let's look at the complete
diagram of the whole path, and use this for the rest of the questions.

The angle we need can be found from Snell's law:

(c) The beam travels up to the air-diamond interface. What is ![]() , the angle between the normal and the beam of light inside the diamond at the air-diamond interface?
, the angle between the normal and the beam of light inside the diamond at the air-diamond interface?
This is found using a bit of geometry. All you need to know is that the sum of the three angles inside a triangle is 180°. If ![]() is 24.9°, this means that the third angle in that triangle must be 25.1°. So:
is 24.9°, this means that the third angle in that triangle must be 25.1°. So:
![]()
(d) What is the critical angle for the diamond-air interface?
![]()
(e) What happens to the light at the diamond-air interface?
Because the angle of incidence (64.9°) is larger than the critical angle, the light is totally reflected internally.
(f) The light is reflected off the interface, obeying the law of
reflection. It then strikes the diamond-water interface. What happens
to it here?
Again, the place to start is by determining the angle of incidence, ![]() . A little geometry shows that:
. A little geometry shows that:
![]()
The critical angle at this interface is :
![]()
Because the angle of incidence is less than the critical angle, the
beam will escape from the piece of diamond here. The angle of
refraction can be found from Snell's law:

Lenses
There are many similarities between lenses and mirrors. The mirror
equation, relating focal length and the image and object distances for
mirrors, is the same as the lens equation used for lenses.There are
also some differences, however; the most important being that with a
mirror, light is reflected, while with a lens an image is formed by
light that is refracted by, and transmitted through, the lens. Also,
lenses have two focal points, one on each side of the lens.
The surfaces of lenses, like spherical mirrors, can be treated as
pieces cut from spheres. A lens is double sided, however, and the two
sides may or may not have the same curvature. A general rule of thumb
is that when the lens is thickest in the center, it is a converging
lens, and can form real or virtual images. When the lens is thickest at
the outside, it is a diverging lens, and it can only form virtual
images.
Consider first a converging lens, the most common type being a double
convex lens. As with mirrors, a ray diagram should be drawn to get an
idea of where the image is and what the image characteristics are.
Drawing a ray diagram for a lens is very similar to drawing one for a
mirror. The parallel ray is drawn the same way, parallel to the optic
axis, and through (or extended back through) the focal point. The chief
difference in the ray diagram is with the chief ray. That is drawn from
the tip of the object straight through the center of the lens. Wherever
the two rays meet is where the image is. The third ray, which can be
used as a check, is drawn from the tip of the object through the focal
point that is on the same side of the lens as the object. That ray
travels through the lens, and is refracted so it travels parallel to
the optic axis on the other side of the lens.

The two sides of the lens are referred to as the object side (the
side where the object is) and the image side. For lenses, a positive
image distance means that the image is real and is on the image side. A
negative image distance means the image is on the same side of the lens
as the object; this must be a virtual image.
Using that sign convention gives a lens equation identical to the spherical mirror equation:
![]()
The other signs work the same way as for mirrors. The focal length,
f, is positive for a converging lens, and negative for a diverging
lens.
The magnification factor is also given by the same equation:
![]()
Useful devices like microscopes and telescopes rely on at least two
lenses (or mirrors). A microscope, for example, is a compound lens
system with two converging lenses. One important thing to note is that
with two lenses (and you can extend the argument for more than two),
the magnification factor m for the two lens system is the product of
the two individual magnification factors.
It works this way. The first lens takes an object and creates an image
at a particular point, with a certain magnification factor (say, 3
times as large). The second lens uses the image created by the first
lens as the object, and creates a final image, introducing a second
magnification factor (say, a factor of seven). The magnification factor
of the final image compared to the original object is the product of
the two magnification factors (3 x 7 = 21, in this case).
Ray diagram for a diverging lens
Consider now the ray diagram for a diverging lens. Diverging lenses
come in a few different shapes, but all diverging lens are fatter on
the edge than they are in the center. A good example of a diverging
lens is a bi-concave lens, as shown in the diagram. The object in this
case is beyond the focal point, and, as usual, the place where the
refracted rays appear to diverge from is the location of the image. A
diverging lens always gives a virtual image, because the refracted rays
have to be extended back to meet.

Note that a diverging lens will refract parallel rays so that they
diverge from each other, while a converging lens refracts parallel rays
toward each other.
An example
We can use the ray diagram above to do an example. If the focal
length of the diverging lens is -12.0 cm (f is always negative for a
diverging lens), and the object is 22.0 cm from the lens and 5.0 cm
tall, where is the image and how tall is it?
Working out the image distance using the lens equation gives:
![]()
This can be rearranged to:
![]()
The negative sign signifies that the image is virtual, and on the
same side of the lens as the object. This is consistent with the ray
diagram.
The magnification of the lens for this object distance is:
![]()
So the image has a height of 5 x 0.35 = 1.75 cm.
Sign convention
The sign convention for lenses is similar to that for mirrors. Again,
take the side of the lens where the object is to be the positive side.
Because a lens transmits light rather than reflecting it like a mirror
does, the other side of the lens is the positive side for images. In
other words, if the image is on the far side of the lens as the object,
the image distance is positive and the image is real. If the image and
object are on the same side of the lens, the image distance is negative
and the image is virtual.
For converging mirrors, the focal length is positive. Similarly, a
converging lens always has a positive f, and a diverging lens has a
negative f.
The signs associated with magnification also work the same way for
lenses and mirrors. A positive magnification corresponds to an upright
image, while a negative magnification corresponds to an inverted image.
As usual, upright and inverted are taken relative to the orientation of
the object.
Note that in certain cases involving more than one lens the object
distance can be negative. This occurs when the image from the first
lens lies on the far side of the second lens; that image is the object
for the second lens, and is called a virtual object.
Subject:
Subject X2:
Microscopes and Telescopes
Optical instruments
8-5-99
Making things look bigger
When you use an optical instrument, whether it be something very simple like a magnifying glass, or more complicated like a telescope or microscope, you're usually trying to make things look bigger so you can more easily see fine details. One thing to remember about this is that if you want to make things look bigger, you're always going to use converging mirrors or lenses. Diverging mirrors or lenses always give smaller images.
When using a converging lens, it's helpful to remember these rules of thumb. If the object is very far away, the image will be tiny and very close to the focal point. As the object moves towards the lens, the image moves out from the focal point, growing as it does so. The object and image are exactly the same size when the object is at 2F, twice the focal distance from the lens. Moving the object from 2F towards F, the image keeps moving out away from the lens, and growing, until it goes to infinity when the object is at F, the focal point. Moving the object still closer to the lens, the image steadily comes in towards the lens from minus infinity, and gets smaller the closer the object is to the lens.
Note that similar rules of thumb apply for a converging mirror, too.
Multiple lenses
Many useful devices, such as microscopes and telescopes, use more than one lens to form images. To analyze any system with more than one lens, work in steps. Each lens takes an object and creates an image. The original object is the object for the first lens, and that creates an image. That image is the object for the second lens, and so on. We won't use more than two lenses, and we can do a couple of examples to see how you analyze problems like this.
A microscope
A basic microscope is made up of two converging lenses. One reason for using two lenses rather than just one is that it's easier to get higher magnification. If you want an overall magnification of 35, for instance, you can use one lens to magnify by a factor of 5, and the second by a factor of 7. This is generally easier to do than to get magnification by a factor of 35 out of a single lens.
A microscope arrangement is shown below, along with the ray diagram showing how the first lens creates a real image. This image is the object for the second lens, and the image created by the second lens is the one you'd see when you looked through the microscope.
Note that the final image is virtual, and is inverted compared to the original object. This is true for many types of microscopes and telescopes, that the image produced is inverted compared to the object.
An example using the microscope
Let's use the ray diagram for the microscope and work out a numerical example. The parameters we need to specify are:
To work out the image distance for the image formed by the objective lens, use the lens equation, rearranged to:
The magnification of the image in the objective lens is:
So the height of the image is -1.8 x 1.0 = -1.8 mm.
This image is the object for the second lens, and the object distance has to be calculated:
The image, virtual in this case, is located at a distance of:
The magnification for the eyepiece is:
So the height of the final image is -1.8 mm x 3.85 = -6.9 mm.
The overall magnification of the two lens system is:
This is equal to the final height divided by the height of the object, as it should be. Note that, applying the sign conventions, the final image is virtual, and inverted compared to the object. This is consistent with the ray diagram.
Telescopes
A telescope needs at least two lenses. This is because you use a telescope to look at an object very far away, so the first lens creates a small image close to its focal point. The telescope is designed so the real, inverted image created by the first lens is just a little closer to the second lens than its focal length. As with the magnifying glass, this gives a magnified virtual image. This final image is also inverted compared to the original object. With astronomical telescopes, this doesn't really matter, but if you're looking at something on the Earth you generally want an upright image. This can be obtained with a third lens.
Note that the overall effect of the telescope is to magnify, which means the absolute value of the magnification must be larger than 1. The first lens (the objective) has a magnification smaller than one, so the second lens (the eyepiece) must magnify by a larger factor than the first lens reduces by. To a good approximation, the overall magnification is equal to the ratio of the focal lengths. With o standing for objective and e for eyepiece, the magnification is given by:
m = - fo / fe, with the minus sign meaning that the image is inverted.
Resolving power
The resolving power of an optical instrument, such as your eye, or a telescope, is its ability to separate far-away objects that are close together into individual images, as opposed to a single merged image. If you look at two stars in the sky, for example, you can tell they are two stars if they're separated by a large enough angle. Some stars, however, are so close together that they look like one star. You can only see that they are two stars by looking at them through a telescope. So, why does the telescope resolve the stars into separate objects while your eye can not? It's all because of diffraction.
If you look at a far-away object, the image of the object will form a diffraction pattern on your retina. For two far-away objects separated by a small angle, the diffraction patterns will overlap. You are able to resolve the two objects as long as the central peaks in the two diffraction patterns don't overlap. The limit is when one central peak falls at the position of the first dark fringe for the second diffraction pattern. This is known as the Rayleigh criterion. Once the two central peaks start to overlap, in other words, the two objects look like one.
The size of the central peak in the diffraction pattern depends on the size of the aperture (the opening you look through). For your eye, this is your pupil. A telescope, or even a camera, has a much larger aperture, and therefore more resolving power. The minimum angular separation is given by:
The factor of 1.22 applies to circular apertures like your pupil, a telescope, or a camera lens.
The closer you are to two objects, the greater the angular separation between them. Up close, then, two objects are easily resolved. As you get further from the objects, however, they will eventually merge to become one.
X-ray diffraction
Things that look a lot like diffraction gratings, orderly arrays of equally-spaced objects, are found in nature; these are crystals. Many solid materials (salt, diamond, graphite, metals, etc.) have a crystal structure, in which the atoms are arranged in a repeating, orderly, 3-dimensional pattern. This is a lot like a diffraction grating, only a three-dimensional grating. Atoms in a typical solid are separated by an angstrom or a few angstroms; . This is much smaller than the wavelength of visible light, but
x-rays have wavelengths of about this size. X-rays interact with
crystals, then, in a way very similar to the way light interacts with a
grating.
X-ray diffraction is a very powerful tool used to study crystal
structure. By examining the x-ray diffraction pattern, the type of
crystal structure (i.e., the pattern in which the atoms are arranged)
can be identified, and the spacing between atoms can be determined.
The two diagrams below can help to understand how x-ray
diffraction works. Each represents atoms arranged in a particular
crystal structure.
You can think of the diffraction pattern like this. When x-rays come in
at a particular angle, they reflect off the different planes of atoms
as if they were plane mirrors. However, for a particular set of planes,
the reflected waves interfere with each other. A reflected x-ray signal
is only observed if the conditions are right for constructive
interference. If d is the distance between planes, reflected x-rays are
only observed under these conditions:
That's known as Bragg's law. The important thing to notice is that the
angles at which you see reflected x-rays are related to the spacing
between planes of atoms. By measuring the angles at which you see
reflected x-rays, you can deduce the spacing between planes and
determine the structure of the crystal.
Subject:
Subject X2:
Polarization; and The Human Eye
8-4-99
Polarization
To talk about the polarization of an electromagnetic wave, it's easiest to look at polarized light. Just remember that whatever applies to light generally applies to other forms of electromagnetic waves, too. So, what is meant by polarized light? It's light in which there's a preferred direction for the electric and magnetic field vectors in the wave. In unpolarized light, there is no preferred direction: the waves come in with electric and magnetic field vectors in random directions. In linearly polarized light, the electric field vectors are all along one line (and so are the magnetic field vectors, because they're perpendicular to the electric field vectors). Most light sources emit unpolarized light, but there are several ways light can be polarized.
One way to polarize light is by reflection. Light reflecting off a surface will tend to be polarized, with the direction of polarization (the way the electric field vectors point) being parallel to the plane of the interface.
Another way to polarize light is by selectively absorbing light with electric field vectors pointing in a particular direction. Certain materials, known as dichroic materials, do this, absorbing light polarized one way but not absorbing light polarized perpendicular to that direction. If the material is thick enough to absorb all the light polarized in one direction, the light emerging from the material will be linearly polarized. Polarizers (such as the lenses of polarizing sunglasses) are made from this kind of material.
If unpolarized light passes through a polarizer, the intensity of the transmitted light will be 1/2 of what it was coming in. If linearly polarized light passes through a polarizer, the intensity of the light transmitted is given by Malus' law:
A third way to polarize light is by scattering. Light scattering off atoms and molecules in the atmosphere is unpolarized if the light keeps traveling in the same direction, is linearly polarized if at scatters in a direction perpendicular to the way it was traveling, and somewhere between linearly polarized and unpolarized if it scatters of at another angle.
There are plenty of materials that affect the polarization of light. Certain materials (such as calcite) exhibit a property known as birefringence. A crystal of birefringent material affects light polarized in a particular direction differently from light polarized at 90 degrees to that direction; it refracts light polarized one way at a different angle than it refracts light polarized the other way. Looking through a birefringent crystal at something, you'd see a double image.
Liquid crystal displays, such as those in digital watches and calculators, also exploit the properties of polarized light.
Polarization by reflection
One way to polarize light is by reflection. If a beam of light strikes an interface so that there is a 90° angle between the reflected and refracted beams, the reflected beam will be linearly polarized. The direction of polarization (the way the electric field vectors point)is parallel to the plane of the interface.
The special angle of incidence that satisfies this condition, where the reflected and refracted beams are perpendicular to each other, is known as the Brewster angle. The Brewster angle, the angle of incidence required to produce a linearly-polarized reflected beam, is given by:
This expression can be derived using Snell's law, and the law of
reflection. The diagram below shows some of the geometry involved.
Using Snell's law:
The scattering of light in the atmosphere
The way light scatters off molecules in the atmosphere explains why the sky is blue and why the sun looks red at sunrise and sunset. In a nutshell, it's because the molecules scatter light at the blue end of the visible spectrum much more than light at the red end of the visible spectrum. This is because the scattering of light (i.e., the probability that light will interact with molecules when it passes through the atmosphere) is inversely proportional to the wavelength to the fourth power.
Violet light, with a wavelength of about 400 nm, is almost 10 times
as likely to be scattered than red light, which has a wavelength of
about 700 nm. At noon, when the Sun is high in the sky, light from the
Sun passes through a relatively thin layer of atmosphere, so only a
small fraction of the light will be scattered. The Sun looks
yellow-white because all the colors are represented almost equally. At
sunrise or sunset, on the other hand, light from the Sun has to pass
through much more atmosphere to reach our eyes. Along the way, most of
the light towards the blue end of the spectrum is scattered in other
directions, but much less of the light towards the red end of the
spectrum is scattered, making the Sun appear to be orange or red.
So why is the sky blue? Again, let's look at it when the Sun is
high in the sky. Some of the light from the Sun traveling towards other
parts of the Earth is scattered towards us by the molecules in the
atmosphere. Most of this scattered light is light from the blue end of
the spectrum, so the sky appears blue.
Why can't this same argument be applied to clouds? Why do they
look white, and not blue? It's because of the size of the water
droplets in clouds. The droplets are much larger than the molecules in
the atmosphere, and they scatter light of all colors equally. This
makes them look white.
Optics of the eye
The human eye is a wonderful instrument, relying on refraction and lenses to form images. There are many similarities between the human eye and a camera, including:
* a diaphragm to control the amount of light that gets through to the lens. This is the shutter in a camera, and the pupil, at the center of the iris, in the human eye.
* a lens to focus the light and create an image. The image is real and inverted.
* a method of sensing the image. In a camera, film is used to record the image; in the eye, the image is focused on the retina, and a system of rods and cones is the front end of an image-processing system that converts the image to electrical impulses and sends the information along the optic nerve to the brain.
The way the eye focuses light is interesting, because most of the refraction that takes place is not done by the lens itself, but by the aqueous humor, a liquid on top of the lens. Light is refracted when it comes into the eye by this liquid, refracted a little more by the lens, and then a bit more by the vitreous humor, the jelly-like substance that fills the space between the lens and the retina.
The lens is critical in forming a sharp image, however; this is one of the most amazing features of the human eye, that it can adjust so quickly when focusing objects at different distances. This process of adjustment is known as accommodation.
Consider the lens equation:
With a camera, the lens has a fixed focal length. If the object distance is changed, the image distance (the distance between the lens and the film) is adjusted by moving the lens. This can't be done with the human eye: the image distance, the distance between the lens and the retina, is fixed. If the object distance is changed (i.e., the eye is trying to focus objects that are at different distances), then the focal length of the eye is adjusted to create a sharp image. This is done by changing the shape of the lens; a muscle known as the ciliary muscle does this job.
Nearsightedness
A person who is nearsighted can only create sharp images of close objects. Objects that are further away look fuzzy because the eye brings them in to focus at a point in front of the retina. To correct for this, a diverging lens is placed in front of the eye, diverging the light rays just enough so that when the rays are converged by the eye they converge on the retina, creating a focused image.
Farsightedness
A farsighted person can only create clear images of objects that are far away. Close objects are brought to a focus behind the retina, which is why they look fuzzy. To correct for this, a converging lens is placed in front of the eye, allowing images to be brought into sharp focus at the retina.
Diopters
If you go to an optometrist to get glasses or contact lenses, you will get a prescription specified in units of diopters. This is a measure of the refractive power of the lens needed, which means it's a measure of the focal length of the lens. The two are, in fact, inversely related:
refractive power in diopters = 1 / focal length in meters
A diopter has units of 1 / m .
If the lenses you get are specified as 5.0 diopters, it means they have a focal length of 0.2 m, meaning that they are converging lenses that bring parallel rays of light to a focus 0.2 m beyond the lens. Similarly, lenses of -2.0 diopters correspond to a focal length of -0.5 m; these would be diverging lenses with a focal point 0.5 m from the lens.
Lens aberrations
Lenses can distort the image of an object for a number of reasons. One kind of distortion is known as spherical aberration; this occurs because parallel rays of light are not all focused to a single point by a spherical lens. The further a ray is from the principal axis, the more it misses the focal point.
A second kind of distortion is chromatic aberration. This occurs because a lens will have a slightly different index of refraction for light of different wavelengths (i.e., light of different colors). In other words, chromatic aberration is caused by dispersion. Parallel rays of red light, therefore, would be brought to a different focal point than parallel rays of light of another color, leading to a blurry image.
To minimize chromatic aberration, many high-quality lenses are made up of two lenses made from different materials. One lens will be converging, and the other diverging; the compound lens will still be converging overall, generally. The chromatic aberration introduced by one lens is corrected for in the second lens, bringing parallel rays of any color light to about the same focal point.
Subject:
Subject X2:
Reflection and Refraction
The reflection and refraction of light
7-27-99
Rays and wave fronts Light is a very complex phenomenon, but in many situations its behavior
can be understood with a simple model based on rays and wave fronts. A
ray is a thin beam of light that travels in a straight line. A wave
front is the line (not necessarily straight) or surface connecting all
the light that left a source at the same time. For a source like the
Sun, rays radiate out in all directions; the wave fronts are spheres
centered on the Sun. If the source is a long way away, the wave fronts
can be treated as parallel lines.
Rays and wave fronts can generally be used to represent light when
the light is interacting with objects that are much larger than the
wavelength of light, which is about 500 nm. In particular, we'll use
rays and wave fronts to analyze how light interacts with mirrors and
lenses.
The law of reflection
Objects can be seen by the light they emit, or, more often, by the
light they reflect. Reflected light obeys the law of reflection, that
the angle of reflection equals the angle of incidence.
For objects such as mirrors, with surfaces so smooth that any hills or
valleys on the surface are smaller than the wavelength of light, the
law of reflection applies on a large scale. All the light travelling in
one direction and reflecting from the mirror is reflected in one
direction; reflection from such objects is known as specular
reflection.
Most objects exhibit diffuse reflection, with light being reflected
in all directions. All objects obey the law of reflection on a
microscopic level, but if the irregularities on the surface of an
object are larger than the wavelength of light, which is usually the
case, the light reflects off in all directions.
Plane mirrors A plane mirror is simply a mirror with a flat surface; all of us use
plane mirrors every day, so we've got plenty of experience with them.
Images produced by plane mirrors have a number of properties,
including:
1. the image produced is upright
2. the image is the same size as the object (i.e., the magnification is m = 1)
3. the image is the same distance from the mirror as the object appears
to be (i.e., the image distance = the object distance)
because the light rays do not actually pass through the image. This
also implies that an image could not be focused on a screen placed at
the location where the image is. A little geometry Dealing with light in terms of rays is known as geometrical optics, for
good reason: there is a lot of geometry involved. It's relatively
straight-forward geometry, all based on similar triangles, but we
should review that for a plane mirror.
Consider an object placed a certain distance in front of a mirror,
as shown in the diagram. To figure out where the image of this object
is located, a ray diagram can be used. In a ray diagram, rays of light
are drawn from the object to the mirror, along with the rays that
reflect off the mirror. The image will be found where the reflected
rays intersect. Note that the reflected rays obey the law of
reflection. What you notice is that the reflected rays diverge from the
mirror; they must be extended back to find the place where they
intersect, and that's where the image is.
Analyzing this a little further, it's easy to see that the height of
the image is the same as the height of the object. Using the similar
triangles ABC and EDC, it can also be seen that the distance from the
object to the mirror is the same as the distance from the image to the
mirror.
Spherical mirrors Light reflecting off a flat mirror is one thing, but what happens
when light reflects off a curved surface? We'll take a look at what
happens when light reflects from a spherical mirror, because it turns
out that, using reasonable approximations, this analysis is fairly
straight-forward. The image you see is located either where the
reflected light converges, or where the reflected light appears to
diverge from. A spherical mirror is simply a piece cut out of a reflective
sphere. It has a center of curvature, C, which corresponds to the
center of the sphere it was cut from; a radius of curvature, R, which
corresponds to the radius of the sphere; and a focal point (the point
where parallel light rays are focused to) which is located half the
distance from the mirror to the center of curvature. The focal length,
f, is therefore: focal length of a spherical mirror : f = R / 2
This is actually an approximation. Parabolic mirrors are really the
only mirrors that focus parallel rays to a single focal point, but as
long as the rays don't get too far from the principal axis then the
equation above applies for spherical mirrors. The diagram shows the
principal axis, focal point (F), and center of curvature for both a
concave and convex spherical mirror.
Spherical mirrors are either concave (converging) mirrors or convex
(diverging) mirrors, depending on which side of the spherical surface
is reflective. If the inside surface is reflective, the mirror is
concave; if the outside is reflective, it's a convex mirror. Concave
mirrors can form either real or virtual images, depending on where the
object is relative to the focal point. A convex mirror can only form
virtual images. A real image is an image that the light rays from the
object actually pass through; a virtual image is formed because the
light rays can be extended back to meet at the image position, but they
don't actually go through the image position.
Ray diagrams To determine where the image is, it is very helpful to draw a ray
diagram. The image will be located at the place where the rays
intersect. You could just draw random rays from the object to the
mirror and follow the reflected rays, but there are three rays in
particular that are very easy to draw. Only two rays are necessary to locate the image on a ray diagram,
but it's useful to add the third as a check. The first is the parallel
ray; it is drawn from the tip of the object parallel to the principal
axis. It then reflects off the mirror and either passes through the
focal point, or can be extended back to pass through the focal point. The second ray is the chief ray. This is drawn from the tip of the
object to the mirror through the center of curvature. This ray will hit
the mirror at a 90° angle, reflecting back the way it came. The chief
and parallel rays meet at the tip of the image.
The third ray, the focal ray, is a mirror image of the parallel
ray. The focal ray is drawn from the tip of the object through (or
towards) the focal point, reflecting off the mirror parallel to the
principal axis. All three rays should meet at the same point.
A ray diagram for a concave mirror is shown above. This shows a few
different things. For this object, located beyond the center of
curvature from the mirror, the image lies between the focal point (F)
and the center of curvature. The image is inverted compared to the
object, and it is also a real image, because the light rays actually
pass through the point where the image is located.
With a concave mirror, any object beyond C will always have an
image that is real, inverted compared to the object, and between F and
C. You can always trade the object and image places (that just reverses
all the arrows on the ray diagram), so any object placed between F and
C will have an image that is real, inverted, and beyond C. What happens
when the object is between F and the mirror? You should draw the ray
diagram to convince yourself that the image will be behind the mirror,
making it a virtual image, and it will be upright compared to the
object.
A ray diagram for a convex mirror
What happens with a convex mirror? In this case the ray diagram looks like this:
As the ray diagram shows, the image for a convex mirror is virtual, and
upright compared to the object. A convex mirror is the kind of mirror
used for security in stores, and is also the kind of mirror used on the
passenger side of many cars ("Objects in mirror are closer than they
appear."). A convex mirror will reflect a set of parallel rays in all
directions; conversely, it will also take light from all directions and
reflect it in one direction, which is exactly how it's used in stores
and cars.
Drawing a ray diagram is a great way to get a rough idea of how big
the image of an object is, and where the image is located. We can also
calculate these things precisely, using something known as the mirror
equation. The textbook does a nice job of deriving this equation in
section 25.6, using the geometry of similar triangles.
Magnification
In most cases the height of the image differs from the height of the
object, meaning that the mirror has done some magnifying (or reducing).
The magnification, m, is defined as the ratio of the image height to
the object height, which is closely related to the ratio of the image
distance to the object distance:
A magnification of 1 (plus or minus) means that the image is the same
size as the object. If m has a magnitude greater than 1 the image is
larger than the object, and an m with a magnitude less than 1 means the
image is smaller than the object. If the magnification is positive, the
image is upright compared to the object; if m is negative, the image is
inverted compared to the object.
Sign conventions What does a positive or negative image height or image distance
mean? To figure out what the signs mean, take the side of the mirror
where the object is to be the positive side. Any distances measured on
that side are positive. Distances measured on the other side are
negative. f, the focal length, is positive for a concave mirror, and negative for a convex mirror. When the image distance is positive, the image is on the same side
of the mirror as the object, and it is real and inverted. When the
image distance is negative, the image is behind the mirror, so the
image is virtual and upright.
A negative m means that the image is inverted. Positive means an upright image.
Steps for analyzing mirror problems There are basically three steps to follow to analyze any mirror
problem, which generally means determining where the image of an object
is located, and determining what kind of image it is (real or virtual,
upright or inverted).
* Step 1 - Draw a ray diagram. The more careful you are in
constructing this, the better idea you'll have of where the image is.
* Step 2 - Apply the mirror equation to determine the image distance.
(Or to find the object distance, or the focal length, depending on what
is given.)
concave mirror with a focal length of 10.0 cm. Where is the image? How
tall is the image? What are the characteristics of the image?
The first step is to draw the ray diagram, which should tell you
that the image is real, inverted, smaller than the object, and between
the focal point and the center of curvature. The location of the image
can be found from the mirror equation:
which can be rearranged to:
The image distance is positive, meaning that it is on the same side
of the mirror as the object. This agrees with the ray diagram. Note
that we don't need to worry about converting distances to meters; just
make sure everything has the same units, and whatever unit goes into
the equation is what comes out.
Calculating the magnification gives:
Solving for the image height gives:
The negative sign for the magnification, and the image height, tells us that the image is inverted compared to the object.
To summarize, the image is real, inverted, 6.2 cm high, and 17.7 cm in front of the mirror.
Example 2 - a convex mirror The same Star Wars action figure, 8.0 cm tall, is placed 6.0 cm in
front of a convex mirror with a focal length of -12.0 cm. Where is the
image in this case, and what are the image characteristics? Again, the first step is to draw a ray diagram. This should tell
you that the image is located behind the mirror; that it is an upright,
virtual image; that it is a little smaller than the object; and that
the image is between the mirror and the focal point.
The second step is to confirm all those observations. The mirror equation, rearranged as in the first example, gives:
Solving for the magnification gives:
This gives an image height of 0.667 x 8 = 5.3 cm.
All of these results are consistent with the conclusions drawn from
the ray diagram. The image is 5.3 cm high, virtual, upright compared to
the object, and 4.0 cm behind the mirror.
Refraction When we talk about the speed of light, we're usually talking about the
speed of light in a vacuum, which is 3.00 x 108 m/s. When light travels
through something else, such as glass, diamond, or plastic, it travels
at a different speed. The speed of light in a given material is related
to a quantity called the index of refraction, n, which is defined as
the ratio of the speed of light in vacuum to the speed of light in the
medium: index of refraction : n = c / v
When light travels from one medium to another, the speed changes,
as does the wavelength. The index of refraction can also be stated in
terms of wavelength:
Although the speed changes and wavelength changes, the frequency of the
light will be constant. The frequency, wavelength, and speed are
related by:
The change in speed that occurs when light passes from one medium to
another is responsible for the bending of light, or refraction, that
takes place at an interface. If light is travelling from medium 1 into
medium 2, and angles are measured from the normal to the interface, the
angle of transmission of the light into the second medium is related to
the angle of incidence by Snell's law :
Subject:
Subject X2:
Rotation
Subject:
Subject X2:
Center of gravity; and Rotational Kinematics
10-25-99
Sections 7.8 - 8.3
Center of gravity
The center of gravity of an object is the point you can suspend the object from without there being any rotation because of the force of gravity, no matter how the object is oriented. If you suspend an object from any point, let it go and allow it to come to rest, the center of gravity will lie along a vertical line that passes through the point of suspension. Unless you've been exceedingly careful in balancing the object, the center of gravity will generally lie below the suspension point.
The center of gravity is an important point to know, because when you're solving problems involving large objects, or unusually-shaped objects, the weight can be considered to act at the center of gravity. In other words, for many purposes you can assume that object is a point with all its weight concentrated at one point, the center of gravity.
For any object, the x-position of the center of gravity can be found by considering the weights and x-positions of all the pieces making up the object:
A similar equation would allow you to find the y position of the center of gravity.
The center of mass of an object is generally the same as its center of gravity. Very large objects, large enough that the acceleration due to gravity varies in different parts of the object, are the only ones where the center of mass and center of gravity are in different places.
Neat facts about the center of gravity
Fact 1 - An object thrown through the air may spin and rotate, but its center of gravity will follow a smooth parabolic path, just like a ball.
Fact 2 - If you tilt an object, it will fall over only when the center of gravity lies outside the supporting base of the object.
Fact 3 - If you suspend an object so that its center of gravity lies below the point of suspension, it will be stable. It may oscillate, but it won't fall over.
Rotational variables
We'll now switch the focus from straight-line motion to rotational motion. If you can do one-dimensional motion problems, which involve straight-line motion, then you should be able to do rotational motion problems, because a circle is just a straight line rolled up. To solve rotational kinematics problems, a set of four equations is used; these are essentially the one-dimensional motion equations in disguise.
If you spin a wheel, and look at how fast a point on the wheel is spinning, the answer depends on how far away the point is from the center. Velocity, then, isn't the most convenient thing to use when you're dealing with rotation, and for the same reason neither is displacement, or acceleration; it is often more convenient to use their rotational equivalents. The equivalent variables for rotation are angular displacement (angle, for short); angular velocity , and angular acceleration . All the angular variables are related to the straight-line variables
by a factor of r, the distance from the center of rotation to the point
you're interested in.
Although points at different distances from the center of a rotating
wheel have different velocities, they all have the same angular
velocity, so they all go around the same number of revolutions per
minute, and the same number of radians per second. Angles (angular
displacements, that is) are generally measured in radians, which is the
most convenient unit to work with. A radian is an odd unit in physics,
however, because it is treated as being unitless, and is often put in
or taken out whenever it's convenient to do so.
It is helpful to recognize the parallel between straight-line
motion and rotational motion. Writing down the four rotational
kinematics equations reinforces that. Any equation dealing with
rotation can be found from its straight-line motion equivalent by
substituting the corresponding rotational variables.
The straight-line motion kinematics equations apply for
constant acceleration, so it follows that the rotational kinematics
equations apply when the angular acceleration is constant. The
equations should look familiar to you:
The equations are the same as the constant-acceleration equations for 1-D motion, substituting the rotational equivalents of the straight-line motion variables.
A rotational example
Consider an example of a spinning object to see how the rotational kinematics equations are applied. Imagine a ferris wheel that is rotating at the rate of 1 revolution every 8 seconds. The operator of the wheel decides to bring it to a stop, and puts on the brake; the brake produces a constant deceleration of 0.11 radians/s2.
(a) If your seat on the ferris wheel is 4.2 m from the center of the wheel, what is your speed when the wheel is turning at a constant rate, before the brake is applied?
(b) How long does it take before the ferris wheel comes to a stop?
(c) How many revolutions does the wheel make while it is coming to a stop?
(d) How far do you travel while the wheel is slowing down?
(a) The wheel is rotating at a rate of 1 revolution every 8 seconds, or 0.125 rev/s. This is the initial angular velocity. It is often most convenient to work with angular velocity in units of radians/s; doing the conversion gives:
Your speed is simply this angular velocity multiplied by your distance from the center of the wheel:
(b) We've calculated the initial angular velocity, the final angular
velocity is zero, and the angular acceleration is -0.11 rad/s2. This allows the stopping time to be found:
(c) To find the number of revolutions the wheel undergoes in this 7.14 seconds, one way to do it is to use the equation:
This can be converted to revolutions:
(d) To figure out the distance you traveled while the wheel was slowing
down. the angular displacement (in radians) can be converted to a
displacement by multiplying by r:
Tangential velocity; tangential acceleration
In uniform circular motion (motion in a circle at a constant speed), there is always a net acceleration (the centripetal acceleration) towards the center of the circular path. In non-uniform circular motion the speed is not constant, and there are two accelerations, the centripetal acceleration towards the center of the circle, and the tangential acceleration. The tangential acceleration is tangent to the circle, pointing in the direction the object is traveling if the object is speeding up, and the opposite way if the object is slowing down.
The two vector diagrams show an object undergoing uniform circular motion (constant angular velocity), and an object experiencing non-uniform circular motion (varying angular velocity). For uniform circular motion, the centripetal acceleration points towards the center of the circle, and the velocity points in the direction the object is traveling. This is tangent to the circular path, so we call it the tangential velocity. For non-uniform circular motion, the centripetal acceleration and tangential velocity are still there, and there is also a tangential acceleration in the direction the object is traveling. The net acceleration is the vector sum of the centripetal and tangential accelerations. Just as we separate everything out into x and y components when analyzing a projectile motion question, we can always separate things out into the tangential and radial (towards the center) directions in non-uniform circular motion.
Note that the centripetal acceleration is connected to the tangential velocity, through the usual v2 / r relationship, while the tangential acceleration is connected to any change in the tangential speed.
Rolling
When an object such as a wheel or a ball rolls, it does not slip where it makes contact with the ground. With a car or a bicycle tire, there is friction between the tire and the road, and if the tire is rolling then the frictional force is a static force of friction. This is because there is no slipping, so the point on the tire in contact with the road is instantaneously at rest.
This is somewhat counter-intuitive, but it comes about because the
velocity of each point on the tire is a sum of the linear velocity
associated with the car (or bike) moving, and the rotational velocity
associated with the tire rolling. For a point on the outside of the
tire, the rotational speed happens to be equal to the linear speed of
the car: this is because each time the tire makes a complete
revolution, the car will have traveled a distance equal to the
circumference of the tire, so the linear distance and the rotational
distance are the same for the same time interval. For a point on the
top of a tire, the two velocities are in the same direction, so the
total velocity at the top of a tire is twice the linear velocity of the
car; for a point at the bottom of a tire, the two velocities are in
opposite directions, so the total velocity is zero there.
Consider a bike on a flat road. You climb on, and start
pedaling, and the bike accelerates forward, with both tires rolling
along the road. As the bike accelerates, which way does friction act?
The answer depends on which tire you consider. Think about what would
happen if there was no friction between the tires and the road. When
you pedal, the chain causes the rear wheel to spin. With no friction,
the rear tire would spin on the road and the bike wouldn't move.
Friction opposes this tendency, so it points in the direction you're
accelerating on the bike; it's static friction, because the tire does
not slip, it rolls.
The front tire, on the other hand, is not being spun by the
chain, so with no friction it wouldn't spin at all. Friction is what
makes it spin, then, so it must point opposite to the way the bike is
accelerating, and, again, it's static friction because the tire does
not slip on the road.
Once you've accelerated the bike and you're going at a constant
speed, the frictional forces don't have to be as large. The friction on
the rear tire has to provide enough force to overcome the resistance
forces (rolling resistance, air resistance, friction in the wheel
bearings) tending to slow you and the bike down. The friction on the
front tire has to do even less, because all it has to do is keep the
front tire spinning at a constant rate.
Subject:
Subject X2:
Rotational Kinetic Energy and Angular Momentum
11-1-99
Sections 8.7 - 8.9
Rotational work and energy
Let's carry on madly working out equations applying to rotational motion by substituting the appropriate rotational variables into the straight-line motion equations. Work is force times displacement, so for rotation work must be torque times angular displacement:
A torque applied through a particular angular displacement does
work. If the object is rotating clockwise and the torque is a clockwise
torque, the work is positive; a counter-clockwise torque applied to a
clockwise rotating object does negative work.
What about kinetic energy? A spinning object has rotational kinetic energy:
A rolling object has both translational and rotational kinetic energy.
Angular momentum
To finish off our comparison of translational (straight-line) and rotational motion, let's consider the rotational equivalent of momentum, which is angular momentum. For straight-line motion, momentum is given by p = mv. Momentum is a vector, pointing in the same direction as the velocity. Angular momentum has the symbol L, and is given by the equation:
Angular momentum is also a vector, pointing in the direction of the angular velocity.
In the same way that linear momentum is always conserved when there is no net force acting, angular momentum is conserved when there is no net torque. If there is a net force, the momentum changes according to the impulse equation, and if there is a net torque the angular momentum changes according to a corresponding rotational impulse equation.
Angular momentum is proportional to the moment of inertia, which depends on not just the mass of a spinning object, but also on how that mass is distributed relative to the axis of rotation. This leads to some interesting effects, in terms of the conservation of angular momentum.
A good example is a spinning figure skater. Consider a figure skater who starts to spin with their arms extended. When the arms are pulled in close to the body, the skater spins faster because of conservation of angular momentum. Pulling the arms in close to the body lowers the moment of inertia of the skater, so the angular velocity must increase to keep the angular momentum constant.
Parallels between straight-line motion and rotational motion
Let's take a minute to summarize what we've learned about the parallels between straight-line motion and rotational motion. Essentially, any straight-line motion equation has a rotational equivalent that can be found by making the appropriate substitutions (I for m, torque for force, etc.).
Example - Falling down
You've climbed up to the top of a 7.5 m high telephone pole. Just as you reach the top, the pole breaks at the base. Are you better off letting go of the pole and falling straight down, or sitting on top of the pole and falling down to the ground on a circular path? Or does it make no difference?
The answer depends on the speed you have when you hit the ground. The speed in the first case, letting go of the pole and falling straight down, is easy to calculate using conservation of energy:
In the second case, also apply conservation of energy. If you have
negligible mass compared to the telephone pole, just work out the
angular velocity of the telephone pole when it hits the ground. In this
case we use rotational kinetic energy, and the height involved in the
potential energy is half the length of the pole (which we can call h),
because that's how much the center of gravity of the pole drops. So,
for the second case:
For a uniform rod rotating about one end, the moment of inertia is 1/3 mL2. Solving for the angular velocity when the pole hits the ground gives:
For you, at the end of the pole, the velocity is h times the angular velocity, so:
So, if you hang on to the pole you end up falling faster than if you'd fallen under the influence of gravity alone. This also means that the acceleration of the end of the pole, just before the pole hits the ground, is larger than g (1.5 times as big, in this case), which is interesting.
Which way do these angular variables point, anyway?
Displacement is a vector. Velocity is a vector. Acceleration is a vector. As you might expect, angular displacement, angular velocity, and angular acceleration are all vectors, too. But which way do they point? Every point on a rolling tire has the same angular velocity, and the only way to ensure that the direction of the angular velocity is the same for every point is to make the direction of the angular velocity perpendicular to the plane of the tire. To figure out which way it points, use your right hand. Stick your thumb out as if you're hitch-hiking, and curl your fingers in the direction of rotation. Your thumb points in the direction of the angular velocity.
If you look directly at something and it's spinning clockwise, the angular velocity is in the direction you're looking; if it goes counter-clockwise, the angular velocity points towards you. Apply the same thinking to angular displacements and angular accelerations.
Subject:
Subject X2:
Static Equilibrium
11-3-99
Sections 9.1 - 9.3
Objects in equilibrium
We've talked about equilibrium before, stating that an object is in equilibrium when it has no net force acting on it. This definition is incomplete, and it should be extended to include torque. An object at equilibrium has no net force acting on it, and has no net torque acting on it.
To see how the conditions are applied, let's work through a couple of examples.
Example 1
The first example will make use of the hinged rod supported by a rope, as discussed above. The rod has a mass of 1.4 kg, and there is an angle of 34° between the rope and the rod.
(a) What is the tension in the rope?
(b) What are the two components of the support force exerted by the hinge?
The free-body diagram is shown below, with the support force provided by the hinge split up into x and y components. If you aren't sure which way such forces go, simply guess, and if you guess wrong you'll just get a negative sign for that force.
Something we'll assume in this example is that the rod is uniform, so
the weight acts at the center of the rod (the center is the center of
mass, in other words). As usual, sum the forces in the x and y
directions:
There are too many unknowns here, and this is why summing the torques
can be so useful. To sum torques, choose a point to take torques
around; a sensible point to choose is one that one or two unknown
forces go through, because they will nt appear in the torque equation.
In this case, choosing the hinge as the point to take torques around
eliminated both components of the support force at the hinge. As with
forces, where you choose plus and minus directions, choose a positive
and negative direction for torques. In this case, let's make
counter-clockwise negative and clockwise positive.
This can be solved for T, the tension in the rope. Note that r, which represents the length of the rod, cancels out:
This can be substituted back into the force equations to find the components of the hinge force:
Example 2 - a step-ladder
A step-ladder stands on a frictionless horizontal surface, with just the crossbar keeping the ladder standing. The mass is 20 kg; what is the tension in the crossbar?
This is something of a tricky problem, because you have to draw the free-body diagram of the entire ladder to figure out the normal forces, and then draw the free-body diagram of one half of the ladder to complete the solution. This is also what makes it a good example to look at, however.
Consider first the free-body diagram of the entire ladder. The floor is
frictionless, so there are no horizontal forces exerted by the floor.
The ladder is uniform, so the weight acts at the center of mass, which
is halfway up the ladder and halfway between the two legs. Summing
forces in the y-direction gives:
One way to approach this is to say that the ladder is symmetric, and
there is no reason for the two normal forces to be different; each one
should be equal to half the weight of the ladder. If you don't like
this argument, simply take torques about one of the points where the
ladder touches the floor. This will give you an equation saying that
one normal force is equal to half the ladder's weight, so the other
normal force must be equal to half the weight, too. Either way, you
should be able to show that:
Now consider the free-body diagram of the left-hand side of the ladder.
I'll attach a 1/2 as a subscript to the mass, to remind us that the
mass of half the ladder is half the mass of the entire ladder.
Taking torques around the top of the ladder eliminates the unknown
contact force (F) coming from the other half of the ladder, and gives
(this time taking clockwise to be positive):
This can be solved to find the tension in the crossbar:
Subject:
Subject X2:
Torque and Rotational Inertia
10-27-99
Sections 8.4 - 8.6
Torque
We've looked at the rotational equivalents of displacement, velocity, and acceleration; now we'll extend the parallel between straight-line motion and rotational motion by investigating the rotational equivalent of force, which is torque.
To get something to move in a straight-line, or to deflect an object traveling in a straight line, it is necessary to apply a force. Similarly, to start something spinning, or to alter the rotation of a spinning object, a torque must be applied.
A torque is a force exerted at a distance from the axis of rotation; the easiest way to think of torque is to consider a door. When you open a door, where do you push? If you exert a force at the hinge, the door will not move; the easiest way to open a door is to exert a force on the side of the door opposite the hinge, and to push or pull with a force perpendicular to the door. This maximizes the torque you exert.
I will state the equation for torque in a slightly different way than
the book does. Note that the symbol for torque is the Greek letter tau.
Torque is the product of the distance from the point of rotation to
where the force is applied x the force x the sine of the angle between
the line you measure distance along and the line of the force:
http://buphy.bu.edu/~duffy/PY105/16c.GIF
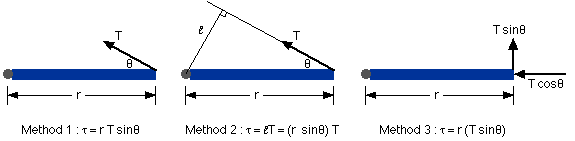{kind=link}
In a given situation, there are usually three ways to determine the
torque arising from a particular force. Consider the example of the
torque exerted by a rope tied to the end of a hinged rod, as shown in
the diagram.
The first thing to notice is that the torque is a counter-clockwise
torque, as it tends to make the rod spin in a counter-clockwise
direction. The rod does not spin because the rope's torque is balanced
by a clockwise torque coming from the weight of the rod itself. We'll
look at that in more detail later; for now, consider just the torque
exerted by the rope.
There are three equivalent ways to determine this torque, as shown in the diagram below.
Method 1 - In method one, simply measure r from the hinge along the
rod to where the force is applied, multiply by the force, and then
multiply by the sine of the angle between the rod (the line you measure
r along) and the force.
Method 2 - For method two, set up a right-angled triangle, so
that there is a 90° angle between the line you measure the distance
along and the line of the force. This is the way the textbook does it;
done in this way, the line you measure distance along is called the
lever arm. If we give the lever arm the symbol l, from the right-angled
triangle it is clear that
Using this to calculate the torque gives:
Method 3 - In this method, split the force into components,
perpendicular to the rod and parallel to the rod. The component
parallel to the rod is along a line passing through the hinge, so it is
not trying to make the rod spin clockwise or counter-clockwise; it
produces zero torque. The perpendicular component (F sinq) gives plenty
of torque, the size of which is given by:
Any force that is along a line which passes through the axis of rotation produces no torque. Note that torque is a vector quantity, and, like angular displacement, angular velocity, and angular acceleration, is in a direction perpendicular to the plane of rotation. The same right-hand rule used for angular velocity, etc., can be applied to torque; for convenience, though, we'll probably just talk about the directions as clockwise and counter-clockwise.
oment of inertia
We've looked at the rotational equivalents of several straight-line motion variables, so let's extend the parallel a little more by discussing the rotational equivalent of mass, which is something called the moment of inertia.
Mass is a measure of how difficult it is to get something to move in a straight line, or to change an object's straight-line motion. The more mass something has, the harder it is to start it moving, or to stop it once it starts. Similarly, the moment of inertia of an object is a measure of how difficult it is to start it spinning, or to alter an object's spinning motion. The moment of inertia depends on the mass of an object, but it also depends on how that mass is distributed relative to the axis of rotation: an object where the mass is concentrated close to the axis of rotation is easier to spin than an object of identical mass with the mass concentrated far from the axis of rotation.
The moment of inertia of an object depends on where the axis of rotation is. The moment of inertia can be found by breaking up the object into little pieces, multiplying the mass of each little piece by the square of the distance it is from the axis of rotation, and adding all these products up:
Fortunately, for common objects rotating about typical axes of rotation, these sums have been worked out, so we don't have to do it ourselves. A table of some of these moments of inertia can be found on page 223 in the textbook. Note that for an object where the mass is all concentrated at the same distance from the axis of rotation, such as a small ball being swung in a circle on a string, the moment of inertia is simply MR2 . For objects where the mass is distributed at different distances from the axis of rotation, there is some multiplying factor in front of the MR2.
Newton's second law for rotation
You can figure out the rotational equivalent of any straight-line motion equation by substituting the corresponding rotational variables for the straight-line motion variables (angular displacement for displacement, angular velocity for velocity, angular acceleration for acceleration, torque for force, and moment of inertia for mass). Try this for Newton's second law:
Replace force by torque, m by I, and acceleration by angular acceleration and you get:
Example - two masses and a pulley
We've dealt with this kind of problem before, but we've never accounted for the pulley. Now we will. There are two masses, one sitting on a table, attached to the second mass which is hanging down over a pulley. When you let the system go, the hanging mass is pulled down by gravity, accelerating the mass sitting on the table. When you looked at this situation previously, you treated the pulley as being massless and frictionless. We'll still treat it as frictionless, but now let's work with a real pulley.
A 111 N block sits on a table; the coefficient of kinetic friction between the block and the table is 0.300. This block is attached to a 258 N block by a rope that passes over a pulley; the second block hangs down below the pulley. The pulley is a solid disk with a mass of 1.25 kg and an unknown radius. The rope passes over the pulley on the outer edge. What is the acceleration of the blocks?
As usual, the first place to start is with a free-body diagram of each
block and the pulley. Note that because the pulley has an angular
acceleration, the tensions in the two parts of the rope have to be
different, so there are different tension forces acting on the two
blocks.
Then, as usual, the next step is to apply Newton's second law and write
down the force and/or torque equations. For block 1, the force
equations look like this:
For block 2, the force equation is:
The pulley is rotating, not moving in a straight line, so do the sum of the torques:
Just a quick note about positive directions...you know that the
system will accelerate so that block 2 accelerates down, so make down
the positive direction for block 2. Block 1 accelerates right, so make
right the positive direction for block 1, and for the pulley, which
will have a clockwise angular acceleration, make clockwise the positive
direction.
We have three equations, with a bunch of unknowns, the two
tensions, the moment of inertia, the acceleration, and the angular
acceleration. The moment of inertia is easy to calculate, because we
know what the pulley looks like (a solid disk) and we have the mass and
radius:
The next step is to make the connection between the angular
acceleration of the pulley and the acceleration of the two blocks.
Assume the rope does not slip on the pulley, so a point on the pulley
which is in contact with the rope has a tangential acceleration equal
to the acceleration of any point on the rope, which is equal to the
acceleration of the blocks. Recalling the relationship between the
angular acceleration and the tangential acceleration gives:
Plugging this, and the expression for the moment of inertia, into the torque equation gives:
All the factors of r, the radius of the pulley, cancel out, leaving:
Substituting the expressions derived above for the two tensions gives:
This can be solved for the acceleration:
Accounting for the mass of the pulley just gives an extra term in the
denominator. Plugging in the numbers and solving for the acceleration
gives:
Neglecting the mass of the pulley gives a = 5.97 m/s2.
Subject:
Subject X2:
Sound and Waves
Subject:
Subject X2:
Diffraction
3-5-99
Section 11.13
The interference of two waves of the same frequency
When two (or more) waves of the same frequency interfere, a variety of different results can be obtained. Consider first the special case of two sources separated by a small distance d, sending out waves of the same frequency. The sources are in phase with each other. For a particular separation and wavelength, the pattern is as shown in the diagram, with constructive interference taking place at certain angles and destructive interference taking place at other angles.
When the sources send out waves in phase, constructive interference
will occur at a particular point if the path lengths from the two
sources to that point differ by an integral number of wavelengths.
Destructive interference occurs at a particular point if the path
lengths from the two sources to that point differ by an integral number
of wavelengths + 1/2 a wavelength.
Diffraction
Diffraction is the bending of waves that takes place when the wave encounters openings or obstacles. The most interesting cases (i.e., the ones with interesting patterns of maxima and minima) are those in which the size of the openings or obstacles is about the same as the wavelength of the wave.
Interference, both constructive and destructive, is important to understanding why diffraction occurs. If the opening is divided into many small pieces, each piece can be thought of as an emitter of the wave. The waves from each piece of the opening are sent out in phase with each other; at some places they will interfere constructively, and at others they will interfere destructively.
Consider a point that is half a wavelength further from the center of the opening than from one side of the opening. This is the condition for destructive interference: the wave from the side of the opening will interfere destructively with the wave from the center of the opening. Similarly, the wave from the part of the opening next to the side will interfer destructively with the part of the opening next to the center, and so on - the waves from one half of the opening completely cancel the waves from the other half. It turns out that the points where this destructive interference occurs are all along one line, at an angle (measured from a line perpendicular to the opening) given by:
If D, the width of the opening, is less than the wavelength than there
is no place where the interference is completely destructive. If D is
greater than the wavelength there is at least one angle where
destructive interference occurs; the diffraction patterns in such cases
are similar to the interference patterns produces by two sources close
together.
Subject:
Subject X2:
Interference of Waves
3-3-99
Sections 11.11 - 11.12
Interference
Interference is what happens when two or more waves come together. Depending on how the peaks and troughs of the waves are matched up, the waves might add together or they can partially or even completely cancel each other. We'll discuss interference as it applies to sound waves, but it applies to other waves as well.
Linear superposition
The principle of linear superposition - when two or more waves come together, the result is the sum of the individual waves.
The principle of linear superposition applies to any number of waves, but to simplify matters just consider what happens when two waves come together. For example, this could be sound reaching you simultaneously from two different sources, or two pulses traveling towards each other along a string. When the waves come together, what happens? The result is that the waves are superimposed: they add together, with the amplitude at any point being the addition of the amplitudes of the individual waves at that point.
Although the waves interfere with each other when they meet, they continue traveling as if they had never encountered each other. When the waves move away from the point where they came together, in other words, their form and motion is the same as it was before they came together.
Constructive interference
Constructive interference occurs whenever waves come together so that they are in phase with each other. This means that their oscillations at a given point are in the same direction, the resulting amplitude at that point being much larger than the amplitude of an individual wave. For two waves of equal amplitude interfering constructively, the resulting amplitude is twice as large as the amplitude of an individual wave. For 100 waves of the same amplitude interfering constructively, the resulting amplitude is 100 times larger than the amplitude of an individual wave. Constructive interference, then, can produce a significant increase in amplitude.
The following diagram shows two pulses coming together, interfering constructively, and then continuing to travel as if they'd never encountered each other.
Another way to think of constructive interference is in terms of peaks and troughs; when waves are interfering constructively, all the peaks line up with the peaks and the troughs line up with the troughs.
Destructive interference
Destructive interference occurs when waves come together in such a way that they completely cancel each other out. When two waves interfere destructively, they must have the same amplitude in opposite directions. When there are more than two waves interfering the situation is a little more complicated; the net result, though, is that they all combine in some way to produce zero amplitude. In general, whenever a number of waves come together the interference will not be completely constructive or completely destructive, but somewhere in between. It usually requires just the right conditions to get interference that is completely constructive or completely destructive.
The following diagram shows two pulses interfering destructively. Again, they move away from the point where they combine as if they never met each other.
Reflection of waves
This applies to both pulses and periodic waves, although it's easier to see for pulses. Consider what happens when a pulse reaches the end of its rope, so to speak. The wave will be reflected back along the rope.
If the end is fixed, the pulse will be reflected upside down (also known as a 180° phase shift).
If the end is free, the pulse comes back the same way it went out (so no phase change).
If the pulse is traveling along one rope tied to another rope, of different density, some of the energy is transmitted into the second rope and some comes back. For a pulse going from a light rope to a heavy rope, the reflection occurs as if the end is fixed. From heavy to light, the reflection is as if the end is free.
Standing waves
Moving on towards musical instruments, consider a wave travelling along a string that is fixed at one end. When the wave reaches the end, it will be reflected back, and because the end was fixed the reflection will be reversed from the original wave (also known as a 180° phase change). The reflected wave will interfere with the part of the wave still moving towards the fixed end. Typically, the interference will be neither completely constructive nor completely destructive, and nothing much useful occurs. In special cases, however, when the wavelength is matched to the length of the string, the result can be very useful indeed.
Consider one of these special cases, when the length of the string is equal to half the wavelength of the wave.
time to produce half a wavelength is t = T / 2 = 1 / 2f
in this time the wave travels at a speed v a distance L, so t = L / v
combining these gives L / v = 1 / 2f, so f = v / 2L
This frequency is known as the first harmonic, or the fundamental frequency, of the string. The second harmonic will be twice this frequency, the third three times the frequency, etc. The different harmonics are those that will occur, with various amplitudes, in stringed instruments.
String instruments and transverse standing waves
In general, the special cases (the frequencies at which standing waves occur) are given by:
The first three harmonics are shown in the following diagram:
When you pluck a guitar string, for example, waves at all sorts of
frequencies will bounce back and forth along the string. However, the
waves that are NOT at the harmonic frequencies will have reflections
that do NOT constructively interfere, so you won't hear those
frequencies. On the other hand, waves at the harmonic frequencies will
constructively interfere, and the musical tone generated by plucking
the string will be a combination of the different harmonics.
Example - a particular string has a length of 63.0 cm, a mass
of 30 g, and has a tension of 87.0 N. What is the fundamental frequency
of this string? What is the frequency of the fifth harmonic?
The first step is to calculate the speed of the wave (F is the tension):
The fundamental frequency is then found from the equation:
So the fundamental frequency is 42.74 / (2 x 0.63) = 33.9 Hz.
The second harmonic is double that frequency, and so on, so the fifth harmonic is at a frequency of 5 x 33.9 = 169.5 Hz.
Subject:
Subject X2:
Musical Instruments
The physics of music
3-15-00
Sections 12.5 - 12.7
The physics behind musical instruments is beautifully simple. The sounds made by musical instruments are possible because of standing waves, which come from the constructive interference between waves traveling in both directions along a string or a tube..
How a guitar works
A typical guitar has six strings. These are all of the same length, and all under about the same tension, so why do they put out sound of different frequency? If you look at the different strings, they're of different sizes, so the mass/length of all the strings is different. The one at the bottom has the smallest mass/length, so it has the highest frequency. The strings increase in mass/length as you move up, so the top string, the heaviest, has the lowest frequency.
Tuning a guitar simply means setting the fundamental frequency of each string to the correct value. This is done by adjusting the tension in each string. If the tension is increased, the fundamental frequency increases; if the tension is reduced the frequency will decrease.
To obtain different notes (i.e., different frequencies) from a string, the string's length is changed by pressing the string down until it touches a fret. This shortens a string, and the frequency will be increased.
Wind instruments and longitudinal standing waves
Pipes work in a similar way as strings, so we can analyze everything from organ pipes to flutes to trumpets. The big difference between pipes and strings is that while we consider strings to be fixed at both ends, the tube is either free at both ends (if it is open at both ends) or is free at one end and fixed at the other (if the tube is closed at one end). In these cases the harmonic frequencies are given by:
A pipe organ has an array of different pipes of varying lengths,
some open-ended and some closed at one end. Each pipe corresponds to a
different fundamental frequency. For an instrument like a flute, on the
other hand, there is only a single pipe. Holes can be opened along the
flute to reduce the effective length, thereby increasing the frequency.
In a trumpet, valves are used to make the air travel through different
sections of the trumpet, changing its effective length; with a
trombone, the change in length is a little more obvious.
Example : A tube open at one end has a length of 25.0 cm. The
temperature is 20°C. What is the fundamental frequency of this tube?
What is the frequency of the fifth harmonic?
If we blow through the tube, it will make a musical tone, and
that's what we're talking about here. The velocity involved in the
frequency equation is therefore the speed of sound, which is 343 m/s at
20°C. The fundamental frequency is then:
So the fundamental is 343 / ( 4 x 0.25) = 343 Hz.
A tube like this, closed at one end, only has odd harmonics (n =
1, 3, 5, etc.). The fifth harmonic is five times the fundamental, and
it's also given by:
So the fifth harmonic is 1715 Hz.
Beats
When two waves which are of slightly different frequency interfere, the interference cycles from constructive to destructive and back again. This is known as beats; two sound waves producing beats will generate a sound with an intensity that continually cycles from loud to soft and back again. The frequency of the sound you hear will be the average of the frequency of the two waves; the intensity will vary with a frequency (known as the beat frequency) that is the difference between the frequencies of the two waves.
Subject:
Subject X2:
Sound
3-15-99
Sections 12.1 - 12.4
The speed of sound
A sound wave propagates by alternately compressing and expanding the medium. The speed of sound thus depends on how easily a medium can be compressed (or, equivalently, expanded). Sound travels fastest in media which are hard to compress (like different metals) because if one particle moves in response to a pressure wave, its neighbor will respond quickly. In easily-compressible media, such as most gases, the speed of sound is slower because particles respond more slowly to motion of neighboring particles.
The compressibility of a material is measured by the bulk modulus, discussed in chapter 9. The speed of sound also depends on density, and is given by:
For an ideal gas, it turns out that the speed of sound is given by:
m is the mass of one molecule.
In air at 0 °C, the speed of sound is 331 m/s. It increases with temperature. In liquids, the speed of sound is more like 1000 m/s, and in a typical solid more like 5000 m/s.
Intensity
Just as the total energy in an oscillating spring is proportional to the square of the amplitude of the oscillation, the energy in a sound wave is proportional to the square of the amplitude of the pressure difference. A sound wave is usually characterized by the power (energy / second) it carries: the intensity is the power (P) divided by the area (A) the sound power passes through:
The human ear can detect sound of very low intensity. The smallest
detectable sound intensity, known as the threshold of hearing, is about
1 x 10-12 W / m2. Sound that is 1 W / m2 is intense enough to damage the ear.
If sound moves away from a source uniformly in all directions,
the intensity decreases the further away from the source you are. In
fact, the intensity is inversely proportional to the square of the
distance from the source. At a distance r away from a source sending
out sound with a power P, the sound passes through a sphere with a
surface area equal to . The intensity is thus:
This dependence on 1/r2 applies to anything emitted uniformly in all directions (sound, light, etc.).
Decibels
The human ear has an incredibly large range, being able to detect sound intensities from 1 x 10-12 W / m2 to 1 W / m2. A more convenient way to measure the loudness of sound is in decibels (dB); in decibels, the range of human hearing goes from 0 dB to 120 dB. The ear responds to the loudness of sound logarithmically, so the decibel scale is a logarithmic scale:
On the decibel scale, doubling the intensity corresponds to an increase of 3 dB. This does not correspond to a perceived doubling of loudness, however. We perceive loudness to be doubled when the intensity increases by a factor of 10! This corresponds to a 10 dB increase. A change by 1 dB is about the smallest change a human being can detect.
An example using decibels
A particular sound has an intensity of 1 x 10-6 W / m2 . What is this in decibels? If the intensity is increased by 15 dB, what is the new intensity in W / m2?
The intensity in dB can be found by simply applying the equation:
If this is increased to 75 dB, the new intensity can be found like this:
Therefore, I / Io = the inverse log of 7.5. Taking the inverse log of 7.5 means simply raising 10 to the 7.5 power, so:
This is 31.6 times as much as the original intensity.
The ear
The decibel scale is used because it closely corresponds to how we perceive the loudness of sounds. The human ear is really quite an amazing detector of sound, and it's worth spending some time learning how it works.
The ear is split into three sections, the outer ear, the middle ear, and the inner ear. The outer ear acts much like a funnel, collecting the sound and transferring it inside the head down a passage that's about 3 cm long, ending at the ear drum.
The ear drum separates the outer ear from the middle ear, and, much like the skin on a drum, it is a thin membrane that vibrates in response to a sound wave. The middle ear is connected to the mouth via the eustachian tubes to ensure that the inside of the eardrum is maintained at atmospheric pressure. This is necessary for the drum to be able to respond to the small variations in pressure from atmospheric pressure that make up the sound wave.
In the middle ear are three small bones, called the hammer, anvil, and stirrup because of their shapes. These transfer the sound wave from the ear drum to the inner ear. Similar to a hydraulic lift, the pressure is transferred from a relatively large area (the eardrum) to a smaller area (the window to the inner ear). By Pascal's principle (see the section on fluids), the pressure is constant. The force is smaller at the small-area inner ear, but the work done at each end is equal, so the inner ear experiences a vibration with a much larger amplitude than that at the ear drum. The bones, in effect, act as an audio amplifier.
The eardrum and the window to the inner ear have different acoustic properties. If they were directly connected together some energy would be reflected back. The three bones in the middle ear are designed to transfer sound energy from the eardrum to the inner ear without any energy lost to reflections. The technical physics term for this is "impedance match": any time energy is transferred from one system to another without any reflected energy, the impedances are matched at the transfer point...in this case, the bones provide the impedance matching. The bottom line is that they will amplify the sound level without losing any sound energy.
The inner ear contains a fluid-filled tube, the cochlea. The cochlea is coiled like a snail, is about 3 mm in diameter, and is divided along its length by the basilar membrane. It also contains a set of hair cells that convert the sound wave into electrical pulses; these are transferred along nerves to the brain, to be interpreted as sound. When a sound signal enters the inner ear, a small movement of the basilar membrane or the fluid in the cochlea results in the rubbing of another membrane across the hair cells. The relatively long hairs provide another level of amplification, in the sense that a small force applied at the ends is converted into a relatively large torque.
To summarize, then, the outer ear collects sound and transfers it to the middle ear; the middle ear amplifies the sound and passes it to the inner ear; and the inner ear converts the sound into electrical signals to be sent to the brain.
The range of human hearing is quite large, both in terms of sound intensity and sound frequency. Humans can hear sounds between about 20 Hz and 20000 Hz; music and speech typically covers the range from 100 Hz to 3000 Hz. The ear is most sensitive to sound of about 3000 Hz, as the following graph shows:
Subject:
Subject X2:
The Doppler Effect
3-17-00
Sections 12.8 - 12.10
The Doppler effect
The Doppler effect describes the shift in the frequency of a wave sound when the wave source and/or the receiver is moving. We'll discuss it as it pertains to sound waves, but the Doppler effect applies to any kind of wave. As with ultrasound, the Doppler effect has a variety of applications, ranging from medicine (with sound) to police radar and astronomy (with electromagnetic waves).
The Doppler effect is something you're familiar with. If you hear an emergency vehicle with its siren on, you notice an abrupt change in the frequency of the siren when it goes past you. If you are standing still when the vehicle is coming toward you, the frequency is higher than it would be if the vehicle was stationary; when the vehicle moves away from you, the frequency is lower. A similar effect occurs if the sound source is stationary and you move toward it or away from it.
At first glance you might think that there should be no difference between what happens when you move at a particular speed toward a source and when the source moves at the same speed toward you. As long as the speed is much less than the speed of sound, there is hardly any difference between these two cases. The higher the speeds involved, however, the greater the difference.
To convince yourself that it does make a difference which is moving, the source or the observer, consider what happens when v is equal to the speed of sound. When the receiver moves at the speed of sound toward the source, twice as many waves are intercepted as by a stationary observer, and the frequency is doubled. The waves are still nicely separated, however. On the other hand, when the source moves toward the receiver at the speed of sound, the sound waves pile up on top of each other (resulting in a sonic boom), and the frequency is effectively infinite.
Consider first the case of a stationary source, and an observer (you, for example) moving toward the source. As shown in the diagram, the waves are emitted by the source uniformly.
If the observer is stationary, the frequency received by the observer is the frequency emitted by the source:
If the observer moves toward the source at a speed vo, more waves are
intercepted per second and the frequency received by the observer goes
up. Effectively, the observer's motion shifts the speed at which the
waves are received; it's basically a relative velocity problem. The
observed frequency is given by:
If the observer is stationary but the source moves toward the observer
at a speed vs, the observer still intercepts more waves per second and
the frequency goes up.
This time it is the wavelength of the wave received by the observer
that is effectively shifted by the motion, rather than the speed. The
effective wavelength is simply:
The frequency of waves received by the observer is then:
In the most general case, in which both the source and receiver are moving, the observed frequency is:
Sonic booms occur when the source travels faster than the speed of
sound. If the source is traveling at the speed of sound, the waves pile
up and move along with the source; when the source travels faster than
sound, a shock wave (also known as a sonic boom) occurs as waves pile
up. The angle at which the shock wave moves away from the path of the
source depends on the speed of the source relative to the speed of
sound.
A Doppler example
A source is traveling east at 10 m/s toward you; you're traveling at 2 m/s east. It's 20°C. When the source is not moving it emits sound of frequency 3000 Hz. What frequency do you hear?
Sound in air at 20°C travels at 343 m/s. Plugging all of this information into the equation, and making sure we get the signs right, gives:
Subject:
Subject X2:
Waves
3-1-99
Sections 11.7 - 11.9
We'll shift gears now, spending some time on waves.
Types of waves
A wave is a disturbance that transfers energy from one place to another without requiring any net flow of mass. For now, we'll focus on mechanical waves, requiring a medium in which to travel. Light, and other electromagnetic waves, do not require a medium; we'll deal with those later in the semester.
Waves can be broadly separated into pulses and periodic waves. A pulse is a single disturbance while a periodic wave is a continually oscillating motion. There is a close connection between simple harmonic motion and periodic waves; in most periodic waves, the particles in the medium experience simple harmonic motion.
Waves can also be separated into transverse and longitudinal waves. In a transverse wave, the motion of the particles of the medium is at right angles (i.e., transverse) to the direction the wave moves. In a longitudinal wave, such as a sound wave, the particles oscillate along the direction of motion of the wave.
Surface waves, such as water waves, are generally a combination of a transverse and a longitudinal wave. The particles on the surface of the water travel in circular paths as a wave moves across the surface.
Periodic waves
A periodic wave generally follows a sine wave pattern, as shown in the diagram.
A number of parameters can be defined to describe a periodic wave:
wavelength - the length of one cycle
amplitude - the maximum distance a particle gets from its undisturbed position
period (T) - time required for one cycle
frequency (f = 1/T) - number of cycles in a certain time, usually in 1 second.
speed - this is given by v = frequency x wavelength
Note that the frequency of the wave is set by whatever is producing
the disturbance, while the speed is determined by the properties of the
medium. The wavelength can then be found from the equation above.
A sine wave oscillation is also followed by each particle in the medium, as the following diagram shows:
There is a big difference between what the wave does and what the particles in the medium do. As the wave travels through the medium, the particles of the medium oscillate in response to the wave. In a uniform medium, the wave travels at constant speed; each particle, however, has a speed that is constantly changing. The maximum speed of a particle is determined by the wave amplitude and frequency.
The speed of a wave
The speed of a wave traveling through a medium depends on properties of the medium. For a wave to propagate, each disturbed particle must exert a force on its neighbor. The wave speed is essentially the speed at which the neighboring particle responds to this force; that response time is determined by the mass of the particle and the size of the force exerted. For a transverse wave on a rope or stretched spring, the wave speed is determined by the tension (F) and the mass per unit length:
For a sound wave, the speed is determined by either Young's modulus or
the bulk modulus (discussed in chapter 9) and the density:
Subject:
Subject X2: